 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Foundation-model-based Multiagent System to Accelerate AI for Social Impact
Dec 12, 2024
AI for social impact (AI4SI) offers significant potential for addressing complex societal challenges in areas such as public health, agriculture, education, conservation, and public safety. However, existing AI4SI research is often labor-intensive and resource-demanding, limiting its accessibility and scalability; the standard approach is to design a (base-level) system tailored to a specific AI4SI problem. We propose the development of a novel meta-level multi-agent system designed to accelerate the development of such base-level systems, thereby reducing the computational cost and the burden on social impact domain experts and AI researchers. Leveraging advancements in foundation models and large language models, our proposed approach focuses on resource allocation problems providing help across the full AI4SI pipeline from problem formulation over solution design to impact evaluation. We highlight the ethical considerations and challenges inherent in deploying such systems and emphasize the importance of a human-in-the-loop approach to ensure the responsible and effective application of AI systems.
Optimizing Vital Sign Monitoring in Resource-Constrained Maternal Care: An RL-Based Restless Bandit Approach
Oct 10, 2024

Maternal mortality remains a significant global public health challenge. One promising approach to reducing maternal deaths occurring during facility-based childbirth is through early warning systems, which require the consistent monitoring of mothers' vital signs after giving birth. Wireless vital sign monitoring devices offer a labor-efficient solution for continuous monitoring, but their scarcity raises the critical question of how to allocate them most effectively. We devise an allocation algorithm for this problem by modeling it as a variant of the popular Restless Multi-Armed Bandit (RMAB) paradigm. In doing so, we identify and address novel, previously unstudied constraints unique to this domain, which render previous approaches for RMABs unsuitable and significantly increase the complexity of the learning and planning problem. To overcome these challenges, we adopt the popular Proximal Policy Optimization (PPO) algorithm from reinforcement learning to learn an allocation policy by training a policy and value function network. We demonstrate in simulations that our approach outperforms the best heuristic baseline by up to a factor of $4$.
Improving the Prediction of Individual Engagement in Recommendations Using Cognitive Models
Sep 03, 2024



For public health programs with limited resources, the ability to predict how behaviors change over time and in response to interventions is crucial for deciding when and to whom interventions should be allocated. Using data from a real-world maternal health program, we demonstrate how a cognitive model based on Instance-Based Learning (IBL) Theory can augment existing purely computational approaches. Our findings show that, compared to general time-series forecasters (e.g., LSTMs), IBL models, which reflect human decision-making processes, better predict the dynamics of individuals' states. Additionally, IBL provides estimates of the volatility in individuals' states and their sensitivity to interventions, which can improve the efficiency of training of other time series models.
The Bandit Whisperer: Communication Learning for Restless Bandits
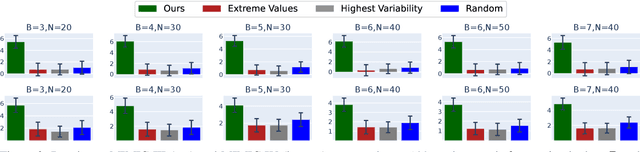
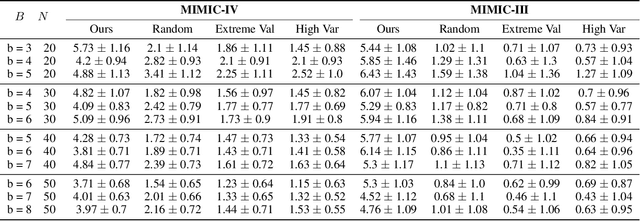
Aug 11, 2024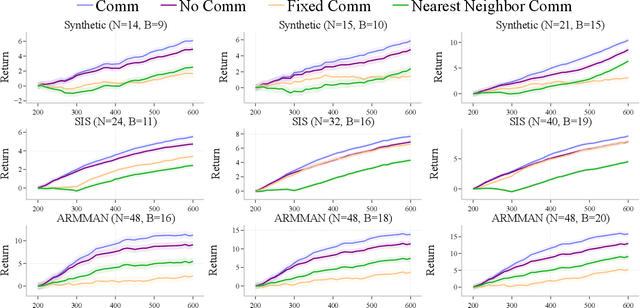
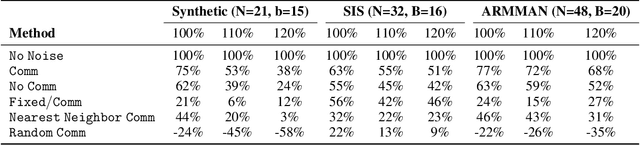
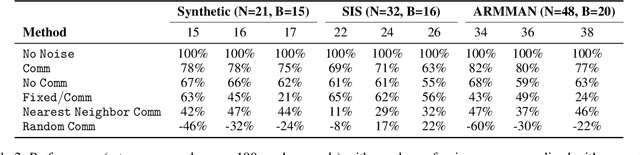
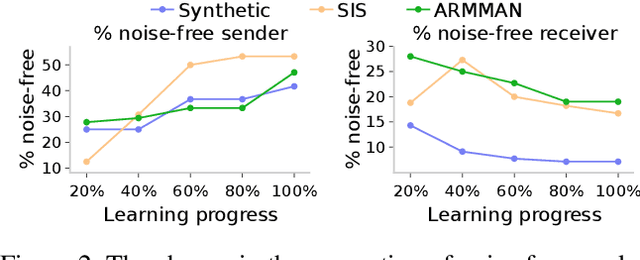
Applying Reinforcement Learning (RL) to Restless Multi-Arm Bandits (RMABs) offers a promising avenue for addressing allocation problems with resource constraints and temporal dynamics. However, classic RMAB models largely overlook the challenges of (systematic) data errors - a common occurrence in real-world scenarios due to factors like varying data collection protocols and intentional noise for differential privacy. We demonstrate that conventional RL algorithms used to train RMABs can struggle to perform well in such settings. To solve this problem, we propose the first communication learning approach in RMABs, where we study which arms, when involved in communication, are most effective in mitigating the influence of such systematic data errors. In our setup, the arms receive Q-function parameters from similar arms as messages to guide behavioral policies, steering Q-function updates. We learn communication strategies by considering the joint utility of messages across all pairs of arms and using a Q-network architecture that decomposes the joint utility. Both theoretical and empirical evidence validate the effectiveness of our method in significantly improving RMAB performance across diverse problems.
A Decision-Language Model (DLM) for Dynamic Restless Multi-Armed Bandit Tasks in Public Health
Feb 23, 2024Efforts to reduce maternal mortality rate, a key UN Sustainable Development target (SDG Target 3.1), rely largely on preventative care programs to spread critical health information to high-risk populations. These programs face two important challenges: efficiently allocating limited health resources to large beneficiary populations, and adapting to evolving policy priorities. While prior works in restless multi-armed bandit (RMAB) demonstrated success in public health allocation tasks, they lack flexibility to adapt to evolving policy priorities. Concurrently, Large Language Models (LLMs) have emerged as adept, automated planners in various domains, including robotic control and navigation. In this paper, we propose DLM: a Decision Language Model for RMABs. To enable dynamic fine-tuning of RMAB policies for challenging public health settings using human-language commands, we propose using LLMs as automated planners to (1) interpret human policy preference prompts, (2) propose code reward functions for a multi-agent RL environment for RMABs, and (3) iterate on the generated reward using feedback from RMAB simulations to effectively adapt policy outcomes. In collaboration with ARMMAN, an India-based public health organization promoting preventative care for pregnant mothers, we conduct a simulation study, showing DLM can dynamically shape policy outcomes using only human language commands as input.
Towards Zero Shot Learning in Restless Multi-armed Bandits
Oct 23, 2023



Restless multi-arm bandits (RMABs), a class of resource allocation problems with broad application in areas such as healthcare, online advertising, and anti-poaching, have recently been studied from a multi-agent reinforcement learning perspective. Prior RMAB research suffers from several limitations, e.g., it fails to adequately address continuous states, and requires retraining from scratch when arms opt-in and opt-out over time, a common challenge in many real world applications. We address these limitations by developing a neural network-based pre-trained model (PreFeRMAB) that has general zero-shot ability on a wide range of previously unseen RMABs, and which can be fine-tuned on specific instances in a more sample-efficient way than retraining from scratch. Our model also accommodates general multi-action settings and discrete or continuous state spaces. To enable fast generalization, we learn a novel single policy network model that utilizes feature information and employs a training procedure in which arms opt-in and out over time. We derive a new update rule for a crucial $\lambda$-network with theoretical convergence guarantees and empirically demonstrate the advantages of our approach on several challenging, real-world inspired problems.
Scalable Neural Network Kernels
Oct 20, 2023



We introduce the concept of scalable neural network kernels (SNNKs), the replacements of regular feedforward layers (FFLs), capable of approximating the latter, but with favorable computational properties. SNNKs effectively disentangle the inputs from the parameters of the neural network in the FFL, only to connect them in the final computation via the dot-product kernel. They are also strictly more expressive, as allowing to model complicated relationships beyond the functions of the dot-products of parameter-input vectors. We also introduce the neural network bundling process that applies SNNKs to compactify deep neural network architectures, resulting in additional compression gains. In its extreme version, it leads to the fully bundled network whose optimal parameters can be expressed via explicit formulae for several loss functions (e.g. mean squared error), opening a possibility to bypass backpropagation. As a by-product of our analysis, we introduce the mechanism of the universal random features (or URFs), applied to instantiate several SNNK variants, and interesting on its own in the context of scalable kernel methods. We provide rigorous theoretical analysis of all these concepts as well as an extensive empirical evaluation, ranging from point-wise kernel estimation to Transformers' fine-tuning with novel adapter layers inspired by SNNKs. Our mechanism provides up to 5x reduction in the number of trainable parameters, while maintaining competitive accuracy.
Estimate-Then-Optimize Versus Integrated-Estimation-Optimization: A Stochastic Dominance Perspective
Apr 13, 2023



In data-driven stochastic optimization, model parameters of the underlying distribution need to be estimated from data in addition to the optimization task. Recent literature suggests the integration of the estimation and optimization processes, by selecting model parameters that lead to the best empirical objective performance. Such an integrated approach can be readily shown to outperform simple ``estimate then optimize" when the model is misspecified. In this paper, we argue that when the model class is rich enough to cover the ground truth, the performance ordering between the two approaches is reversed for nonlinear problems in a strong sense. Simple ``estimate then optimize" outperforms the integrated approach in terms of stochastic dominance of the asymptotic optimality gap, i,e, the mean, all other moments, and the entire asymptotic distribution of the optimality gap is always better. Analogous results also hold under constrained settings and when contextual features are available. We also provide experimental findings to support our theory.
Balanced Off-Policy Evaluation for Personalized Pricing
Feb 24, 2023



We consider a personalized pricing problem in which we have data consisting of feature information, historical pricing decisions, and binary realized demand. The goal is to perform off-policy evaluation for a new personalized pricing policy that maps features to prices. Methods based on inverse propensity weighting (including doubly robust methods) for off-policy evaluation may perform poorly when the logging policy has little exploration or is deterministic, which is common in pricing applications. Building on the balanced policy evaluation framework of Kallus (2018), we propose a new approach tailored to pricing applications. The key idea is to compute an estimate that minimizes the worst-case mean squared error or maximizes a worst-case lower bound on policy performance, where in both cases the worst-case is taken with respect to a set of possible revenue functions. We establish theoretical convergence guarantees and empirically demonstrate the advantage of our approach using a real-world pricing dataset.
Efficient Graph Field Integrators Meet Point Clouds
Feb 05, 2023



We present two new classes of algorithms for efficient field integration on graphs encoding point clouds. The first class, SeparatorFactorization(SF), leverages the bounded genus of point cloud mesh graphs, while the second class, RFDiffusion(RFD), uses popular epsilon-nearest-neighbor graph representations for point clouds. Both can be viewed as providing the functionality of Fast Multipole Methods (FMMs), which have had a tremendous impact on efficient integration, but for non-Euclidean spaces. We focus on geometries induced by distributions of walk lengths between points (e.g., shortest-path distance). We provide an extensive theoretical analysis of our algorithms, obtaining new results in structural graph theory as a byproduct. We also perform exhaustive empirical evaluation, including on-surface interpolation for rigid and deformable objects (particularly for mesh-dynamics modeling), Wasserstein distance computations for point clouds, and the Gromov-Wasserstein variant.