 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecisions and Deployment: The Five-Year SAHELI Project (2020-2025) on Restless Multi-Armed Bandits for Improving Maternal and Child Health
Apr 08, 2026Maternal and child health is a critical concern around the world. In many global health programs disseminating preventive care and health information, limited healthcare worker resources prevent continuous, personalised engagement with vulnerable beneficiaries. In such scenarios, it becomes crucial to optimally schedule limited live-service resources to maximise long-term engagement. To address this fundamental challenge, the multi-year SAHELI project (2020-2025), in collaboration with partner NGO ARMMAN, leverages AI to allocate scarce resources in a maternal and child health program in India. The SAHELI system solves this sequential resource allocation problem using a Restless Multi-Armed Bandit (RMAB) framework. A key methodological innovation is the transition from a traditional Two-Stage "predict-then-optimize" approach to Decision-Focused Learning (DFL), which directly aligns the framework's learning method with the ultimate goal of maximizing beneficiary engagement. Empirical evaluation through large-scale randomized controlled trials demonstrates that the DFL policy reduced cumulative engagement drops by 31% relative to the current standard of care, significantly outperforming the Two-Stage model. Crucially, the studies also confirmed that this increased program engagement translates directly into statistically significant improvements in real-world health behaviors, notably the continued consumption of vital iron and calcium supplements by new mothers. Ultimately, the SAHELI project provides a scalable blueprint for applying sequential decision-making AI to optimize resource allocation in health programs.
Beyond Listenership: AI-Predicted Interventions Drive Improvements in Maternal Health Behaviours
Jul 28, 2025Automated voice calls with health information are a proven method for disseminating maternal and child health information among beneficiaries and are deployed in several programs around the world. However, these programs often suffer from beneficiary dropoffs and poor engagement. In previous work, through real-world trials, we showed that an AI model, specifically a restless bandit model, could identify beneficiaries who would benefit most from live service call interventions, preventing dropoffs and boosting engagement. However, one key question has remained open so far: does such improved listenership via AI-targeted interventions translate into beneficiaries' improved knowledge and health behaviors? We present a first study that shows not only listenership improvements due to AI interventions, but also simultaneously links these improvements to health behavior changes. Specifically, we demonstrate that AI-scheduled interventions, which enhance listenership, lead to statistically significant improvements in beneficiaries' health behaviors such as taking iron or calcium supplements in the postnatal period, as well as understanding of critical health topics during pregnancy and infancy. This underscores the potential of AI to drive meaningful improvements in maternal and child health.
Towards Foundation-model-based Multiagent System to Accelerate AI for Social Impact
Dec 12, 2024
AI for social impact (AI4SI) offers significant potential for addressing complex societal challenges in areas such as public health, agriculture, education, conservation, and public safety. However, existing AI4SI research is often labor-intensive and resource-demanding, limiting its accessibility and scalability; the standard approach is to design a (base-level) system tailored to a specific AI4SI problem. We propose the development of a novel meta-level multi-agent system designed to accelerate the development of such base-level systems, thereby reducing the computational cost and the burden on social impact domain experts and AI researchers. Leveraging advancements in foundation models and large language models, our proposed approach focuses on resource allocation problems providing help across the full AI4SI pipeline from problem formulation over solution design to impact evaluation. We highlight the ethical considerations and challenges inherent in deploying such systems and emphasize the importance of a human-in-the-loop approach to ensure the responsible and effective application of AI systems.
IRL for Restless Multi-Armed Bandits with Applications in Maternal and Child Health
Dec 11, 2024Public health practitioners often have the goal of monitoring patients and maximizing patients' time spent in "favorable" or healthy states while being constrained to using limited resources. Restless multi-armed bandits (RMAB) are an effective model to solve this problem as they are helpful to allocate limited resources among many agents under resource constraints, where patients behave differently depending on whether they are intervened on or not. However, RMABs assume the reward function is known. This is unrealistic in many public health settings because patients face unique challenges and it is impossible for a human to know who is most deserving of any intervention at such a large scale. To address this shortcoming, this paper is the first to present the use of inverse reinforcement learning (IRL) to learn desired rewards for RMABs, and we demonstrate improved outcomes in a maternal and child health telehealth program. First we allow public health experts to specify their goals at an aggregate or population level and propose an algorithm to design expert trajectories at scale based on those goals. Second, our algorithm WHIRL uses gradient updates to optimize the objective, allowing for efficient and accurate learning of RMAB rewards. Third, we compare with existing baselines and outperform those in terms of run-time and accuracy. Finally, we evaluate and show the usefulness of WHIRL on thousands on beneficiaries from a real-world maternal and child health setting in India. We publicly release our code here: https://github.com/Gjain234/WHIRL.
Bayesian Collaborative Bandits with Thompson Sampling for Improved Outreach in Maternal Health Program
Oct 28, 2024



Mobile health (mHealth) programs face a critical challenge in optimizing the timing of automated health information calls to beneficiaries. This challenge has been formulated as a collaborative multi-armed bandit problem, requiring online learning of a low-rank reward matrix. Existing solutions often rely on heuristic combinations of offline matrix completion and exploration strategies. In this work, we propose a principled Bayesian approach using Thompson Sampling for this collaborative bandit problem. Our method leverages prior information through efficient Gibbs sampling for posterior inference over the low-rank matrix factors, enabling faster convergence. We demonstrate significant improvements over state-of-the-art baselines on a real-world dataset from the world's largest maternal mHealth program. Our approach achieves a $16\%$ reduction in the number of calls compared to existing methods and a $47$\% reduction compared to the deployed random policy. This efficiency gain translates to a potential increase in program capacity by $0.5-1.4$ million beneficiaries, granting them access to vital ante-natal and post-natal care information. Furthermore, we observe a $7\%$ and $29\%$ improvement in beneficiary retention (an extremely hard metric to impact) compared to state-of-the-art and deployed baselines, respectively. Synthetic simulations further demonstrate the superiority of our approach, particularly in low-data regimes and in effectively utilizing prior information. We also provide a theoretical analysis of our algorithm in a special setting using Eluder dimension.
The Bandit Whisperer: Communication Learning for Restless Bandits
Aug 11, 2024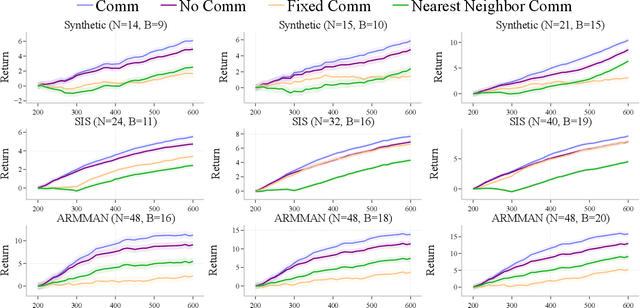
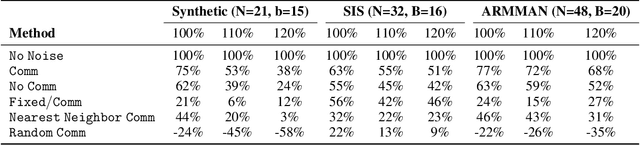
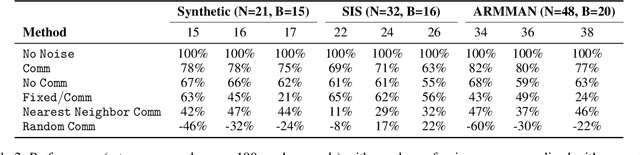
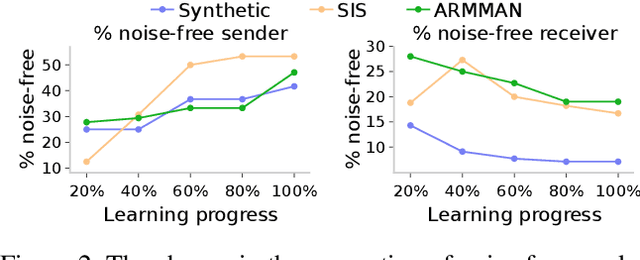
Applying Reinforcement Learning (RL) to Restless Multi-Arm Bandits (RMABs) offers a promising avenue for addressing allocation problems with resource constraints and temporal dynamics. However, classic RMAB models largely overlook the challenges of (systematic) data errors - a common occurrence in real-world scenarios due to factors like varying data collection protocols and intentional noise for differential privacy. We demonstrate that conventional RL algorithms used to train RMABs can struggle to perform well in such settings. To solve this problem, we propose the first communication learning approach in RMABs, where we study which arms, when involved in communication, are most effective in mitigating the influence of such systematic data errors. In our setup, the arms receive Q-function parameters from similar arms as messages to guide behavioral policies, steering Q-function updates. We learn communication strategies by considering the joint utility of messages across all pairs of arms and using a Q-network architecture that decomposes the joint utility. Both theoretical and empirical evidence validate the effectiveness of our method in significantly improving RMAB performance across diverse problems.
Efficient Public Health Intervention Planning Using Decomposition-Based Decision-Focused Learning
Mar 08, 2024



The declining participation of beneficiaries over time is a key concern in public health programs. A popular strategy for improving retention is to have health workers `intervene' on beneficiaries at risk of dropping out. However, the availability and time of these health workers are limited resources. As a result, there has been a line of research on optimizing these limited intervention resources using Restless Multi-Armed Bandits (RMABs). The key technical barrier to using this framework in practice lies in the need to estimate the beneficiaries' RMAB parameters from historical data. Recent research has shown that Decision-Focused Learning (DFL), which focuses on maximizing the beneficiaries' adherence rather than predictive accuracy, improves the performance of intervention targeting using RMABs. Unfortunately, these gains come at a high computational cost because of the need to solve and evaluate the RMAB in each DFL training step. In this paper, we provide a principled way to exploit the structure of RMABs to speed up intervention planning by cleverly decoupling the planning for different beneficiaries. We use real-world data from an Indian NGO, ARMMAN, to show that our approach is up to two orders of magnitude faster than the state-of-the-art approach while also yielding superior model performance. This would enable the NGO to scale up deployments using DFL to potentially millions of mothers, ultimately advancing progress toward UNSDG 3.1.
A Decision-Language Model (DLM) for Dynamic Restless Multi-Armed Bandit Tasks in Public Health
Feb 23, 2024Efforts to reduce maternal mortality rate, a key UN Sustainable Development target (SDG Target 3.1), rely largely on preventative care programs to spread critical health information to high-risk populations. These programs face two important challenges: efficiently allocating limited health resources to large beneficiary populations, and adapting to evolving policy priorities. While prior works in restless multi-armed bandit (RMAB) demonstrated success in public health allocation tasks, they lack flexibility to adapt to evolving policy priorities. Concurrently, Large Language Models (LLMs) have emerged as adept, automated planners in various domains, including robotic control and navigation. In this paper, we propose DLM: a Decision Language Model for RMABs. To enable dynamic fine-tuning of RMAB policies for challenging public health settings using human-language commands, we propose using LLMs as automated planners to (1) interpret human policy preference prompts, (2) propose code reward functions for a multi-agent RL environment for RMABs, and (3) iterate on the generated reward using feedback from RMAB simulations to effectively adapt policy outcomes. In collaboration with ARMMAN, an India-based public health organization promoting preventative care for pregnant mothers, we conduct a simulation study, showing DLM can dynamically shape policy outcomes using only human language commands as input.
Evaluating the Effectiveness of Index-Based Treatment Allocation
Feb 19, 2024When resources are scarce, an allocation policy is needed to decide who receives a resource. This problem occurs, for instance, when allocating scarce medical resources and is often solved using modern ML methods. This paper introduces methods to evaluate index-based allocation policies -- that allocate a fixed number of resources to those who need them the most -- by using data from a randomized control trial. Such policies create dependencies between agents, which render the assumptions behind standard statistical tests invalid and limit the effectiveness of estimators. Addressing these challenges, we translate and extend recent ideas from the statistics literature to present an efficient estimator and methods for computing asymptotically correct confidence intervals. This enables us to effectively draw valid statistical conclusions, a critical gap in previous work. Our extensive experiments validate our methodology in practical settings, while also showcasing its statistical power. We conclude by proposing and empirically verifying extensions of our methodology that enable us to reevaluate a past randomized control trial to evaluate different ML allocation policies in the context of a mHealth program, drawing previously invisible conclusions.
A Bayesian Approach to Online Learning for Contextual Restless Bandits with Applications to Public Health
Feb 07, 2024



Restless multi-armed bandits (RMABs) are used to model sequential resource allocation in public health intervention programs. In these settings, the underlying transition dynamics are often unknown a priori, requiring online reinforcement learning (RL). However, existing methods in online RL for RMABs cannot incorporate properties often present in real-world public health applications, such as contextual information and non-stationarity. We present Bayesian Learning for Contextual RMABs (BCoR), an online RL approach for RMABs that novelly combines techniques in Bayesian modeling with Thompson sampling to flexibly model a wide range of complex RMAB settings, such as contextual and non-stationary RMABs. A key contribution of our approach is its ability to leverage shared information within and between arms to learn unknown RMAB transition dynamics quickly in budget-constrained settings with relatively short time horizons. Empirically, we show that BCoR achieves substantially higher finite-sample performance than existing approaches over a range of experimental settings, including one constructed from a real-world public health campaign in India.