 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Quadruped Robots Coordination via Semantic Skill Discovery
Jun 06, 2026Multi-quadruped coordination has attracted increasing attention due to its enhanced payload capacity, broader contact coverage, and improved adaptability to challenging tasks. Existing methods for multi-quadruped manipulation typically focus on predefined or closed task families, often relying on multi-agent reinforcement learning (MARL) to train task-specific coordination policies. However, such methods struggle in open-ended continual learning settings, where tasks arrive sequentially and robots are expected to acquire new coordination skills while reusing previously learned ones without catastrophic forgetting. To address this challenge, we propose Conquer, a semantic skill-library framework that formulates continual multi-quadruped coordination as a retrieve-adapt-update process. First, to accommodate varying team sizes across tasks, we design a team-structured Self-Allies-Goal (SAG) backbone that supports variable-cardinality robot teams by explicitly modeling each robot's own state, teammate context, and task goal. For each incoming task, Conquer constructs a task-level semantic descriptor from pre-execution information and retrieves a relevant skill from the library for adaptation. After successful execution, Conquer updates the skill library by extracting trajectory-level semantic descriptors and organizing them according to semantic distance, thereby enabling continual skill accumulation and cross-task knowledge transfer. Simulation experiments show that Conquer achieves a final average success rate of 95.6%, demonstrating strong forward transfer and negligible catastrophic forgetting. Real-world rollouts on Unitree Go2 teams further validate the deployment feasibility of Conquer for practical multi-quadruped coordination. Simulation and real-robot demonstration videos are available at: https://conquer-project.pages.dev/.
OmniXtreme: Breaking the Generality Barrier in High-Dynamic Humanoid Control
Feb 27, 2026High-fidelity motion tracking serves as the ultimate litmus test for generalizable, human-level motor skills. However, current policies often hit a "generality barrier": as motion libraries scale in diversity, tracking fidelity inevitably collapses - especially for real-world deployment of high-dynamic motions. We identify this failure as the result of two compounding factors: the learning bottleneck in scaling multi-motion optimization and the physical executability constraints that arise in real-world actuation. To overcome these challenges, we introduce OmniXtreme, a scalable framework that decouples general motor skill learning from sim-to-real physical skill refinement. Our approach uses a flow-matching policy with high-capacity architectures to scale representation capacity without interference-intensive multi-motion RL optimization, followed by an actuation-aware refinement phase that ensures robust performance on physical hardware. Extensive experiments demonstrate that OmniXtreme maintains high-fidelity tracking across diverse, high-difficulty datasets. On real robots, the unified policy successfully executes multiple extreme motions, effectively breaking the long-standing fidelity-scalability trade-off in high-dynamic humanoid control.
SegEarth-R2: Towards Comprehensive Language-guided Segmentation for Remote Sensing Images
Dec 23, 2025Effectively grounding complex language to pixels in remote sensing (RS) images is a critical challenge for applications like disaster response and environmental monitoring. Current models can parse simple, single-target commands but fail when presented with complex geospatial scenarios, e.g., segmenting objects at various granularities, executing multi-target instructions, and interpreting implicit user intent. To drive progress against these failures, we present LaSeRS, the first large-scale dataset built for comprehensive training and evaluation across four critical dimensions of language-guided segmentation: hierarchical granularity, target multiplicity, reasoning requirements, and linguistic variability. By capturing these dimensions, LaSeRS moves beyond simple commands, providing a benchmark for complex geospatial reasoning. This addresses a critical gap: existing datasets oversimplify, leading to sensitivity-prone real-world models. We also propose SegEarth-R2, an MLLM architecture designed for comprehensive language-guided segmentation in RS, which directly confronts these challenges. The model's effectiveness stems from two key improvements: (1) a spatial attention supervision mechanism specifically handles the localization of small objects and their components, and (2) a flexible and efficient segmentation query mechanism that handles both single-target and multi-target scenarios. Experimental results demonstrate that our SegEarth-R2 achieves outstanding performance on LaSeRS and other benchmarks, establishing a powerful baseline for the next generation of geospatial segmentation. All data and code will be released at https://github.com/earth-insights/SegEarth-R2.
Self-motion as a structural prior for coherent and robust formation of cognitive maps
Dec 23, 2025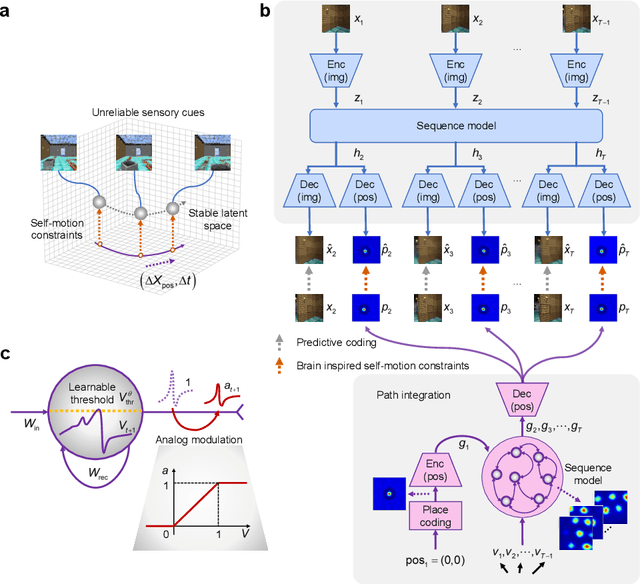
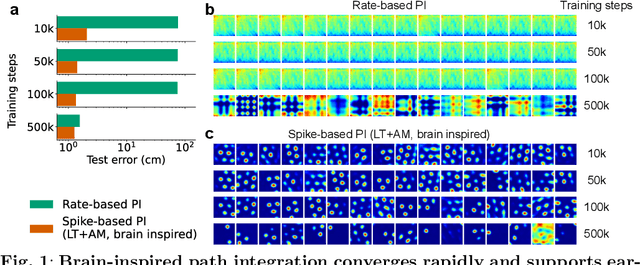
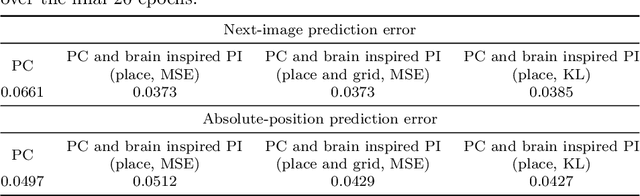
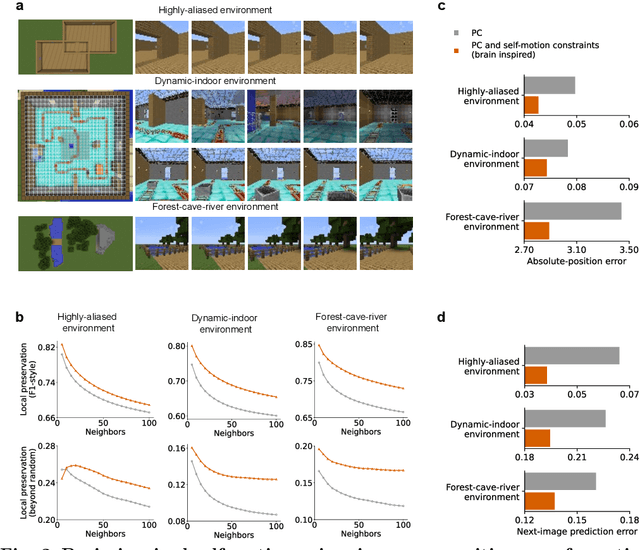
Most computational accounts of cognitive maps assume that stability is achieved primarily through sensory anchoring, with self-motion contributing to incremental positional updates only. However, biological spatial representations often remain coherent even when sensory cues degrade or conflict, suggesting that self-motion may play a deeper organizational role. Here, we show that self-motion can act as a structural prior that actively organizes the geometry of learned cognitive maps. We embed a path-integration-based motion prior in a predictive-coding framework, implemented using a capacity-efficient, brain-inspired recurrent mechanism combining spiking dynamics, analog modulation and adaptive thresholds. Across highly aliased, dynamically changing and naturalistic environments, this structural prior consistently stabilizes map formation, improving local topological fidelity, global positional accuracy and next-step prediction under sensory ambiguity. Mechanistic analyses reveal that the motion prior itself encodes geometrically precise trajectories under tight constraints of internal states and generalizes zero-shot to unseen environments, outperforming simpler motion-based constraints. Finally, deployment on a quadrupedal robot demonstrates that motion-derived structural priors enhance online landmark-based navigation under real-world sensory variability. Together, these results reframe self-motion as an organizing scaffold for coherent spatial representations, showing how brain-inspired principles can systematically strengthen spatial intelligence in embodied artificial agents.
A Recurrent Spiking Network with Hierarchical Intrinsic Excitability Modulation for Schema Learning
Jan 24, 2025Schema, a form of structured knowledge that promotes transfer learning, is attracting growing attention in both neuroscience and artificial intelligence (AI). Current schema research in neural computation is largely constrained to a single behavioral paradigm and relies heavily on recurrent neural networks (RNNs) which lack the neural plausibility and biological interpretability. To address these limitations, this work first constructs a generalized behavioral paradigm framework for schema learning and introduces three novel cognitive tasks, thus supporting a comprehensive schema exploration. Second, we propose a new model using recurrent spiking neural networks with hierarchical intrinsic excitability modulation (HM-RSNNs). The top level of the model selects excitability properties for task-specific demands, while the bottom level fine-tunes these properties for intra-task problems. Finally, extensive visualization analyses of HM-RSNNs are conducted to showcase their computational advantages, track the intrinsic excitability evolution during schema learning, and examine neural coordination differences across tasks. Biologically inspired lesion studies further uncover task-specific distributions of intrinsic excitability within schemas. Experimental results show that HM-RSNNs significantly outperform RSNN baselines across all tasks and exceed RNNs in three novel cognitive tasks. Additionally, HM-RSNNs offer deeper insights into neural dynamics underlying schema learning.
On Centralized Critics in Multi-Agent Reinforcement Learning
Aug 26, 2024



Centralized Training for Decentralized Execution where agents are trained offline in a centralized fashion and execute online in a decentralized manner, has become a popular approach in Multi-Agent Reinforcement Learning (MARL). In particular, it has become popular to develop actor-critic methods that train decentralized actors with a centralized critic where the centralized critic is allowed access global information of the entire system, including the true system state. Such centralized critics are possible given offline information and are not used for online execution. While these methods perform well in a number of domains and have become a de facto standard in MARL, using a centralized critic in this context has yet to be sufficiently analyzed theoretically or empirically. In this paper, we therefore formally analyze centralized and decentralized critic approaches, and analyze the effect of using state-based critics in partially observable environments. We derive theories contrary to the common intuition: critic centralization is not strictly beneficial, and using state values can be harmful. We further prove that, in particular, state-based critics can introduce unexpected bias and variance compared to history-based critics. Finally, we demonstrate how the theory applies in practice by comparing different forms of critics on a wide range of common multi-agent benchmarks. The experiments show practical issues such as the difficulty of representation learning with partial observability, which highlights why the theoretical problems are often overlooked in the literature.
O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
Oct 22, 2023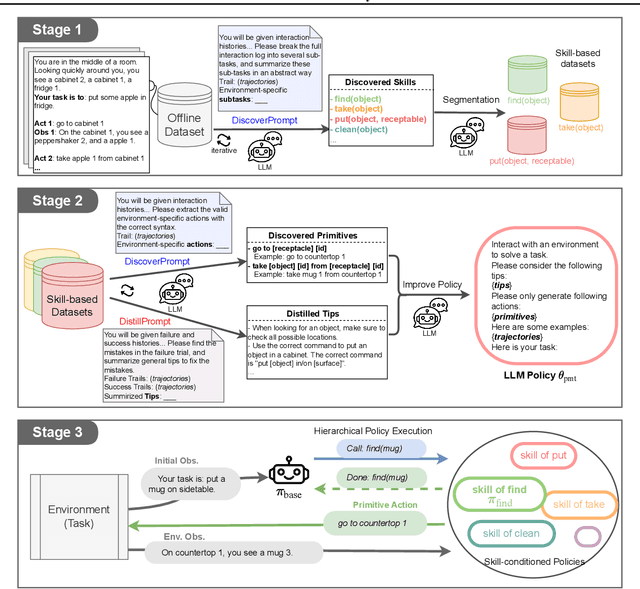
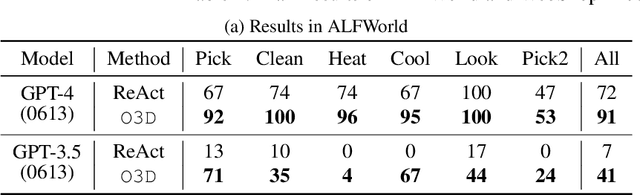
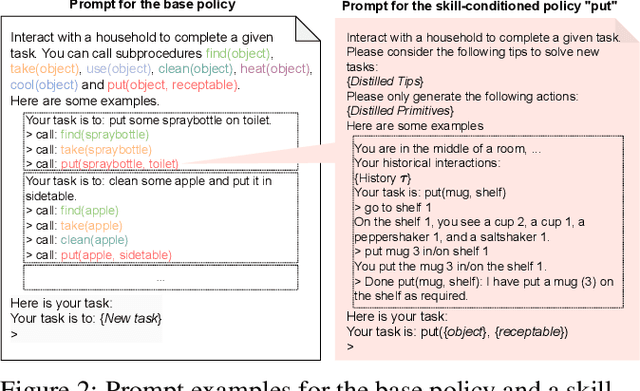

Recent advancements in large language models (LLMs) have exhibited promising performance in solving sequential decision-making problems. By imitating few-shot examples provided in the prompts (i.e., in-context learning), an LLM agent can interact with an external environment and complete given tasks without additional training. However, such few-shot examples are often insufficient to generate high-quality solutions for complex and long-horizon tasks, while the limited context length cannot consume larger-scale demonstrations. To this end, we propose an offline learning framework that utilizes offline data at scale (e.g, logs of human interactions) to facilitate the in-context learning performance of LLM agents. We formally define LLM-powered policies with both text-based approaches and code-based approaches. We then introduce an Offline Data-driven Discovery and Distillation (O3D) framework to improve LLM-powered policies without finetuning. O3D automatically discovers reusable skills and distills generalizable knowledge across multiple tasks based on offline interaction data, advancing the capability of solving downstream tasks. Empirical results under two interactive decision-making benchmarks (ALFWorld and WebShop) demonstrate that O3D can notably enhance the decision-making capabilities of LLMs through the offline discovery and distillation process, and consistently outperform baselines across various LLMs with both text-based-policy and code-based-policy.
On-Robot Bayesian Reinforcement Learning for POMDPs
Jul 22, 2023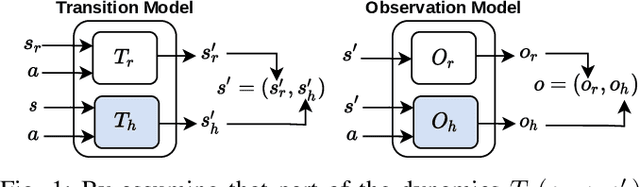
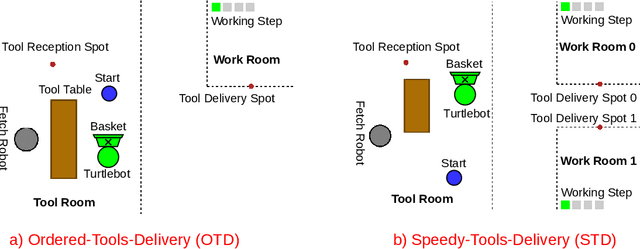

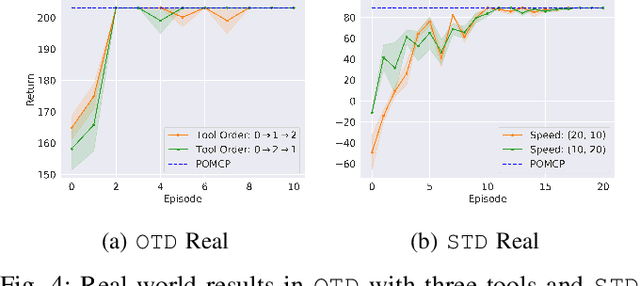
Robot learning is often difficult due to the expense of gathering data. The need for large amounts of data can, and should, be tackled with effective algorithms and leveraging expert information on robot dynamics. Bayesian reinforcement learning (BRL), thanks to its sample efficiency and ability to exploit prior knowledge, is uniquely positioned as such a solution method. Unfortunately, the application of BRL has been limited due to the difficulties of representing expert knowledge as well as solving the subsequent inference problem. This paper advances BRL for robotics by proposing a specialized framework for physical systems. In particular, we capture this knowledge in a factored representation, then demonstrate the posterior factorizes in a similar shape, and ultimately formalize the model in a Bayesian framework. We then introduce a sample-based online solution method, based on Monte-Carlo tree search and particle filtering, specialized to solve the resulting model. This approach can, for example, utilize typical low-level robot simulators and handle uncertainty over unknown dynamics of the environment. We empirically demonstrate its efficiency by performing on-robot learning in two human-robot interaction tasks with uncertainty about human behavior, achieving near-optimal performance after only a handful of real-world episodes. A video of learned policies is at https://youtu.be/H9xp60ngOes.
Sequential Fair Resource Allocation under a Markov Decision Process Framework
Jan 10, 2023



We study the sequential decision-making problem of allocating a limited resource to agents that reveal their stochastic demands on arrival over a finite horizon. Our goal is to design fair allocation algorithms that exhaust the available resource budget. This is challenging in sequential settings where information on future demands is not available at the time of decision-making. We formulate the problem as a discrete time Markov decision process (MDP). We propose a new algorithm, SAFFE, that makes fair allocations with respect to the entire demands revealed over the horizon by accounting for expected future demands at each arrival time. The algorithm introduces regularization which enables the prioritization of current revealed demands over future potential demands depending on the uncertainty in agents' future demands. Using the MDP formulation, we show that SAFFE optimizes allocations based on an upper bound on the Nash Social Welfare fairness objective, and we bound its gap to optimality with the use of concentration bounds on total future demands. Using synthetic and real data, we compare the performance of SAFFE against existing approaches and a reinforcement learning policy trained on the MDP. We show that SAFFE leads to more fair and efficient allocations and achieves close-to-optimal performance in settings with dense arrivals.
Macro-Action-Based Multi-Agent/Robot Deep Reinforcement Learning under Partial Observability
Oct 11, 2022
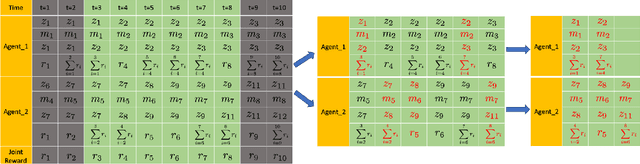
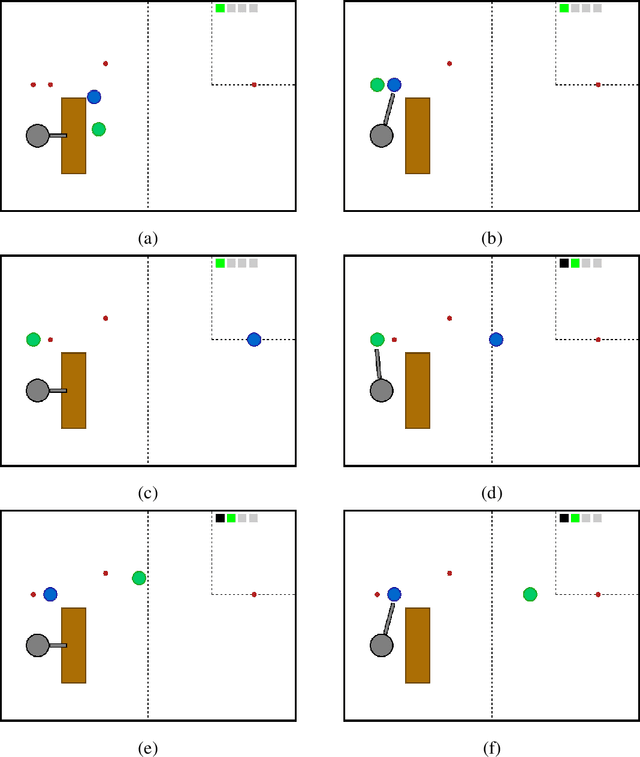
The state-of-the-art multi-agent reinforcement learning (MARL) methods have provided promising solutions to a variety of complex problems. Yet, these methods all assume that agents perform synchronized primitive-action executions so that they are not genuinely scalable to long-horizon real-world multi-agent/robot tasks that inherently require agents/robots to asynchronously reason about high-level action selection at varying time durations. The Macro-Action Decentralized Partially Observable Markov Decision Process (MacDec-POMDP) is a general formalization for asynchronous decision-making under uncertainty in fully cooperative multi-agent tasks. In this thesis, we first propose a group of value-based RL approaches for MacDec-POMDPs, where agents are allowed to perform asynchronous learning and decision-making with macro-action-value functions in three paradigms: decentralized learning and control, centralized learning and control, and centralized training for decentralized execution (CTDE). Building on the above work, we formulate a set of macro-action-based policy gradient algorithms under the three training paradigms, where agents are allowed to directly optimize their parameterized policies in an asynchronous manner. We evaluate our methods both in simulation and on real robots over a variety of realistic domains. Empirical results demonstrate the superiority of our approaches in large multi-agent problems and validate the effectiveness of our algorithms for learning high-quality and asynchronous solutions with macro-actions.