 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Risk Management Should Incorporate Both Safety and Security
May 29, 2024
The exposure of security vulnerabilities in safety-aligned language models, e.g., susceptibility to adversarial attacks, has shed light on the intricate interplay between AI safety and AI security. Although the two disciplines now come together under the overarching goal of AI risk management, they have historically evolved separately, giving rise to differing perspectives. Therefore, in this paper, we advocate that stakeholders in AI risk management should be aware of the nuances, synergies, and interplay between safety and security, and unambiguously take into account the perspectives of both disciplines in order to devise mostly effective and holistic risk mitigation approaches. Unfortunately, this vision is often obfuscated, as the definitions of the basic concepts of "safety" and "security" themselves are often inconsistent and lack consensus across communities. With AI risk management being increasingly cross-disciplinary, this issue is particularly salient. In light of this conceptual challenge, we introduce a unified reference framework to clarify the differences and interplay between AI safety and AI security, aiming to facilitate a shared understanding and effective collaboration across communities.
O3D: Offline Data-driven Discovery and Distillation for Sequential Decision-Making with Large Language Models
Oct 22, 2023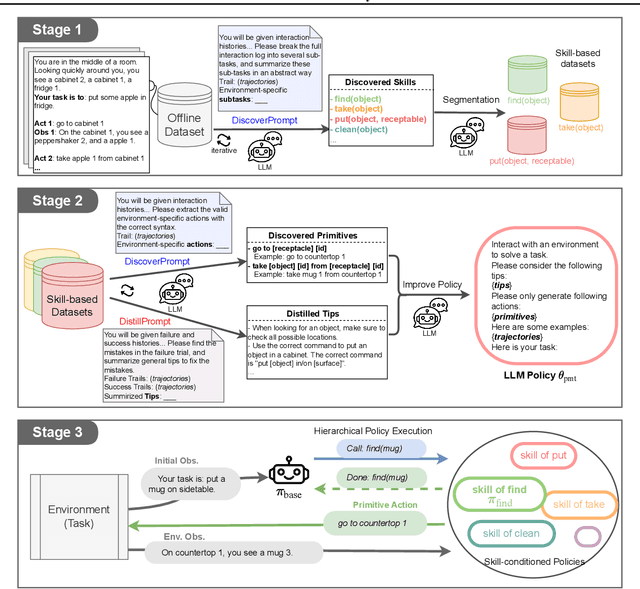
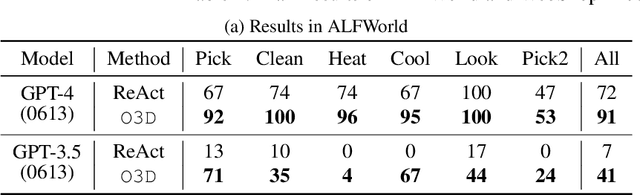
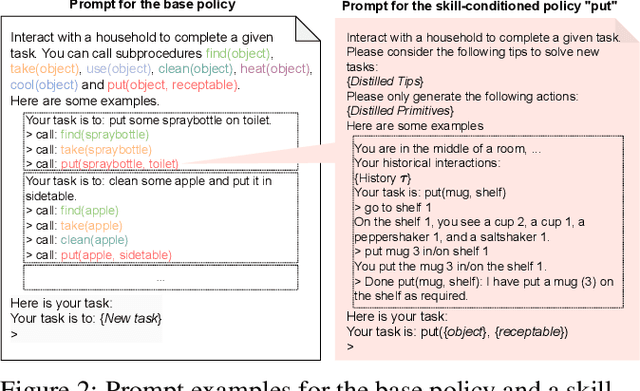

Recent advancements in large language models (LLMs) have exhibited promising performance in solving sequential decision-making problems. By imitating few-shot examples provided in the prompts (i.e., in-context learning), an LLM agent can interact with an external environment and complete given tasks without additional training. However, such few-shot examples are often insufficient to generate high-quality solutions for complex and long-horizon tasks, while the limited context length cannot consume larger-scale demonstrations. To this end, we propose an offline learning framework that utilizes offline data at scale (e.g, logs of human interactions) to facilitate the in-context learning performance of LLM agents. We formally define LLM-powered policies with both text-based approaches and code-based approaches. We then introduce an Offline Data-driven Discovery and Distillation (O3D) framework to improve LLM-powered policies without finetuning. O3D automatically discovers reusable skills and distills generalizable knowledge across multiple tasks based on offline interaction data, advancing the capability of solving downstream tasks. Empirical results under two interactive decision-making benchmarks (ALFWorld and WebShop) demonstrate that O3D can notably enhance the decision-making capabilities of LLMs through the offline discovery and distillation process, and consistently outperform baselines across various LLMs with both text-based-policy and code-based-policy.
Heterogeneous Social Value Orientation Leads to Meaningful Diversity in Sequential Social Dilemmas
May 01, 2023



In social psychology, Social Value Orientation (SVO) describes an individual's propensity to allocate resources between themself and others. In reinforcement learning, SVO has been instantiated as an intrinsic motivation that remaps an agent's rewards based on particular target distributions of group reward. Prior studies show that groups of agents endowed with heterogeneous SVO learn diverse policies in settings that resemble the incentive structure of Prisoner's dilemma. Our work extends this body of results and demonstrates that (1) heterogeneous SVO leads to meaningfully diverse policies across a range of incentive structures in sequential social dilemmas, as measured by task-specific diversity metrics; and (2) learning a best response to such policy diversity leads to better zero-shot generalization in some situations. We show that these best-response agents learn policies that are conditioned on their co-players, which we posit is the reason for improved zero-shot generalization results.
Melting Pot 2.0
Dec 13, 2022Multi-agent artificial intelligence research promises a path to develop intelligent technologies that are more human-like and more human-compatible than those produced by "solipsistic" approaches, which do not consider interactions between agents. Melting Pot is a research tool developed to facilitate work on multi-agent artificial intelligence, and provides an evaluation protocol that measures generalization to novel social partners in a set of canonical test scenarios. Each scenario pairs a physical environment (a "substrate") with a reference set of co-players (a "background population"), to create a social situation with substantial interdependence between the individuals involved. For instance, some scenarios were inspired by institutional-economics-based accounts of natural resource management and public-good-provision dilemmas. Others were inspired by considerations from evolutionary biology, game theory, and artificial life. Melting Pot aims to cover a maximally diverse set of interdependencies and incentives. It includes the commonly-studied extreme cases of perfectly-competitive (zero-sum) motivations and perfectly-cooperative (shared-reward) motivations, but does not stop with them. As in real-life, a clear majority of scenarios in Melting Pot have mixed incentives. They are neither purely competitive nor purely cooperative and thus demand successful agents be able to navigate the resulting ambiguity. Here we describe Melting Pot 2.0, which revises and expands on Melting Pot. We also introduce support for scenarios with asymmetric roles, and explain how to integrate them into the evaluation protocol. This report also contains: (1) details of all substrates and scenarios; (2) a complete description of all baseline algorithms and results. Our intention is for it to serve as a reference for researchers using Melting Pot 2.0.
A Regret Minimization Approach to Multi-Agent Control
Feb 01, 2022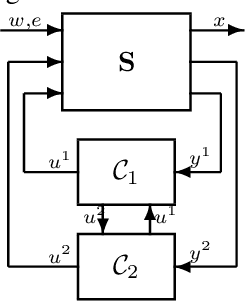
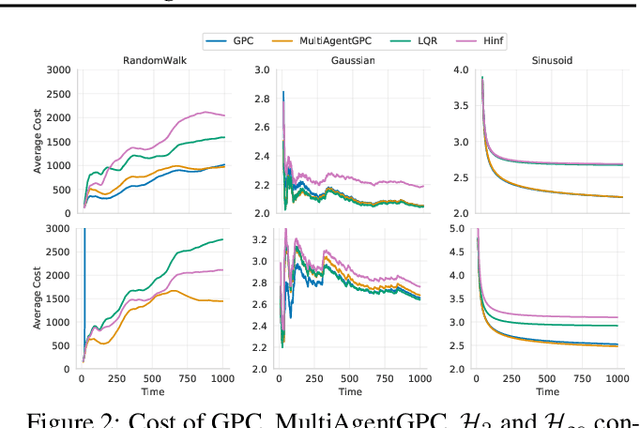
We study the problem of multi-agent control of a dynamical system with known dynamics and adversarial disturbances. Our study focuses on optimal control without centralized precomputed policies, but rather with adaptive control policies for the different agents that are only equipped with a stabilizing controller. We give a reduction from any (standard) regret minimizing control method to a distributed algorithm. The reduction guarantees that the resulting distributed algorithm has low regret relative to the optimal precomputed joint policy. Our methodology involves generalizing online convex optimization to a multi-agent setting and applying recent tools from nonstochastic control derived for a single agent. We empirically evaluate our method on a model of an overactuated aircraft. We show that the distributed method is robust to failure and to adversarial perturbations in the dynamics.
One More Step Towards Reality: Cooperative Bandits with Imperfect Communication
Nov 24, 2021


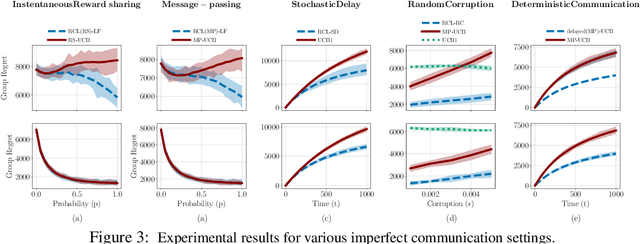
The cooperative bandit problem is increasingly becoming relevant due to its applications in large-scale decision-making. However, most research for this problem focuses exclusively on the setting with perfect communication, whereas in most real-world distributed settings, communication is often over stochastic networks, with arbitrary corruptions and delays. In this paper, we study cooperative bandit learning under three typical real-world communication scenarios, namely, (a) message-passing over stochastic time-varying networks, (b) instantaneous reward-sharing over a network with random delays, and (c) message-passing with adversarially corrupted rewards, including byzantine communication. For each of these environments, we propose decentralized algorithms that achieve competitive performance, along with near-optimal guarantees on the incurred group regret as well. Furthermore, in the setting with perfect communication, we present an improved delayed-update algorithm that outperforms the existing state-of-the-art on various network topologies. Finally, we present tight network-dependent minimax lower bounds on the group regret. Our proposed algorithms are straightforward to implement and obtain competitive empirical performance.
Provably Efficient Multi-Agent Reinforcement Learning with Fully Decentralized Communication
Oct 14, 2021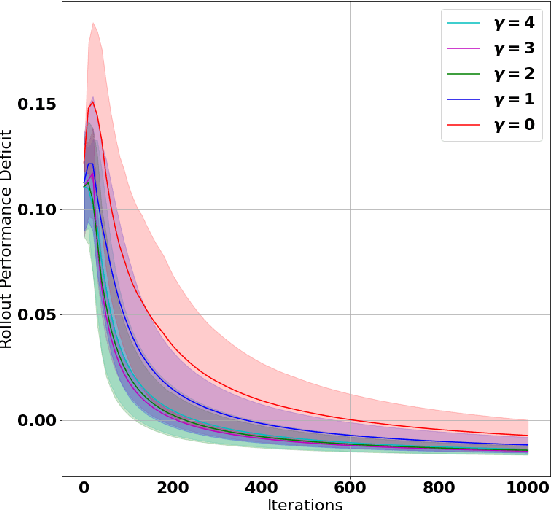
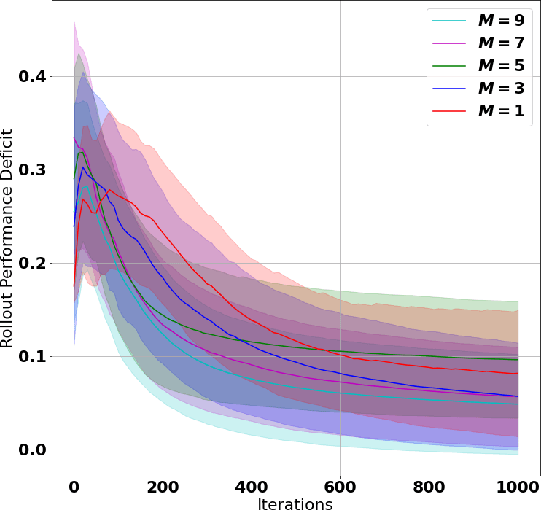
A challenge in reinforcement learning (RL) is minimizing the cost of sampling associated with exploration. Distributed exploration reduces sampling complexity in multi-agent RL (MARL). We investigate the benefits to performance in MARL when exploration is fully decentralized. Specifically, we consider a class of online, episodic, tabular $Q$-learning problems under time-varying reward and transition dynamics, in which agents can communicate in a decentralized manner.We show that group performance, as measured by the bound on regret, can be significantly improved through communication when each agent uses a decentralized message-passing protocol, even when limited to sending information up to its $\gamma$-hop neighbors. We prove regret and sample complexity bounds that depend on the number of agents, communication network structure and $\gamma.$ We show that incorporating more agents and more information sharing into the group learning scheme speeds up convergence to the optimal policy. Numerical simulations illustrate our results and validate our theoretical claims.
When to Call Your Neighbor? Strategic Communication in Cooperative Stochastic Bandits
Oct 08, 2021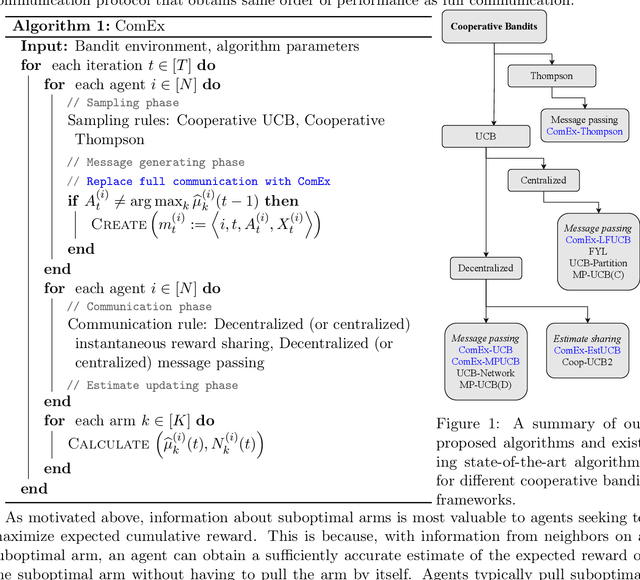
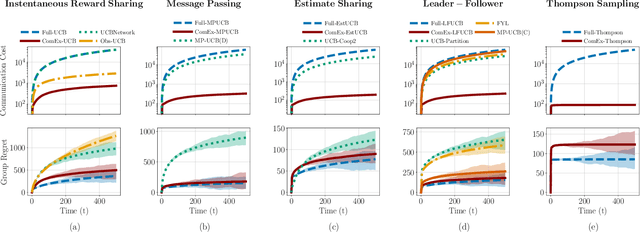
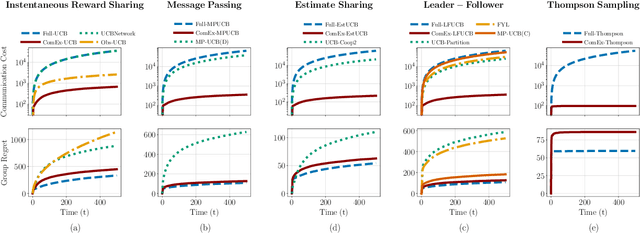
In cooperative bandits, a framework that captures essential features of collective sequential decision making, agents can minimize group regret, and thereby improve performance, by leveraging shared information. However, sharing information can be costly, which motivates developing policies that minimize group regret while also reducing the number of messages communicated by agents. Existing cooperative bandit algorithms obtain optimal performance when agents share information with their neighbors at \textit{every time step}, i.e., full communication. This requires $\Theta(T)$ number of messages, where $T$ is the time horizon of the decision making process. We propose \textit{ComEx}, a novel cost-effective communication protocol in which the group achieves the same order of performance as full communication while communicating only $O(\log T)$ number of messages. Our key step is developing a method to identify and only communicate the information crucial to achieving optimal performance. Further we propose novel algorithms for several benchmark cooperative bandit frameworks and show that our algorithms obtain \textit{state-of-the-art} performance while consistently incurring a significantly smaller communication cost than existing algorithms.
Hamiltonian Q-Learning: Leveraging Importance-sampling for Data Efficient RL
Dec 06, 2020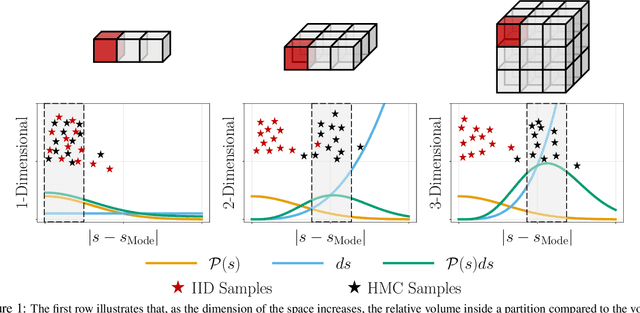
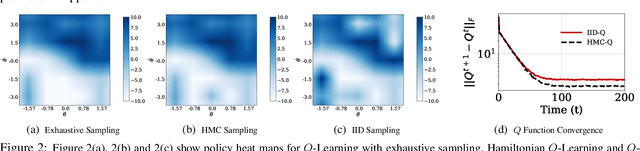
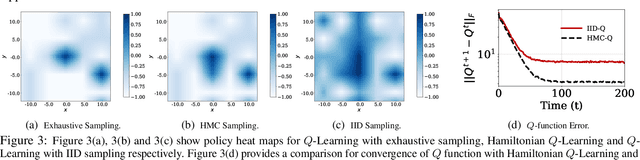
Model-free reinforcement learning (RL), in particular Q-learning is widely used to learn optimal policies for a variety of planning and control problems. However, when the underlying state-transition dynamics are stochastic and high-dimensional, Q-learning requires a large amount of data and incurs a prohibitively high computational cost. In this paper, we introduce Hamiltonian Q-Learning, a data efficient modification of the Q-learning approach, which adopts an importance-sampling based technique for computing the Q function. To exploit stochastic structure of the state-transition dynamics, we employ Hamiltonian Monte Carlo to update Q function estimates by approximating the expected future rewards using Q values associated with a subset of next states. Further, to exploit the latent low-rank structure of the dynamic system, Hamiltonian Q-Learning uses a matrix completion algorithm to reconstruct the updated Q function from Q value updates over a much smaller subset of state-action pairs. By providing an efficient way to apply Q-learning in stochastic, high-dimensional problems, the proposed approach broadens the scope of RL algorithms for real-world applications, including classical control tasks and environmental monitoring.
Distributed Bandits: Probabilistic Communication on $d$-regular Graphs
Nov 16, 2020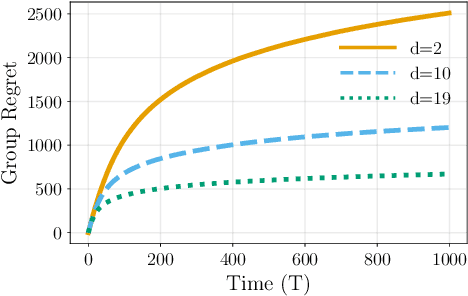
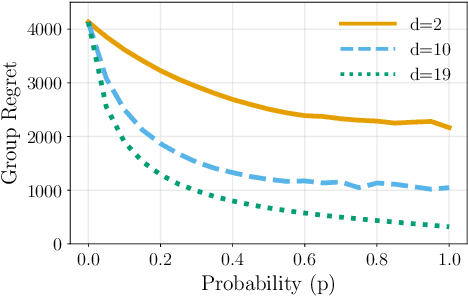
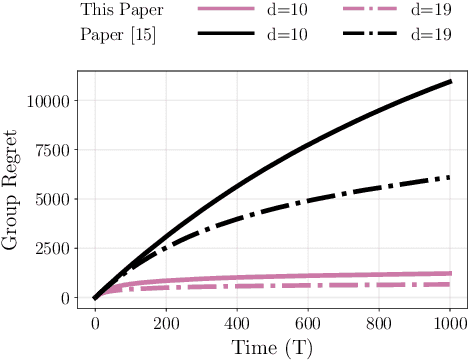
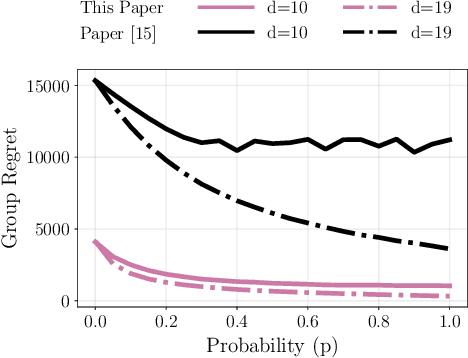
We study the decentralized multi-agent multi-armed bandit problem for agents that communicate with probability over a network defined by a $d$-regular graph. Every edge in the graph has probabilistic weight $p$ to account for the ($1\!-\!p$) probability of a communication link failure. At each time step, each agent chooses an arm and receives a numerical reward associated with the chosen arm. After each choice, each agent observes the last obtained reward of each of its neighbors with probability $p$. We propose a new Upper Confidence Bound (UCB) based algorithm and analyze how agent-based strategies contribute to minimizing group regret in this probabilistic communication setting. We provide theoretical guarantees that our algorithm outperforms state-of-the-art algorithms. We illustrate our results and validate the theoretical claims using numerical simulations.