 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing Incomplete Value Function Decomposition for Multi-Agent Reinforcement Learning
May 15, 2025Value function decomposition methods for cooperative multi-agent reinforcement learning compose joint values from individual per-agent utilities, and train them using a joint objective. To ensure that the action selection process between individual utilities and joint values remains consistent, it is imperative for the composition to satisfy the individual-global max (IGM) property. Although satisfying IGM itself is straightforward, most existing methods (e.g., VDN, QMIX) have limited representation capabilities and are unable to represent the full class of IGM values, and the one exception that has no such limitation (QPLEX) is unnecessarily complex. In this work, we present a simple formulation of the full class of IGM values that naturally leads to the derivation of QFIX, a novel family of value function decomposition models that expand the representation capabilities of prior models by means of a thin "fixing" layer. We derive multiple variants of QFIX, and implement three variants in two well-known multi-agent frameworks. We perform an empirical evaluation on multiple SMACv2 and Overcooked environments, which confirms that QFIX (i) succeeds in enhancing the performance of prior methods, (ii) learns more stably and performs better than its main competitor QPLEX, and (iii) achieves this while employing the simplest and smallest mixing models.
On Stateful Value Factorization in Multi-Agent Reinforcement Learning
Sep 09, 2024



Value factorization is a popular paradigm for designing scalable multi-agent reinforcement learning algorithms. However, current factorization methods make choices without full justification that may limit their performance. For example, the theory in prior work uses stateless (i.e., history) functions, while the practical implementations use state information -- making the motivating theory a mismatch for the implementation. Also, methods have built off of previous approaches, inheriting their architectures without exploring other, potentially better ones. To address these concerns, we formally analyze the theory of using the state instead of the history in current methods -- reconnecting theory and practice. We then introduce DuelMIX, a factorization algorithm that learns distinct per-agent utility estimators to improve performance and achieve full expressiveness. Experiments on StarCraft II micromanagement and Box Pushing tasks demonstrate the benefits of our intuitions.
Equivariant Reinforcement Learning under Partial Observability
Aug 26, 2024Incorporating inductive biases is a promising approach for tackling challenging robot learning domains with sample-efficient solutions. This paper identifies partially observable domains where symmetries can be a useful inductive bias for efficient learning. Specifically, by encoding the equivariance regarding specific group symmetries into the neural networks, our actor-critic reinforcement learning agents can reuse solutions in the past for related scenarios. Consequently, our equivariant agents outperform non-equivariant approaches significantly in terms of sample efficiency and final performance, demonstrated through experiments on a range of robotic tasks in simulation and real hardware.
On Centralized Critics in Multi-Agent Reinforcement Learning
Aug 26, 2024Centralized Training for Decentralized Execution where agents are trained offline in a centralized fashion and execute online in a decentralized manner, has become a popular approach in Multi-Agent Reinforcement Learning (MARL). In particular, it has become popular to develop actor-critic methods that train decentralized actors with a centralized critic where the centralized critic is allowed access global information of the entire system, including the true system state. Such centralized critics are possible given offline information and are not used for online execution. While these methods perform well in a number of domains and have become a de facto standard in MARL, using a centralized critic in this context has yet to be sufficiently analyzed theoretically or empirically. In this paper, we therefore formally analyze centralized and decentralized critic approaches, and analyze the effect of using state-based critics in partially observable environments. We derive theories contrary to the common intuition: critic centralization is not strictly beneficial, and using state values can be harmful. We further prove that, in particular, state-based critics can introduce unexpected bias and variance compared to history-based critics. Finally, we demonstrate how the theory applies in practice by comparing different forms of critics on a wide range of common multi-agent benchmarks. The experiments show practical issues such as the difficulty of representation learning with partial observability, which highlights why the theoretical problems are often overlooked in the literature.
Leveraging Fully Observable Policies for Learning under Partial Observability
Nov 10, 2022



Reinforcement learning in partially observable domains is challenging due to the lack of observable state information. Thankfully, learning offline in a simulator with such state information is often possible. In particular, we propose a method for partially observable reinforcement learning that uses a fully observable policy (which we call a state expert) during offline training to improve online performance. Based on Soft Actor-Critic (SAC), our agent balances performing actions similar to the state expert and getting high returns under partial observability. Our approach can leverage the fully-observable policy for exploration and parts of the domain that are fully observable while still being able to learn under partial observability. On six robotics domains, our method outperforms pure imitation, pure reinforcement learning, the sequential or parallel combination of both types, and a recent state-of-the-art method in the same setting. A successful policy transfer to a physical robot in a manipulation task from pixels shows our approach's practicality in learning interesting policies under partial observability.
Hierarchical Reinforcement Learning under Mixed Observability
Apr 05, 2022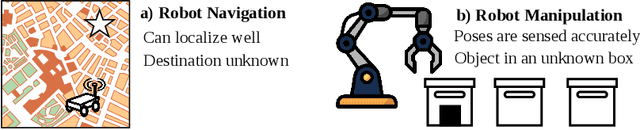

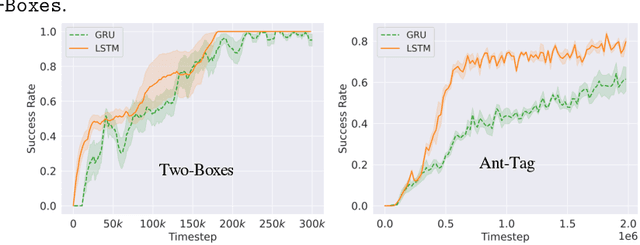
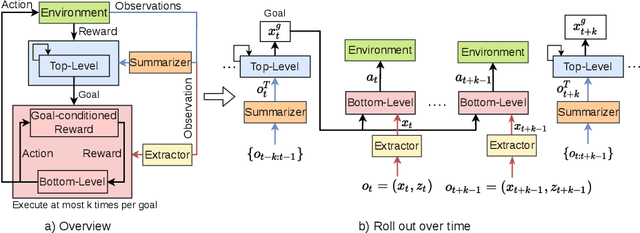
The framework of mixed observable Markov decision processes (MOMDP) models many robotic domains in which some state variables are fully observable while others are not. In this work, we identify a significant subclass of MOMDPs defined by how actions influence the fully observable components of the state and how those, in turn, influence the partially observable components and the rewards. This unique property allows for a two-level hierarchical approach we call HIerarchical Reinforcement Learning under Mixed Observability (HILMO), which restricts partial observability to the top level while the bottom level remains fully observable, enabling higher learning efficiency. The top level produces desired goals to be reached by the bottom level until the task is solved. We further develop theoretical guarantees to show that our approach can achieve optimal and quasi-optimal behavior under mild assumptions. Empirical results on long-horizon continuous control tasks demonstrate the efficacy and efficiency of our approach in terms of improved success rate, sample efficiency, and wall-clock training time. We also deploy policies learned in simulation on a real robot.
A Deeper Understanding of State-Based Critics in Multi-Agent Reinforcement Learning
Jan 03, 2022

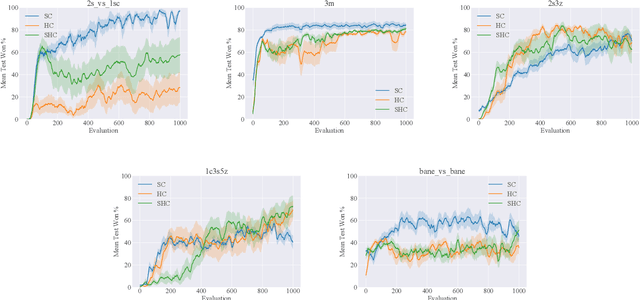
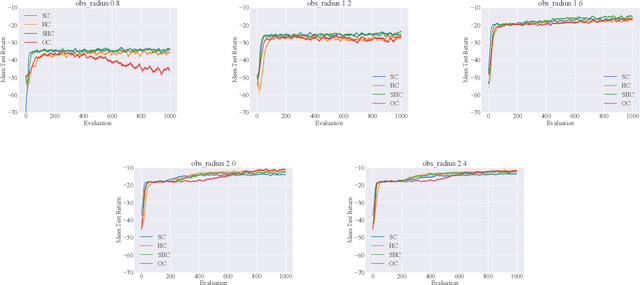
Centralized Training for Decentralized Execution, where training is done in a centralized offline fashion, has become a popular solution paradigm in Multi-Agent Reinforcement Learning. Many such methods take the form of actor-critic with state-based critics, since centralized training allows access to the true system state, which can be useful during training despite not being available at execution time. State-based critics have become a common empirical choice, albeit one which has had limited theoretical justification or analysis. In this paper, we show that state-based critics can introduce bias in the policy gradient estimates, potentially undermining the asymptotic guarantees of the algorithm. We also show that, even if the state-based critics do not introduce any bias, they can still result in a larger gradient variance, contrary to the common intuition. Finally, we show the effects of the theories in practice by comparing different forms of centralized critics on a wide range of common benchmarks, and detail how various environmental properties are related to the effectiveness of different types of critics.
Reconciling Rewards with Predictive State Representations
Jun 07, 2021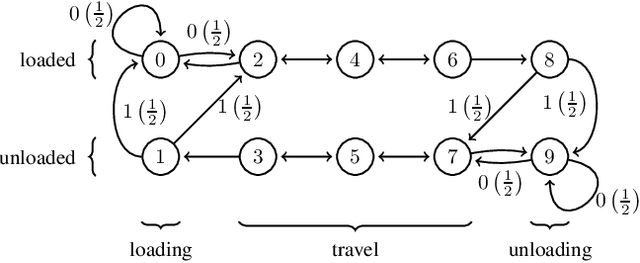
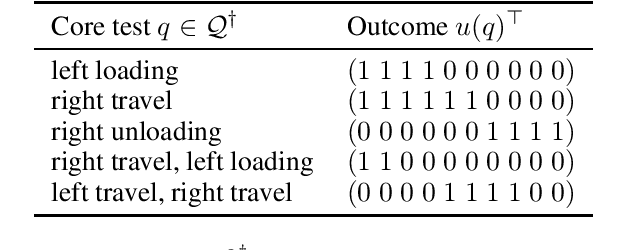

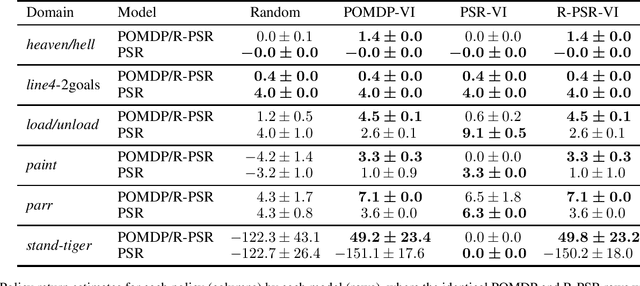
Predictive state representations (PSRs) are models of controlled non-Markov observation sequences which exhibit the same generative process governing POMDP observations without relying on an underlying latent state. In that respect, a PSR is indistinguishable from the corresponding POMDP. However, PSRs notoriously ignore the notion of rewards, which undermines the general utility of PSR models for control, planning, or reinforcement learning. Therefore, we describe a sufficient and necessary accuracy condition which determines whether a PSR is able to accurately model POMDP rewards, we show that rewards can be approximated even when the accuracy condition is not satisfied, and we find that a non-trivial number of POMDPs taken from a well-known third-party repository do not satisfy the accuracy condition. We propose reward-predictive state representations (R-PSRs), a generalization of PSRs which accurately models both observations and rewards, and develop value iteration for R-PSRs. We show that there is a mismatch between optimal POMDP policies and the optimal PSR policies derived from approximate rewards. On the other hand, optimal R-PSR policies perfectly match optimal POMDP policies, reconfirming R-PSRs as accurate state-less generative models of observations and rewards.
Unbiased Asymmetric Actor-Critic for Partially Observable Reinforcement Learning
May 25, 2021



In partially observable reinforcement learning, offline training gives access to latent information which is not available during online training and/or execution, such as the system state. Asymmetric actor-critic methods exploit such information by training a history-based policy via a state-based critic. However, many asymmetric methods lack theoretical foundation, and are only evaluated on limited domains. We examine the theory of asymmetric actor-critic methods which use state-based critics, and expose fundamental issues which undermine the validity of a common variant, and its ability to address high partial observability. We propose an unbiased asymmetric actor-critic variant which is able to exploit state information while remaining theoretically sound, maintaining the validity of the policy gradient theorem, and introducing no bias and relatively low variance into the training process. An empirical evaluation performed on domains which exhibit significant partial observability confirms our analysis, and shows the unbiased asymmetric actor-critic converges to better policies and/or faster than symmetric actor-critic and standard asymmetric actor-critic baselines.
Active Goal Recognition
Sep 24, 2019

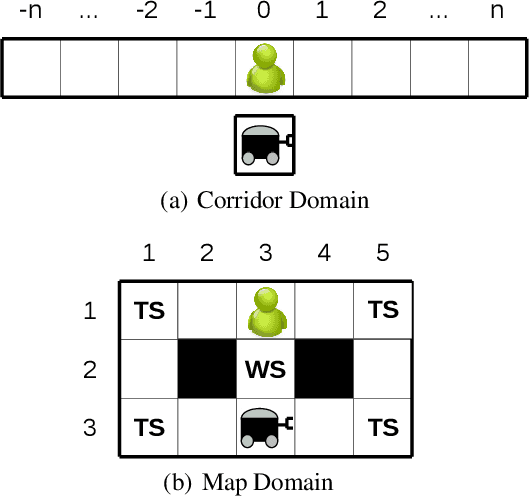
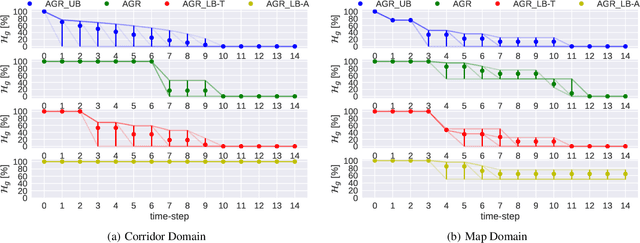
To coordinate with other systems, agents must be able to determine what the systems are currently doing and predict what they will be doing in the future---plan and goal recognition. There are many methods for plan and goal recognition, but they assume a passive observer that continually monitors the target system. Real-world domains, where information gathering has a cost (e.g., moving a camera or a robot, or time taken away from another task), will often require a more active observer. We propose to combine goal recognition with other observer tasks in order to obtain \emph{active goal recognition} (AGR). We discuss this problem and provide a model and preliminary experimental results for one form of this composite problem. As expected, the results show that optimal behavior in AGR problems balance information gathering with other actions (e.g., task completion) such as to achieve all tasks jointly and efficiently. We hope that our formulation opens the door for extensive further research on this interesting and realistic problem.