 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStratified Experience Replay: Correcting Multiplicity Bias in Off-Policy Reinforcement Learning
Paper and Code
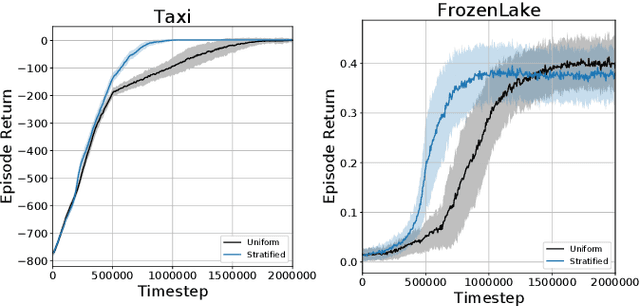
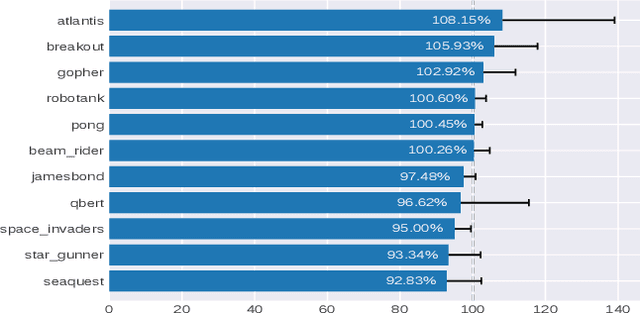
Deep Reinforcement Learning (RL) methods rely on experience replay to approximate the minibatched supervised learning setting; however, unlike supervised learning where access to lots of training data is crucial to generalization, replay-based deep RL appears to struggle in the presence of extraneous data. Recent works have shown that the performance of Deep Q-Network (DQN) degrades when its replay memory becomes too large. This suggests that outdated experiences somehow impact the performance of deep RL, which should not be the case for off-policy methods like DQN. Consequently, we re-examine the motivation for sampling uniformly over a replay memory, and find that it may be flawed when using function approximation. We show that -- despite conventional wisdom -- sampling from the uniform distribution does not yield uncorrelated training samples and therefore biases gradients during training. Our theory prescribes a special non-uniform distribution to cancel this effect, and we propose a stratified sampling scheme to efficiently implement it.