 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeting World Models to Compromise Robot Learning Pipelines
Jun 08, 2026World models have recently seen a rapid growth in both their popularity and capability as more data efficient tools for generating robot training data or simulating real world environments, with many works proposing their integration into the robot learning pipeline. While highly practical, in this work we demonstrate that world models introduce a uniquely stealthy and effective data poisoning entry point into the robot learning supply chain that can result in the deployment of unsafe or otherwise compromised robotic policies despite training on seemingly safe ground truth training data. In contrast to traditional data poisoning techniques which directly implant dangerous trajectories into sold or uploaded datasets, our novel attack methods inject malicious prompts or compromising transition dynamics into visibly safe teleoperated datasets which are only activated once fed through a world model as input. This can result in the generation of synthetic, dangerous robot training trajectories and subsequently unsafe or compromised robot policies. We demonstrate the effectiveness of our attacks against both state of the art action conditioned and text conditioned world models, showing a full end-to-end backdoor on a downstream DRL policy and a proof-of-concept for the VLA setting. Overall these findings necessitate research into more secure world models and reevaluating their position within the robot learning supply chain.
Rethinking Ratio-Based Trust Regions for Policy Optimization in Multi-Agent Reinforcement Learning
May 09, 2026Centralized training with decentralized execution (CTDE) is a standard framework for cooperative multi-agent policy-gradient reinforcement learning, allowing agents to learn from joint information while acting from local observations. Ratio-based trust-region methods such as Multi-Agent Proximal Policy Optimization (MAPPO) and Multi-Agent Simple Policy Optimization (MASPO) update decentralized actors using per-agent probability ratios weighted by joint advantage estimates. Teammate non-stationarity increases the variance of these advantages, which in turn increases the variance in the local ratio updates. This exposes two method-specific failure modes: MAPPO's additive clipping removes gradients for outlier samples and weakens recovery from policy drift, while MASPO's soft quadratic penalty can allow probability collapse. We introduce Multi-Agent Ratio Symmetry (MARS), a novel policy optimization objective that replaces these additive ratio-based trust-region mechanisms with a multiplicatively symmetric geometric barrier. MARS preserves corrective gradients while assigning unbounded cost as probability ratios approach zero. Across 47 tasks spanning eight multi-agent environments, including novel JAX benchmarks PaxMen and AeroJAX, MARS matches or exceeds MAPPO and MASPO in aggregate environment-level performance. Ablations show that these gains arise from the geometry of the symmetric barrier rather than from flexible trust-region boundaries alone.
Cross-Modal Navigation with Multi-Agent Reinforcement Learning
May 07, 2026Robust embodied navigation relies on complementary sensory cues. However, high-quality and well-aligned multi-modal data is often difficult to obtain in practice. Training a monolithic model is also challenging as rich multi-modal inputs induce complex representations and substantially enlarge the policy space. Cross-modal collaboration among lightweight modality-specialized agents offers a scalable paradigm. It enables flexible deployment and parallel execution, while preserving the strength of each modality. In this paper, we propose \textbf{CRONA}, a Multi-Agent Reinforcement Learning (MARL) framework for \textbf{Cro}ss-Modal \textbf{Na}vigation. CRONA improves collaboration by leveraging control-relevant auxiliary beliefs and a centralized multi-modal critic with global state. Experiments on visual-acoustic navigation tasks show that multi-agent methods significantly improve performance and efficiency over single-agent baselines. We find that homogeneous collaboration with limited modalities is sufficient for short-range navigation under salient cues; heterogeneous collaboration among agents with complementary modalities is generally efficient and effective; and navigation in large, complex environments requires both richer multi-modal perception and increased model capacity.
Beware Untrusted Simulators -- Reward-Free Backdoor Attacks in Reinforcement Learning
Feb 04, 2026Simulated environments are a key piece in the success of Reinforcement Learning (RL), allowing practitioners and researchers to train decision making agents without running expensive experiments on real hardware. Simulators remain a security blind spot, however, enabling adversarial developers to alter the dynamics of their released simulators for malicious purposes. Therefore, in this work we highlight a novel threat, demonstrating how simulator dynamics can be exploited to stealthily implant action-level backdoors into RL agents. The backdoor then allows an adversary to reliably activate targeted actions in an agent upon observing a predefined ``trigger'', leading to potentially dangerous consequences. Traditional backdoor attacks are limited in their strong threat models, assuming the adversary has near full control over an agent's training pipeline, enabling them to both alter and observe agent's rewards. As these assumptions are infeasible to implement within a simulator, we propose a new attack ``Daze'' which is able to reliably and stealthily implant backdoors into RL agents trained for real world tasks without altering or even observing their rewards. We provide formal proof of Daze's effectiveness in guaranteeing attack success across general RL tasks along with extensive empirical evaluations on both discrete and continuous action space domains. We additionally provide the first example of RL backdoor attacks transferring to real, robotic hardware. These developments motivate further research into securing all components of the RL training pipeline to prevent malicious attacks.
Learning Decentralized LLM Collaboration with Multi-Agent Actor Critic
Jan 29, 2026Recent work has explored optimizing LLM collaboration through Multi-Agent Reinforcement Learning (MARL). However, most MARL fine-tuning approaches rely on predefined execution protocols, which often require centralized execution. Decentralized LLM collaboration is more appealing in practice, as agents can run inference in parallel with flexible deployments. Also, current approaches use Monte Carlo methods for fine-tuning, which suffer from high variance and thus require more samples to train effectively. Actor-critic methods are prevalent in MARL for dealing with these issues, so we developed Multi-Agent Actor-Critic (MAAC) methods to optimize decentralized LLM collaboration. In this paper, we analyze when and why these MAAC methods are beneficial. We propose 2 MAAC approaches, \textbf{CoLLM-CC} with a \textbf{C}entralized \textbf{C}ritic and \textbf{CoLLM-DC} with \textbf{D}ecentralized \textbf{C}ritics. Our experiments across writing, coding, and game-playing domains show that Monte Carlo methods and CoLLM-DC can achieve performance comparable to CoLLM-CC in short-horizon and dense-reward settings. However, they both underperform CoLLM-CC on long-horizon or sparse-reward tasks, where Monte Carlo methods require substantially more samples and CoLLM-DC struggles to converge. Our code is available at https://github.com/OpenMLRL/CoMLRL/releases/tag/v1.3.2.
LLM Collaboration With Multi-Agent Reinforcement Learning
Aug 06, 2025A large amount of work has been done in Multi-Agent Systems (MAS) for modeling and solving problems with multiple interacting agents. However, most LLMs are pretrained independently and not specifically optimized for coordination. Existing LLM fine-tuning frameworks rely on individual rewards, which require complex reward designs for each agent to encourage collaboration. To address these challenges, we model LLM collaboration as a cooperative Multi-Agent Reinforcement Learning (MARL) problem. We develop a multi-agent, multi-turn algorithm, Multi-Agent Group Relative Policy Optimization (MAGRPO), to solve it, building on current RL approaches for LLMs as well as MARL techniques. Our experiments on LLM writing and coding collaboration demonstrate that fine-tuning MAS with MAGRPO enables agents to generate high-quality responses efficiently through effective cooperation. Our approach opens the door to using other MARL methods for LLMs and highlights the associated challenges.
Fixing Incomplete Value Function Decomposition for Multi-Agent Reinforcement Learning
May 15, 2025Value function decomposition methods for cooperative multi-agent reinforcement learning compose joint values from individual per-agent utilities, and train them using a joint objective. To ensure that the action selection process between individual utilities and joint values remains consistent, it is imperative for the composition to satisfy the individual-global max (IGM) property. Although satisfying IGM itself is straightforward, most existing methods (e.g., VDN, QMIX) have limited representation capabilities and are unable to represent the full class of IGM values, and the one exception that has no such limitation (QPLEX) is unnecessarily complex. In this work, we present a simple formulation of the full class of IGM values that naturally leads to the derivation of QFIX, a novel family of value function decomposition models that expand the representation capabilities of prior models by means of a thin "fixing" layer. We derive multiple variants of QFIX, and implement three variants in two well-known multi-agent frameworks. We perform an empirical evaluation on multiple SMACv2 and Overcooked environments, which confirms that QFIX (i) succeeds in enhancing the performance of prior methods, (ii) learns more stably and performs better than its main competitor QPLEX, and (iii) achieves this while employing the simplest and smallest mixing models.
Safe Multiagent Coordination via Entropic Exploration
Dec 29, 2024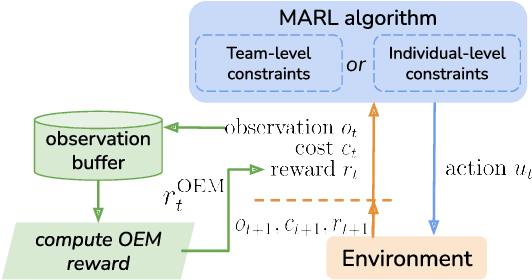
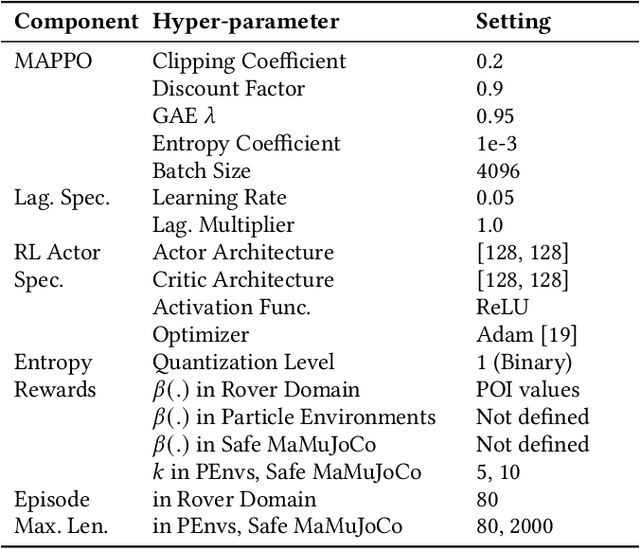
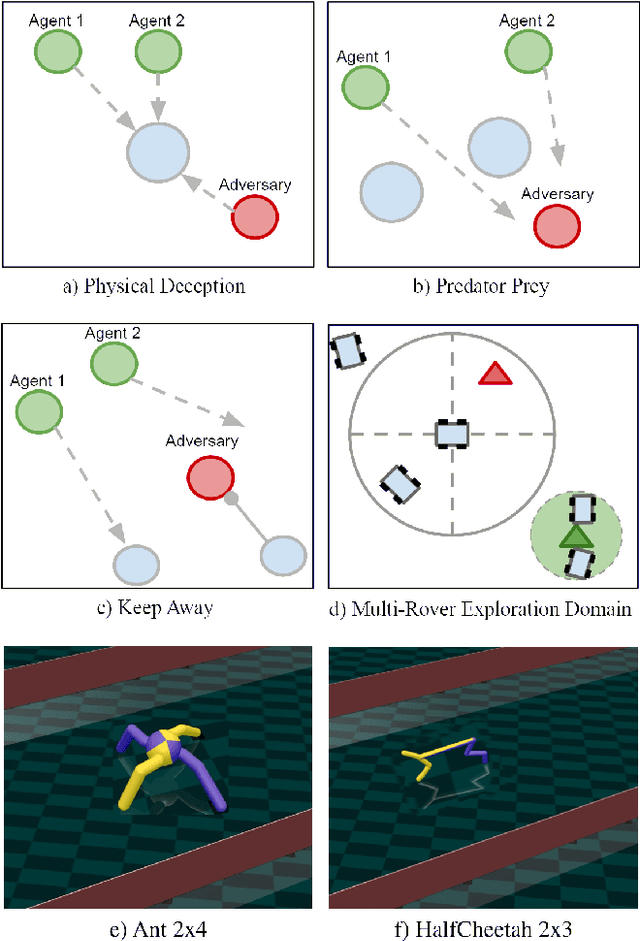
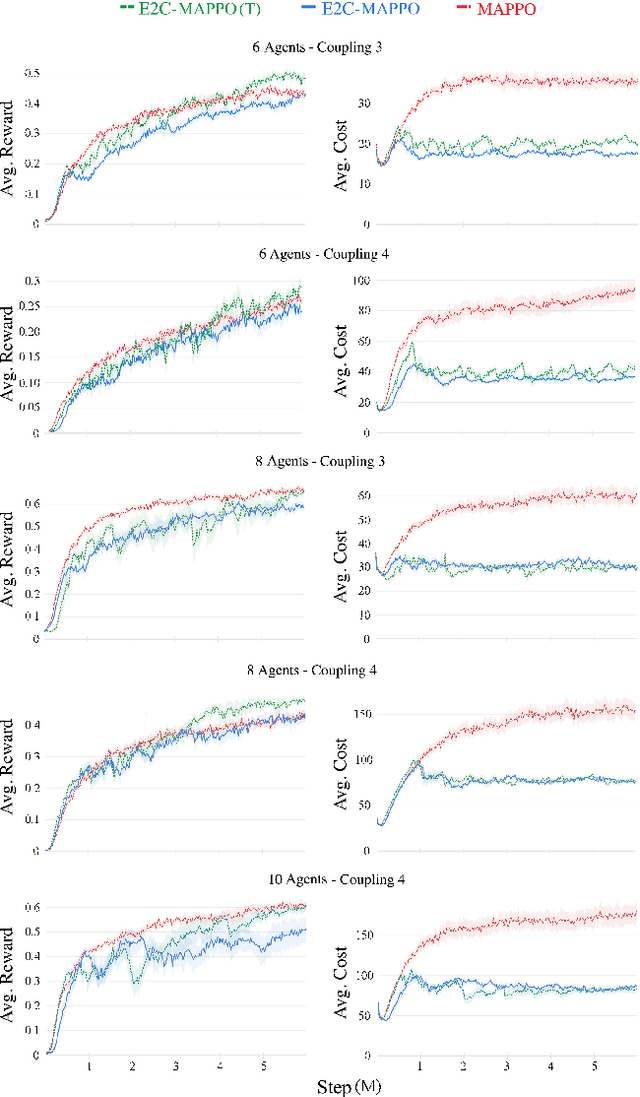
Many real-world multiagent learning problems involve safety concerns. In these setups, typical safe reinforcement learning algorithms constrain agents' behavior, limiting exploration -- a crucial component for discovering effective cooperative multiagent behaviors. Moreover, the multiagent literature typically models individual constraints for each agent and has yet to investigate the benefits of using joint team constraints. In this work, we analyze these team constraints from a theoretical and practical perspective and propose entropic exploration for constrained multiagent reinforcement learning (E2C) to address the exploration issue. E2C leverages observation entropy maximization to incentivize exploration and facilitate learning safe and effective cooperative behaviors. Experiments across increasingly complex domains show that E2C agents match or surpass common unconstrained and constrained baselines in task performance while reducing unsafe behaviors by up to $50\%$.
Adversarial Inception for Bounded Backdoor Poisoning in Deep Reinforcement Learning
Oct 21, 2024Recent works have demonstrated the vulnerability of Deep Reinforcement Learning (DRL) algorithms against training-time, backdoor poisoning attacks. These attacks induce pre-determined, adversarial behavior in the agent upon observing a fixed trigger during deployment while allowing the agent to solve its intended task during training. Prior attacks rely on arbitrarily large perturbations to the agent's rewards to achieve both of these objectives - leaving them open to detection. Thus, in this work, we propose a new class of backdoor attacks against DRL which achieve state of the art performance while minimally altering the agent's rewards. These "inception" attacks train the agent to associate the targeted adversarial behavior with high returns by inducing a disjunction between the agent's chosen action and the true action executed in the environment during training. We formally define these attacks and prove they can achieve both adversarial objectives. We then devise an online inception attack which significantly out-performs prior attacks under bounded reward constraints.
On Stateful Value Factorization in Multi-Agent Reinforcement Learning
Sep 09, 2024



Value factorization is a popular paradigm for designing scalable multi-agent reinforcement learning algorithms. However, current factorization methods make choices without full justification that may limit their performance. For example, the theory in prior work uses stateless (i.e., history) functions, while the practical implementations use state information -- making the motivating theory a mismatch for the implementation. Also, methods have built off of previous approaches, inheriting their architectures without exploring other, potentially better ones. To address these concerns, we formally analyze the theory of using the state instead of the history in current methods -- reconnecting theory and practice. We then introduce DuelMIX, a factorization algorithm that learns distinct per-agent utility estimators to improve performance and achieve full expressiveness. Experiments on StarCraft II micromanagement and Box Pushing tasks demonstrate the benefits of our intuitions.