 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Attack Mitigation for Industrial Control Systems
Nov 03, 2021

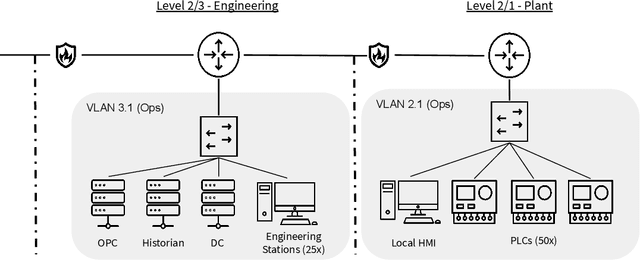

Defending computer networks from cyber attack requires timely responses to alerts and threat intelligence. Decisions about how to respond involve coordinating actions across multiple nodes based on imperfect indicators of compromise while minimizing disruptions to network operations. Currently, playbooks are used to automate portions of a response process, but often leave complex decision-making to a human analyst. In this work, we present a deep reinforcement learning approach to autonomous response and recovery in large industrial control networks. We propose an attention-based neural architecture that is flexible to the size of the network under protection. To train and evaluate the autonomous defender agent, we present an industrial control network simulation environment suitable for reinforcement learning. Experiments show that the learned agent can effectively mitigate advanced attacks that progress with few observable signals over several months before execution. The proposed deep reinforcement learning approach outperforms a fully automated playbook method in simulation, taking less disruptive actions while also defending more nodes on the network. The learned policy is also more robust to changes in attacker behavior than playbook approaches.
Reinforcement Learning for Industrial Control Network Cyber Security Orchestration
Jun 09, 2021
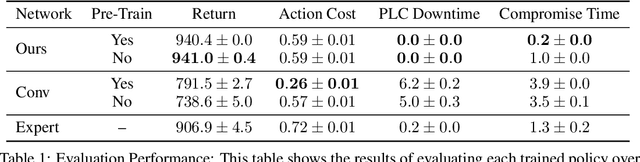
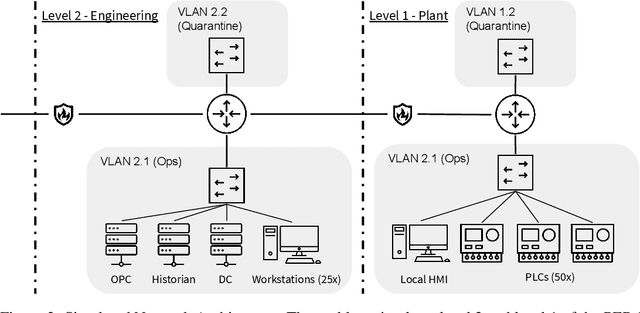
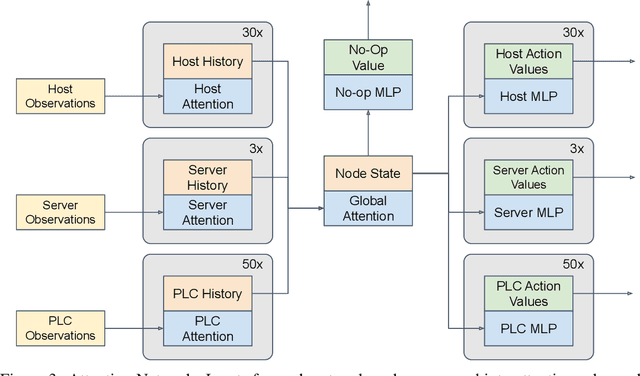
Defending computer networks from cyber attack requires coordinating actions across multiple nodes based on imperfect indicators of compromise while minimizing disruptions to network operations. Advanced attacks can progress with few observable signals over several months before execution. The resulting sequential decision problem has large observation and action spaces and a long time-horizon, making it difficult to solve with existing methods. In this work, we present techniques to scale deep reinforcement learning to solve the cyber security orchestration problem for large industrial control networks. We propose a novel attention-based neural architecture with size complexity that is invariant to the size of the network under protection. A pre-training curriculum is presented to overcome early exploration difficulty. Experiments show in that the proposed approaches greatly improve both the learning sample complexity and converged policy performance over baseline methods in simulation.