 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Collaboration With Multi-Agent Reinforcement Learning
Aug 06, 2025A large amount of work has been done in Multi-Agent Systems (MAS) for modeling and solving problems with multiple interacting agents. However, most LLMs are pretrained independently and not specifically optimized for coordination. Existing LLM fine-tuning frameworks rely on individual rewards, which require complex reward designs for each agent to encourage collaboration. To address these challenges, we model LLM collaboration as a cooperative Multi-Agent Reinforcement Learning (MARL) problem. We develop a multi-agent, multi-turn algorithm, Multi-Agent Group Relative Policy Optimization (MAGRPO), to solve it, building on current RL approaches for LLMs as well as MARL techniques. Our experiments on LLM writing and coding collaboration demonstrate that fine-tuning MAS with MAGRPO enables agents to generate high-quality responses efficiently through effective cooperation. Our approach opens the door to using other MARL methods for LLMs and highlights the associated challenges.
On Centralized Critics in Multi-Agent Reinforcement Learning
Aug 26, 2024



Centralized Training for Decentralized Execution where agents are trained offline in a centralized fashion and execute online in a decentralized manner, has become a popular approach in Multi-Agent Reinforcement Learning (MARL). In particular, it has become popular to develop actor-critic methods that train decentralized actors with a centralized critic where the centralized critic is allowed access global information of the entire system, including the true system state. Such centralized critics are possible given offline information and are not used for online execution. While these methods perform well in a number of domains and have become a de facto standard in MARL, using a centralized critic in this context has yet to be sufficiently analyzed theoretically or empirically. In this paper, we therefore formally analyze centralized and decentralized critic approaches, and analyze the effect of using state-based critics in partially observable environments. We derive theories contrary to the common intuition: critic centralization is not strictly beneficial, and using state values can be harmful. We further prove that, in particular, state-based critics can introduce unexpected bias and variance compared to history-based critics. Finally, we demonstrate how the theory applies in practice by comparing different forms of critics on a wide range of common multi-agent benchmarks. The experiments show practical issues such as the difficulty of representation learning with partial observability, which highlights why the theoretical problems are often overlooked in the literature.
A Deeper Understanding of State-Based Critics in Multi-Agent Reinforcement Learning
Jan 03, 2022

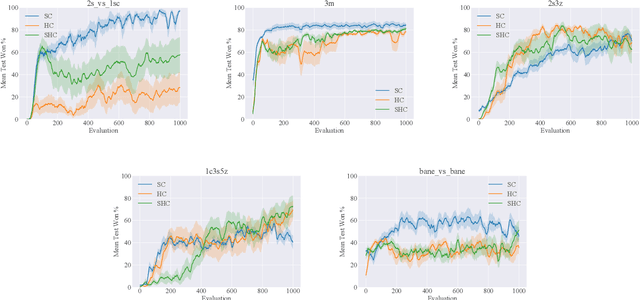
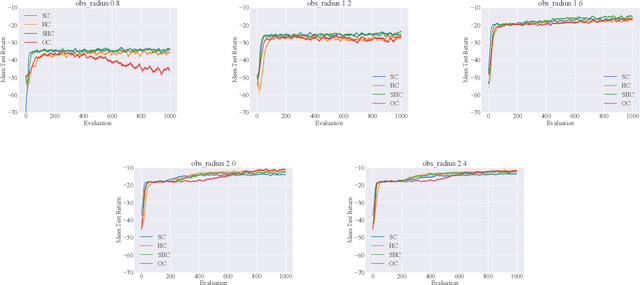
Centralized Training for Decentralized Execution, where training is done in a centralized offline fashion, has become a popular solution paradigm in Multi-Agent Reinforcement Learning. Many such methods take the form of actor-critic with state-based critics, since centralized training allows access to the true system state, which can be useful during training despite not being available at execution time. State-based critics have become a common empirical choice, albeit one which has had limited theoretical justification or analysis. In this paper, we show that state-based critics can introduce bias in the policy gradient estimates, potentially undermining the asymptotic guarantees of the algorithm. We also show that, even if the state-based critics do not introduce any bias, they can still result in a larger gradient variance, contrary to the common intuition. Finally, we show the effects of the theories in practice by comparing different forms of centralized critics on a wide range of common benchmarks, and detail how various environmental properties are related to the effectiveness of different types of critics.
Local Advantage Actor-Critic for Robust Multi-Agent Deep Reinforcement Learning
Nov 02, 2021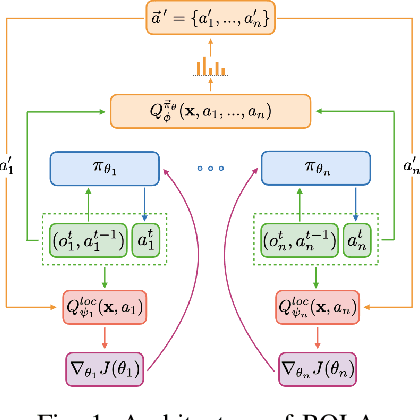
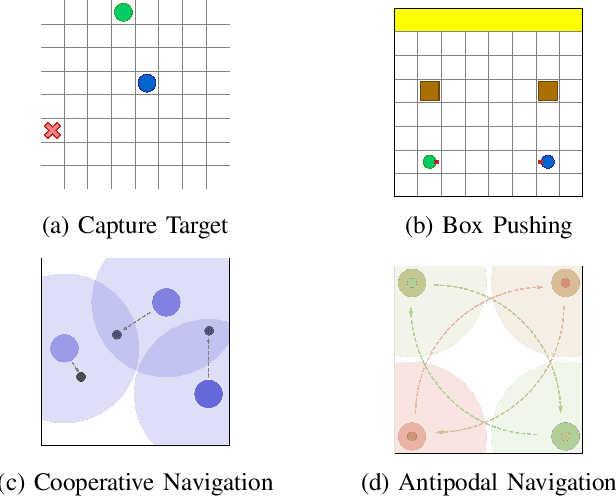
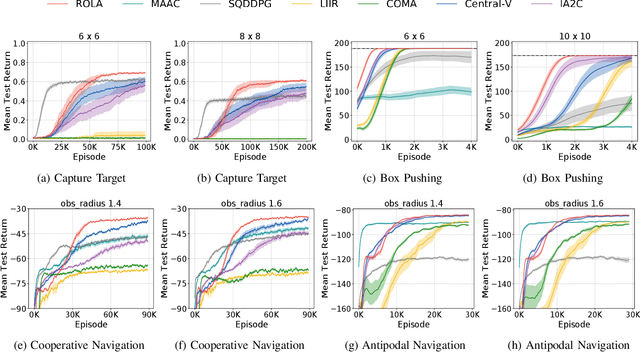
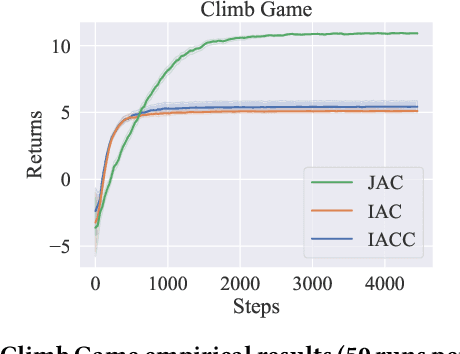
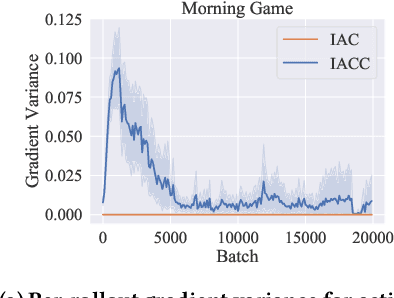
Policy gradient methods have become popular in multi-agent reinforcement learning, but they suffer from high variance due to the presence of environmental stochasticity and exploring agents (i.e., non-stationarity), which is potentially worsened by the difficulty in credit assignment. As a result, there is a need for a method that is not only capable of efficiently solving the above two problems but also robust enough to solve a variety of tasks. To this end, we propose a new multi-agent policy gradient method, called Robust Local Advantage (ROLA) Actor-Critic. ROLA allows each agent to learn an individual action-value function as a local critic as well as ameliorating environment non-stationarity via a novel centralized training approach based on a centralized critic. By using this local critic, each agent calculates a baseline to reduce variance on its policy gradient estimation, which results in an expected advantage action-value over other agents' choices that implicitly improves credit assignment. We evaluate ROLA across diverse benchmarks and show its robustness and effectiveness over a number of state-of-the-art multi-agent policy gradient algorithms.
Contrasting Centralized and Decentralized Critics in Multi-Agent Reinforcement Learning
Feb 08, 2021

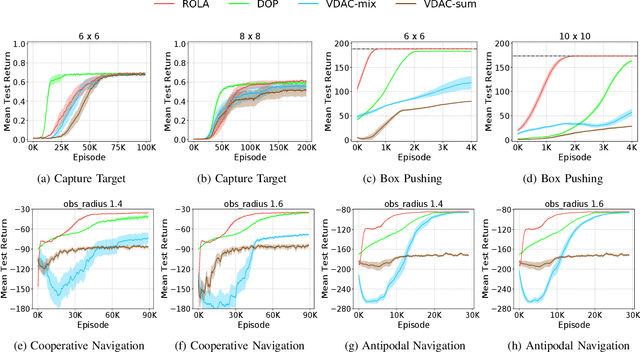
Centralized Training for Decentralized Execution, where agents are trained offline using centralized information but execute in a decentralized manner online, has gained popularity in the multi-agent reinforcement learning community. In particular, actor-critic methods with a centralized critic and decentralized actors are a common instance of this idea. However, the implications of using a centralized critic in this context are not fully discussed and understood even though it is the standard choice of many algorithms. We therefore formally analyze centralized and decentralized critic approaches, providing a deeper understanding of the implications of critic choice. Because our theory makes unrealistic assumptions, we also empirically compare the centralized and decentralized critic methods over a wide set of environments to validate our theories and to provide practical advice. We show that there exist misconceptions regarding centralized critics in the current literature and show that the centralized critic design is not strictly beneficial, but rather both centralized and decentralized critics have different pros and cons that should be taken into account by algorithm designers.