 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Problem Generation for Reasoning via Quality-Diversity Algorithms
Jun 06, 2025Large language model (LLM) driven synthetic data generation has emerged as a powerful method for improving model reasoning capabilities. However, most methods either distill large state-of-the-art models into small students or use natural ground-truth problem statements to guarantee problem statement quality. This limits the scalability of these approaches to more complex and diverse problem domains. To address this, we present SPARQ: Synthetic Problem Generation for Reasoning via Quality-Diversity Algorithms, a novel approach for generating high-quality and diverse synthetic math problem and solution pairs using only a single model by measuring a problem's solve-rate: a proxy for problem difficulty. Starting from a seed dataset of 7.5K samples, we generate over 20 million new problem-solution pairs. We show that filtering the generated data by difficulty and then fine-tuning the same model on the resulting data improves relative model performance by up to 24\%. Additionally, we conduct ablations studying the impact of synthetic data quantity, quality and diversity on model generalization. We find that higher quality, as measured by problem difficulty, facilitates better in-distribution performance. Further, while generating diverse synthetic data does not as strongly benefit in-distribution performance, filtering for more diverse data facilitates more robust OOD generalization. We also confirm the existence of model and data scaling laws for synthetically generated problems, which positively benefit downstream model generalization.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Neural Contextual Reinforcement Framework for Logical Structure Language Generation
Jan 20, 2025


The Neural Contextual Reinforcement Framework introduces an innovative approach to enhancing the logical coherence and structural consistency of text generated by large language models. Leveraging reinforcement learning principles, the framework integrates custom reward functions and dynamic context alignment mechanisms to address challenges inherent in maintaining long-range dependencies across extended sequences. The architecture incorporates multi-head attention layers and hierarchical encoding modules, enabling the model to produce outputs that align closely with human expectations of logical structure and semantic flow. Quantitative evaluations across diverse datasets demonstrate substantial improvements in coherence metrics, perplexity reduction, and semantic alignment, showcasing the framework's ability to outperform baseline models in both general and domain-specific tasks. Qualitative analyses further highlight the framework's capacity to generate text with improved narrative clarity and reduced redundancy, reflecting its effectiveness in balancing fluency with structural precision. In addition to its performance gains, the framework exhibits robustness in handling noisy input data and scalability across varying model sizes, reinforcing its versatility in practical applications. Experimental results reveal that optimal context window sizes significantly influence coherence outcomes, showing the importance of architectural flexibility in adapting to diverse linguistic structures. Cross-lingual performance evaluations affirm the framework's adaptability to multiple languages, extending its utility beyond monolingual contexts. Resource efficiency analyses indicate a reduction in computational overhead compared to traditional approaches, emphasizing the practicality of the framework for large-scale deployment.
Cultural Evolution of Cooperation among LLM Agents
Dec 13, 2024



Large language models (LLMs) provide a compelling foundation for building generally-capable AI agents. These agents may soon be deployed at scale in the real world, representing the interests of individual humans (e.g., AI assistants) or groups of humans (e.g., AI-accelerated corporations). At present, relatively little is known about the dynamics of multiple LLM agents interacting over many generations of iterative deployment. In this paper, we examine whether a "society" of LLM agents can learn mutually beneficial social norms in the face of incentives to defect, a distinctive feature of human sociality that is arguably crucial to the success of civilization. In particular, we study the evolution of indirect reciprocity across generations of LLM agents playing a classic iterated Donor Game in which agents can observe the recent behavior of their peers. We find that the evolution of cooperation differs markedly across base models, with societies of Claude 3.5 Sonnet agents achieving significantly higher average scores than Gemini 1.5 Flash, which, in turn, outperforms GPT-4o. Further, Claude 3.5 Sonnet can make use of an additional mechanism for costly punishment to achieve yet higher scores, while Gemini 1.5 Flash and GPT-4o fail to do so. For each model class, we also observe variation in emergent behavior across random seeds, suggesting an understudied sensitive dependence on initial conditions. We suggest that our evaluation regime could inspire an inexpensive and informative new class of LLM benchmarks, focussed on the implications of LLM agent deployment for the cooperative infrastructure of society.
Open-Endedness is Essential for Artificial Superhuman Intelligence
Jun 06, 2024


In recent years there has been a tremendous surge in the general capabilities of AI systems, mainly fuelled by training foundation models on internetscale data. Nevertheless, the creation of openended, ever self-improving AI remains elusive. In this position paper, we argue that the ingredients are now in place to achieve openendedness in AI systems with respect to a human observer. Furthermore, we claim that such open-endedness is an essential property of any artificial superhuman intelligence (ASI). We begin by providing a concrete formal definition of open-endedness through the lens of novelty and learnability. We then illustrate a path towards ASI via open-ended systems built on top of foundation models, capable of making novel, humanrelevant discoveries. We conclude by examining the safety implications of generally-capable openended AI. We expect that open-ended foundation models will prove to be an increasingly fertile and safety-critical area of research in the near future.
Artificial Generational Intelligence: Cultural Accumulation in Reinforcement Learning
Jun 01, 2024



Cultural accumulation drives the open-ended and diverse progress in capabilities spanning human history. It builds an expanding body of knowledge and skills by combining individual exploration with inter-generational information transmission. Despite its widespread success among humans, the capacity for artificial learning agents to accumulate culture remains under-explored. In particular, approaches to reinforcement learning typically strive for improvements over only a single lifetime. Generational algorithms that do exist fail to capture the open-ended, emergent nature of cultural accumulation, which allows individuals to trade-off innovation and imitation. Building on the previously demonstrated ability for reinforcement learning agents to perform social learning, we find that training setups which balance this with independent learning give rise to cultural accumulation. These accumulating agents outperform those trained for a single lifetime with the same cumulative experience. We explore this accumulation by constructing two models under two distinct notions of a generation: episodic generations, in which accumulation occurs via in-context learning and train-time generations, in which accumulation occurs via in-weights learning. In-context and in-weights cultural accumulation can be interpreted as analogous to knowledge and skill accumulation, respectively. To the best of our knowledge, this work is the first to present general models that achieve emergent cultural accumulation in reinforcement learning, opening up new avenues towards more open-ended learning systems, as well as presenting new opportunities for modelling human culture.
Genie: Generative Interactive Environments
Feb 23, 2024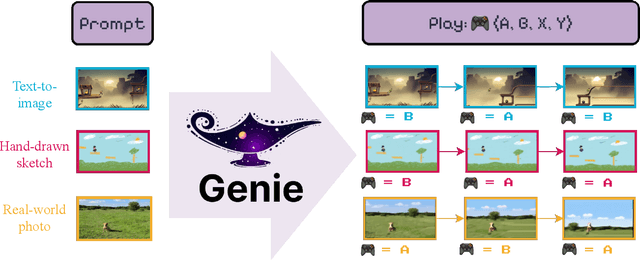
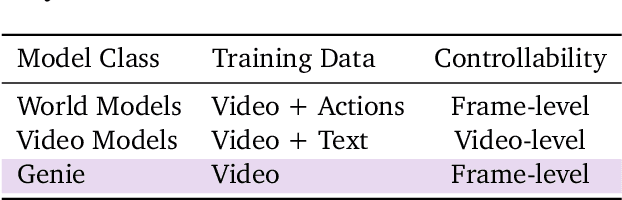
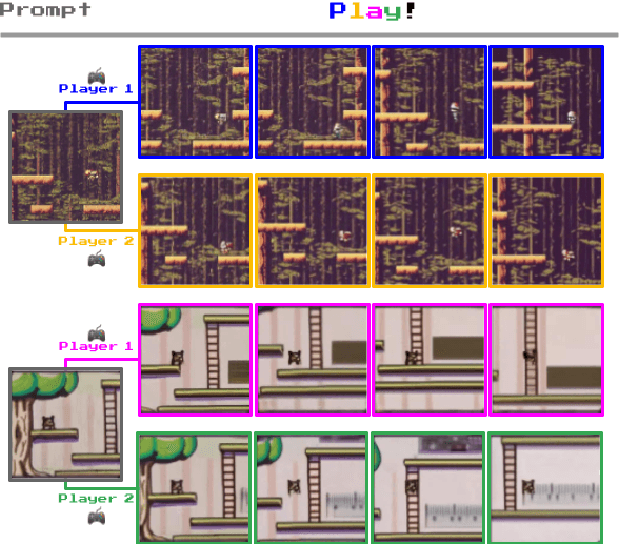
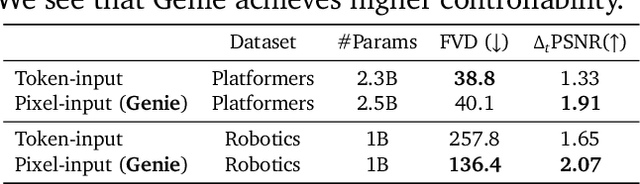
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Towards Zero Shot Learning in Restless Multi-armed Bandits
Oct 23, 2023



Restless multi-arm bandits (RMABs), a class of resource allocation problems with broad application in areas such as healthcare, online advertising, and anti-poaching, have recently been studied from a multi-agent reinforcement learning perspective. Prior RMAB research suffers from several limitations, e.g., it fails to adequately address continuous states, and requires retraining from scratch when arms opt-in and opt-out over time, a common challenge in many real world applications. We address these limitations by developing a neural network-based pre-trained model (PreFeRMAB) that has general zero-shot ability on a wide range of previously unseen RMABs, and which can be fine-tuned on specific instances in a more sample-efficient way than retraining from scratch. Our model also accommodates general multi-action settings and discrete or continuous state spaces. To enable fast generalization, we learn a novel single policy network model that utilizes feature information and employs a training procedure in which arms opt-in and out over time. We derive a new update rule for a crucial $\lambda$-network with theoretical convergence guarantees and empirically demonstrate the advantages of our approach on several challenging, real-world inspired problems.
Heterogeneous Social Value Orientation Leads to Meaningful Diversity in Sequential Social Dilemmas
May 01, 2023



In social psychology, Social Value Orientation (SVO) describes an individual's propensity to allocate resources between themself and others. In reinforcement learning, SVO has been instantiated as an intrinsic motivation that remaps an agent's rewards based on particular target distributions of group reward. Prior studies show that groups of agents endowed with heterogeneous SVO learn diverse policies in settings that resemble the incentive structure of Prisoner's dilemma. Our work extends this body of results and demonstrates that (1) heterogeneous SVO leads to meaningfully diverse policies across a range of incentive structures in sequential social dilemmas, as measured by task-specific diversity metrics; and (2) learning a best response to such policy diversity leads to better zero-shot generalization in some situations. We show that these best-response agents learn policies that are conditioned on their co-players, which we posit is the reason for improved zero-shot generalization results.
Human-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023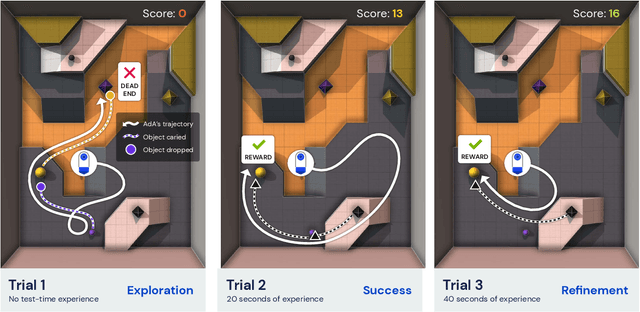
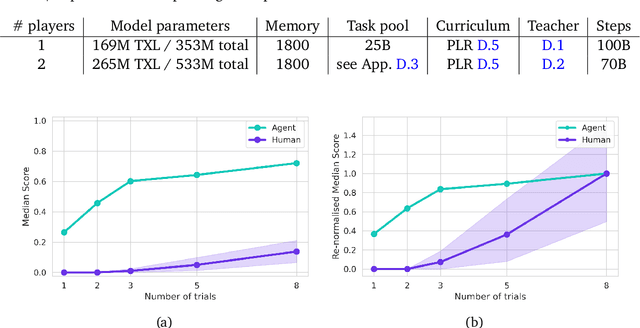
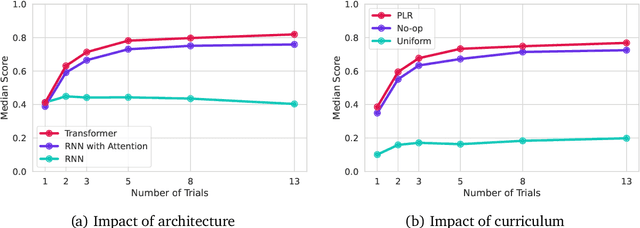
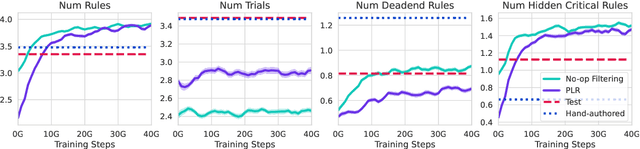
Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.