 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability-Aware Parking Selection
Jan 02, 2026Current parking navigation systems often underestimate total travel time by failing to account for the time spent searching for a parking space, which significantly affects user experience, mode choice, congestion, and emissions. To address this issue, this paper introduces the probability-aware parking selection problem, which aims to direct drivers to the best parking location rather than straight to their destination. An adaptable dynamic programming framework is proposed for decision-making based on probabilistic information about parking availability at the parking lot level. Closed-form analysis determines when it is optimal to target a specific parking lot or explore alternatives, as well as the expected time cost. Sensitivity analysis and three illustrative cases are examined, demonstrating the model's ability to account for the dynamic nature of parking availability. Acknowledging the financial costs of permanent sensing infrastructure, the paper provides analytical and empirical assessments of errors incurred when leveraging stochastic observations to estimate parking availability. Experiments with real-world data from the US city of Seattle indicate this approach's viability, with mean absolute error decreasing from 7% to below 2% as observation frequency grows. In data-based simulations, probability-aware strategies demonstrate time savings up to 66% relative to probability-unaware baselines, yet still take up to 123% longer than direct-to-destination estimates.
A Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
Backdoors in DRL: Four Environments Focusing on In-distribution Triggers
May 22, 2025



Backdoor attacks, or trojans, pose a security risk by concealing undesirable behavior in deep neural network models. Open-source neural networks are downloaded from the internet daily, possibly containing backdoors, and third-party model developers are common. To advance research on backdoor attack mitigation, we develop several trojans for deep reinforcement learning (DRL) agents. We focus on in-distribution triggers, which occur within the agent's natural data distribution, since they pose a more significant security threat than out-of-distribution triggers due to their ease of activation by the attacker during model deployment. We implement backdoor attacks in four reinforcement learning (RL) environments: LavaWorld, Randomized LavaWorld, Colorful Memory, and Modified Safety Gymnasium. We train various models, both clean and backdoored, to characterize these attacks. We find that in-distribution triggers can require additional effort to implement and be more challenging for models to learn, but are nevertheless viable threats in DRL even using basic data poisoning attacks.
IntersectionZoo: Eco-driving for Benchmarking Multi-Agent Contextual Reinforcement Learning
Oct 19, 2024Despite the popularity of multi-agent reinforcement learning (RL) in simulated and two-player applications, its success in messy real-world applications has been limited. A key challenge lies in its generalizability across problem variations, a common necessity for many real-world problems. Contextual reinforcement learning (CRL) formalizes learning policies that generalize across problem variations. However, the lack of standardized benchmarks for multi-agent CRL has hindered progress in the field. Such benchmarks are desired to be based on real-world applications to naturally capture the many open challenges of real-world problems that affect generalization. To bridge this gap, we propose IntersectionZoo, a comprehensive benchmark suite for multi-agent CRL through the real-world application of cooperative eco-driving in urban road networks. The task of cooperative eco-driving is to control a fleet of vehicles to reduce fleet-level vehicular emissions. By grounding IntersectionZoo in a real-world application, we naturally capture real-world problem characteristics, such as partial observability and multiple competing objectives. IntersectionZoo is built on data-informed simulations of 16,334 signalized intersections derived from 10 major US cities, modeled in an open-source industry-grade microscopic traffic simulator. By modeling factors affecting vehicular exhaust emissions (e.g., temperature, road conditions, travel demand), IntersectionZoo provides one million data-driven traffic scenarios. Using these traffic scenarios, we benchmark popular multi-agent RL and human-like driving algorithms and demonstrate that the popular multi-agent RL algorithms struggle to generalize in CRL settings.
A Data-Informed Analysis of Scalable Supervision for Safety in Autonomous Vehicle Fleets
Sep 14, 2024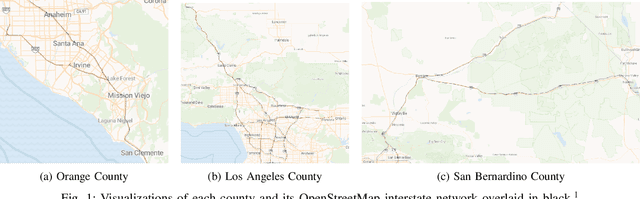
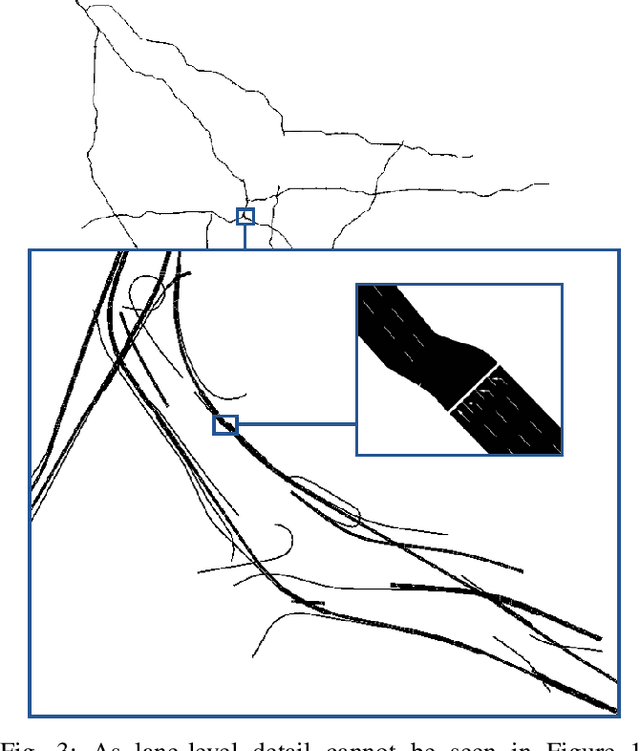
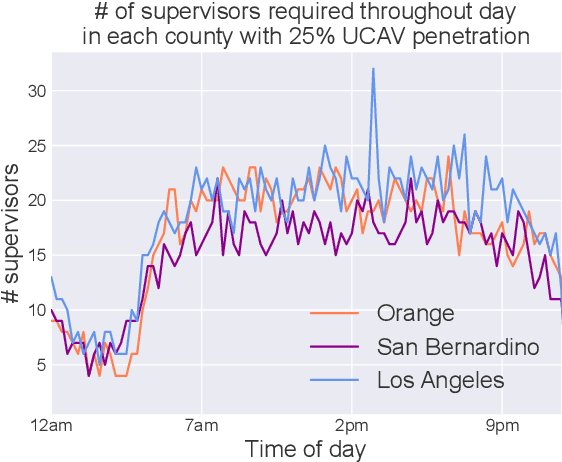
Autonomous driving is a highly anticipated approach toward eliminating roadway fatalities. At the same time, the bar for safety is both high and costly to verify. This work considers the role of remotely-located human operators supervising a fleet of autonomous vehicles (AVs) for safety. Such a 'scalable supervision' concept was previously proposed to bridge the gap between still-maturing autonomy technology and the pressure to begin commercial offerings of autonomous driving. The present article proposes DISCES, a framework for Data-Informed Safety-Critical Event Simulation, to investigate the practicality of this concept from a dynamic network loading standpoint. With a focus on the safety-critical context of AVs merging into mixed-autonomy traffic, vehicular arrival processes at 1,097 highway merge points are modeled using microscopic traffic reconstruction with historical data from interstates across three California counties. Combined with a queuing theoretic model, these results characterize the dynamic supervision requirements and thereby scalability of the teleoperation approach. Across all scenarios we find reductions in operator requirements greater than 99% as compared to in-vehicle supervisors for the time period analyzed. The work also demonstrates two methods for reducing these empirical supervision requirements: (i) the use of cooperative connected AVs -- which are shown to produce an average 3.67 orders-of-magnitude system reliability improvement across the scenarios studied -- and (ii) aggregation across larger regions.
Mitigating Metropolitan Carbon Emissions with Dynamic Eco-driving at Scale
Aug 10, 2024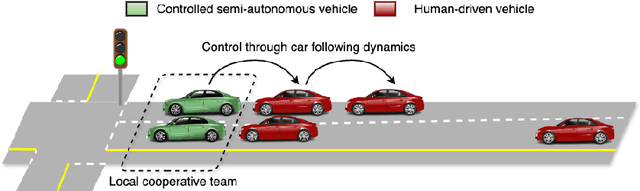
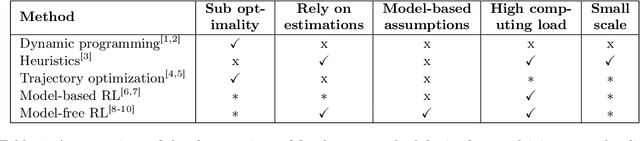
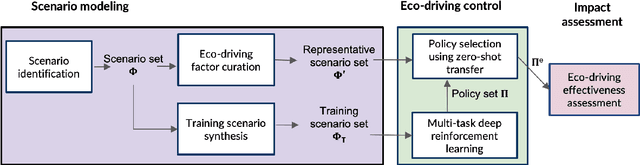
The sheer scale and diversity of transportation make it a formidable sector to decarbonize. Here, we consider an emerging opportunity to reduce carbon emissions: the growing adoption of semi-autonomous vehicles, which can be programmed to mitigate stop-and-go traffic through intelligent speed commands and, thus, reduce emissions. But would such dynamic eco-driving move the needle on climate change? A comprehensive impact analysis has been out of reach due to the vast array of traffic scenarios and the complexity of vehicle emissions. We address this challenge with large-scale scenario modeling efforts and by using multi-task deep reinforcement learning with a carefully designed network decomposition strategy. We perform an in-depth prospective impact assessment of dynamic eco-driving at 6,011 signalized intersections across three major US metropolitan cities, simulating a million traffic scenarios. Overall, we find that vehicle trajectories optimized for emissions can cut city-wide intersection carbon emissions by 11-22%, without harming throughput or safety, and with reasonable assumptions, equivalent to the national emissions of Israel and Nigeria, respectively. We find that 10% eco-driving adoption yields 25%-50% of the total reduction, and nearly 70% of the benefits come from 20% of intersections, suggesting near-term implementation pathways. However, the composition of this high-impact subset of intersections varies considerably across different adoption levels, with minimal overlap, calling for careful strategic planning for eco-driving deployments. Moreover, the impact of eco-driving, when considered jointly with projections of vehicle electrification and hybrid vehicle adoption remains significant. More broadly, this work paves the way for large-scale analysis of traffic externalities, such as time, safety, and air quality, and the potential impact of solution strategies.
Cooperation for Scalable Supervision of Autonomy in Mixed Traffic
Dec 14, 2021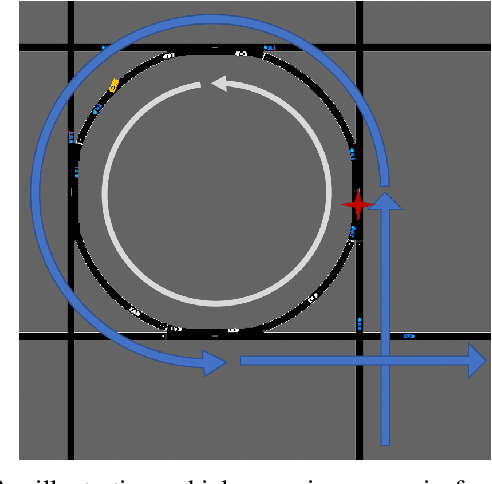

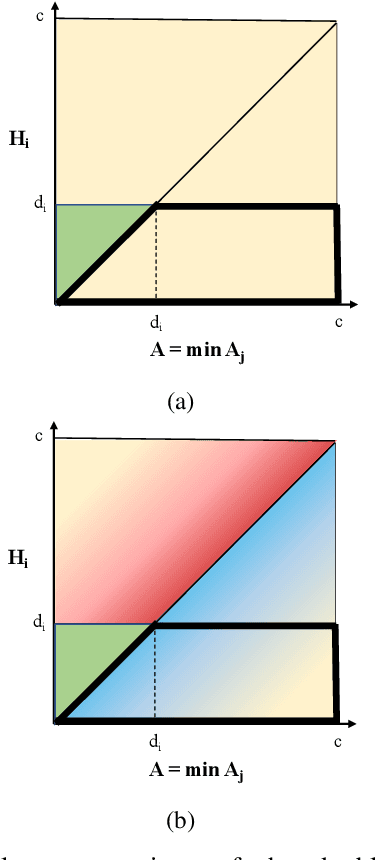
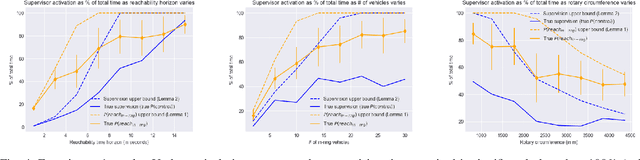
Improvements in autonomy offer the potential for positive outcomes in a number of domains, yet guaranteeing their safe deployment is difficult. This work investigates how humans can intelligently supervise agents to achieve some level of safety even when performance guarantees are elusive. The motivating research question is: In safety-critical settings, can we avoid the need to have one human supervise one machine at all times? The paper formalizes this 'scaling supervision' problem, and investigates its application to the safety-critical context of autonomous vehicles (AVs) merging into traffic. It proposes a conservative, reachability-based method to reduce the burden on the AVs' human supervisors, which allows for the establishment of high-confidence upper bounds on the supervision requirements in this setting. Order statistics and traffic simulations with deep reinforcement learning show analytically and numerically that teaming of AVs enables supervision time sublinear in AV adoption. A key takeaway is that, despite present imperfections of AVs, supervision becomes more tractable as AVs are deployed en masse. While this work focuses on AVs, the scalable supervision framework is relevant to a broader array of autonomous control challenges.
Autonomous Attack Mitigation for Industrial Control Systems
Nov 03, 2021

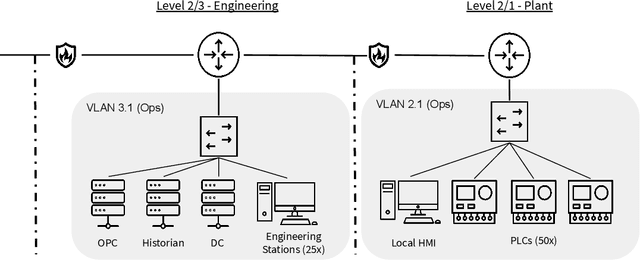

Defending computer networks from cyber attack requires timely responses to alerts and threat intelligence. Decisions about how to respond involve coordinating actions across multiple nodes based on imperfect indicators of compromise while minimizing disruptions to network operations. Currently, playbooks are used to automate portions of a response process, but often leave complex decision-making to a human analyst. In this work, we present a deep reinforcement learning approach to autonomous response and recovery in large industrial control networks. We propose an attention-based neural architecture that is flexible to the size of the network under protection. To train and evaluate the autonomous defender agent, we present an industrial control network simulation environment suitable for reinforcement learning. Experiments show that the learned agent can effectively mitigate advanced attacks that progress with few observable signals over several months before execution. The proposed deep reinforcement learning approach outperforms a fully automated playbook method in simulation, taking less disruptive actions while also defending more nodes on the network. The learned policy is also more robust to changes in attacker behavior than playbook approaches.
Stratified Experience Replay: Correcting Multiplicity Bias in Off-Policy Reinforcement Learning
Feb 22, 2021
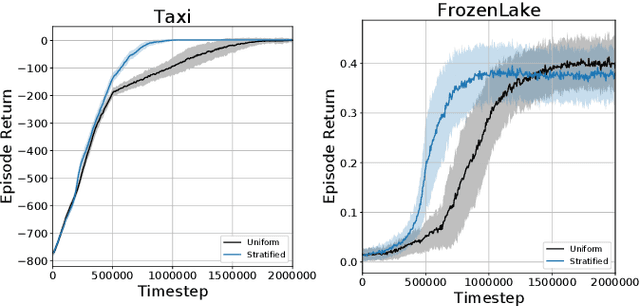
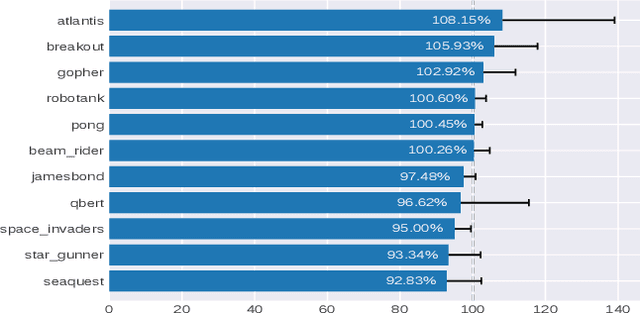
Deep Reinforcement Learning (RL) methods rely on experience replay to approximate the minibatched supervised learning setting; however, unlike supervised learning where access to lots of training data is crucial to generalization, replay-based deep RL appears to struggle in the presence of extraneous data. Recent works have shown that the performance of Deep Q-Network (DQN) degrades when its replay memory becomes too large. This suggests that outdated experiences somehow impact the performance of deep RL, which should not be the case for off-policy methods like DQN. Consequently, we re-examine the motivation for sampling uniformly over a replay memory, and find that it may be flawed when using function approximation. We show that -- despite conventional wisdom -- sampling from the uniform distribution does not yield uncorrelated training samples and therefore biases gradients during training. Our theory prescribes a special non-uniform distribution to cancel this effect, and we propose a stratified sampling scheme to efficiently implement it.