 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Graph Modeling for Cross-Domain Few-Shot Medical Image Segmentation
Dec 25, 2025Cross-domain few-shot medical image segmentation (CD-FSMIS) offers a promising and data-efficient solution for medical applications where annotations are severely scarce and multimodal analysis is required. However, existing methods typically filter out domain-specific information to improve generalization, which inadvertently limits cross-domain performance and degrades source-domain accuracy. To address this, we present Contrastive Graph Modeling (C-Graph), a framework that leverages the structural consistency of medical images as a reliable domain-transferable prior. We represent image features as graphs, with pixels as nodes and semantic affinities as edges. A Structural Prior Graph (SPG) layer is proposed to capture and transfer target-category node dependencies and enable global structure modeling through explicit node interactions. Building upon SPG layers, we introduce a Subgraph Matching Decoding (SMD) mechanism that exploits semantic relations among nodes to guide prediction. Furthermore, we design a Confusion-minimizing Node Contrast (CNC) loss to mitigate node ambiguity and subgraph heterogeneity by contrastively enhancing node discriminability in the graph space. Our method significantly outperforms prior CD-FSMIS approaches across multiple cross-domain benchmarks, achieving state-of-the-art performance while simultaneously preserving strong segmentation accuracy on the source domain.
Bridging Granularity Gaps: Hierarchical Semantic Learning for Cross-domain Few-shot Segmentation
Nov 15, 2025Cross-domain Few-shot Segmentation (CD-FSS) aims to segment novel classes from target domains that are not involved in training and have significantly different data distributions from the source domain, using only a few annotated samples, and recent years have witnessed significant progress on this task. However, existing CD-FSS methods primarily focus on style gaps between source and target domains while ignoring segmentation granularity gaps, resulting in insufficient semantic discriminability for novel classes in target domains. Therefore, we propose a Hierarchical Semantic Learning (HSL) framework to tackle this problem. Specifically, we introduce a Dual Style Randomization (DSR) module and a Hierarchical Semantic Mining (HSM) module to learn hierarchical semantic features, thereby enhancing the model's ability to recognize semantics at varying granularities. DSR simulates target domain data with diverse foreground-background style differences and overall style variations through foreground and global style randomization respectively, while HSM leverages multi-scale superpixels to guide the model to mine intra-class consistency and inter-class distinction at different granularities. Additionally, we also propose a Prototype Confidence-modulated Thresholding (PCMT) module to mitigate segmentation ambiguity when foreground and background are excessively similar. Extensive experiments are conducted on four popular target domain datasets, and the results demonstrate that our method achieves state-of-the-art performance.
Concentrate on Weakness: Mining Hard Prototypes for Few-Shot Medical Image Segmentation
May 28, 2025Few-Shot Medical Image Segmentation (FSMIS) has been widely used to train a model that can perform segmentation from only a few annotated images. However, most existing prototype-based FSMIS methods generate multiple prototypes from the support image solely by random sampling or local averaging, which can cause particularly severe boundary blurring due to the tendency for normal features accounting for the majority of features of a specific category. Consequently, we propose to focus more attention to those weaker features that are crucial for clear segmentation boundary. Specifically, we design a Support Self-Prediction (SSP) module to identify such weak features by comparing true support mask with one predicted by global support prototype. Then, a Hard Prototypes Generation (HPG) module is employed to generate multiple hard prototypes based on these weak features. Subsequently, a Multiple Similarity Maps Fusion (MSMF) module is devised to generate final segmenting mask in a dual-path fashion to mitigate the imbalance between foreground and background in medical images. Furthermore, we introduce a boundary loss to further constraint the edge of segmentation. Extensive experiments on three publicly available medical image datasets demonstrate that our method achieves state-of-the-art performance. Code is available at https://github.com/jcjiang99/CoW.
Few-shot Novel Category Discovery
May 13, 2025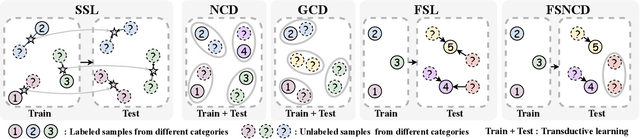
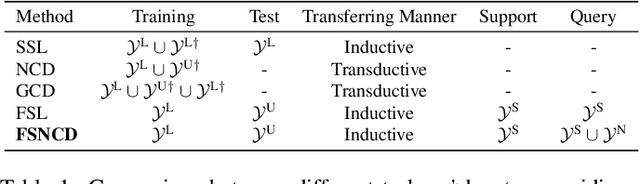
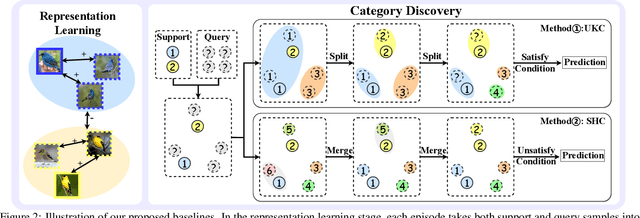
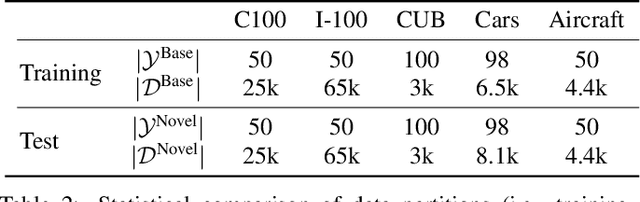
The recently proposed Novel Category Discovery (NCD) adapt paradigm of transductive learning hinders its application in more real-world scenarios. In fact, few labeled data in part of new categories can well alleviate this burden, which coincides with the ease that people can label few of new category data. Therefore, this paper presents a new setting in which a trained agent is able to flexibly switch between the tasks of identifying examples of known (labelled) classes and clustering novel (completely unlabeled) classes as the number of query examples increases by leveraging knowledge learned from only a few (handful) support examples. Drawing inspiration from the discovery of novel categories using prior-based clustering algorithms, we introduce a novel framework that further relaxes its assumptions to the real-world open set level by unifying the concept of model adaptability in few-shot learning. We refer to this setting as Few-Shot Novel Category Discovery (FSNCD) and propose Semi-supervised Hierarchical Clustering (SHC) and Uncertainty-aware K-means Clustering (UKC) to examine the model's reasoning capabilities. Extensive experiments and detailed analysis on five commonly used datasets demonstrate that our methods can achieve leading performance levels across different task settings and scenarios.
FAMNet: Frequency-aware Matching Network for Cross-domain Few-shot Medical Image Segmentation
Dec 12, 2024



Existing few-shot medical image segmentation (FSMIS) models fail to address a practical issue in medical imaging: the domain shift caused by different imaging techniques, which limits the applicability to current FSMIS tasks. To overcome this limitation, we focus on the cross-domain few-shot medical image segmentation (CD-FSMIS) task, aiming to develop a generalized model capable of adapting to a broader range of medical image segmentation scenarios with limited labeled data from the novel target domain. Inspired by the characteristics of frequency domain similarity across different domains, we propose a Frequency-aware Matching Network (FAMNet), which includes two key components: a Frequency-aware Matching (FAM) module and a Multi-Spectral Fusion (MSF) module. The FAM module tackles two problems during the meta-learning phase: 1) intra-domain variance caused by the inherent support-query bias, due to the different appearances of organs and lesions, and 2) inter-domain variance caused by different medical imaging techniques. Additionally, we design an MSF module to integrate the different frequency features decoupled by the FAM module, and further mitigate the impact of inter-domain variance on the model's segmentation performance. Combining these two modules, our FAMNet surpasses existing FSMIS models and Cross-domain Few-shot Semantic Segmentation models on three cross-domain datasets, achieving state-of-the-art performance in the CD-FSMIS task.
RobustEMD: Domain Robust Matching for Cross-domain Few-shot Medical Image Segmentation
Oct 01, 2024



Few-shot medical image segmentation (FSMIS) aims to perform the limited annotated data learning in the medical image analysis scope. Despite the progress has been achieved, current FSMIS models are all trained and deployed on the same data domain, as is not consistent with the clinical reality that medical imaging data is always across different data domains (e.g. imaging modalities, institutions and equipment sequences). How to enhance the FSMIS models to generalize well across the different specific medical imaging domains? In this paper, we focus on the matching mechanism of the few-shot semantic segmentation models and introduce an Earth Mover's Distance (EMD) calculation based domain robust matching mechanism for the cross-domain scenario. Specifically, we formulate the EMD transportation process between the foreground support-query features, the texture structure aware weights generation method, which proposes to perform the sobel based image gradient calculation over the nodes, is introduced in the EMD matching flow to restrain the domain relevant nodes. Besides, the point set level distance measurement metric is introduced to calculated the cost for the transportation from support set nodes to query set nodes. To evaluate the performance of our model, we conduct experiments on three scenarios (i.e., cross-modal, cross-sequence and cross-institution), which includes eight medical datasets and involves three body regions, and the results demonstrate that our model achieves the SoTA performance against the compared models.
Contextual Interaction via Primitive-based Adversarial Training For Compositional Zero-shot Learning
Jun 21, 2024
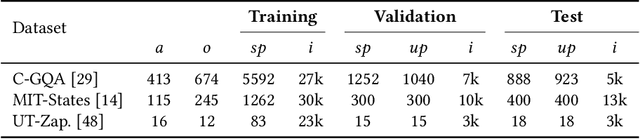

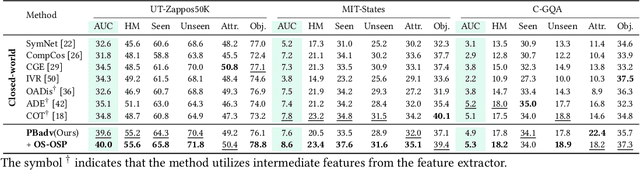
Compositional Zero-shot Learning (CZSL) aims to identify novel compositions via known attribute-object pairs. The primary challenge in CZSL tasks lies in the significant discrepancies introduced by the complex interaction between the visual primitives of attribute and object, consequently decreasing the classification performance towards novel compositions. Previous remarkable works primarily addressed this issue by focusing on disentangling strategy or utilizing object-based conditional probabilities to constrain the selection space of attributes. Unfortunately, few studies have explored the problem from the perspective of modeling the mechanism of visual primitive interactions. Inspired by the success of vanilla adversarial learning in Cross-Domain Few-Shot Learning, we take a step further and devise a model-agnostic and Primitive-Based Adversarial training (PBadv) method to deal with this problem. Besides, the latest studies highlight the weakness of the perception of hard compositions even under data-balanced conditions. To this end, we propose a novel over-sampling strategy with object-similarity guidance to augment target compositional training data. We performed detailed quantitative analysis and retrieval experiments on well-established datasets, such as UT-Zappos50K, MIT-States, and C-GQA, to validate the effectiveness of our proposed method, and the state-of-the-art (SOTA) performance demonstrates the superiority of our approach. The code is available at https://github.com/lisuyi/PBadv_czsl.
Bayesian Bandit Algorithms with Approximate Inference in Stochastic Linear Bandits
Jun 20, 2024
Bayesian bandit algorithms with approximate Bayesian inference have been widely used in real-world applications. Nevertheless, their theoretical justification is less investigated in the literature, especially for contextual bandit problems. To fill this gap, we propose a general theoretical framework to analyze stochastic linear bandits in the presence of approximate inference and conduct regret analysis on two Bayesian bandit algorithms, Linear Thompson sampling (LinTS) and the extension of Bayesian Upper Confidence Bound, namely Linear Bayesian Upper Confidence Bound (LinBUCB). We demonstrate that both LinTS and LinBUCB can preserve their original rates of regret upper bound but with a sacrifice of larger constant terms when applied with approximate inference. These results hold for general Bayesian inference approaches, under the assumption that the inference error measured by two different $\alpha$-divergences is bounded. Additionally, by introducing a new definition of well-behaved distributions, we show that LinBUCB improves the regret rate of LinTS from $\tilde{O}(d^{3/2}\sqrt{T})$ to $\tilde{O}(d\sqrt{T})$, matching the minimax optimal rate. To our knowledge, this work provides the first regret bounds in the setting of stochastic linear bandits with bounded approximate inference errors.
Learning Spatial Similarity Distribution for Few-shot Object Counting
May 20, 2024



Few-shot object counting aims to count the number of objects in a query image that belong to the same class as the given exemplar images. Existing methods compute the similarity between the query image and exemplars in the 2D spatial domain and perform regression to obtain the counting number. However, these methods overlook the rich information about the spatial distribution of similarity on the exemplar images, leading to significant impact on matching accuracy. To address this issue, we propose a network learning Spatial Similarity Distribution (SSD) for few-shot object counting, which preserves the spatial structure of exemplar features and calculates a 4D similarity pyramid point-to-point between the query features and exemplar features, capturing the complete distribution information for each point in the 4D similarity space. We propose a Similarity Learning Module (SLM) which applies the efficient center-pivot 4D convolutions on the similarity pyramid to map different similarity distributions to distinct predicted density values, thereby obtaining accurate count. Furthermore, we also introduce a Feature Cross Enhancement (FCE) module that enhances query and exemplar features mutually to improve the accuracy of feature matching. Our approach outperforms state-of-the-art methods on multiple datasets, including FSC-147 and CARPK. Code is available at https://github.com/CBalance/SSD.
Revealing the Proximate Long-Tail Distribution in Compositional Zero-Shot Learning
Dec 26, 2023Compositional Zero-Shot Learning (CZSL) aims to transfer knowledge from seen state-object pairs to novel unseen pairs. In this process, visual bias caused by the diverse interrelationship of state-object combinations blurs their visual features, hindering the learning of distinguishable class prototypes. Prevailing methods concentrate on disentangling states and objects directly from visual features, disregarding potential enhancements that could arise from a data viewpoint. Experimentally, we unveil the results caused by the above problem closely approximate the long-tailed distribution. As a solution, we transform CZSL into a proximate class imbalance problem. We mathematically deduce the role of class prior within the long-tailed distribution in CZSL. Building upon this insight, we incorporate visual bias caused by compositions into the classifier's training and inference by estimating it as a proximate class prior. This enhancement encourages the classifier to acquire more discernible class prototypes for each composition, thereby achieving more balanced predictions. Experimental results demonstrate that our approach elevates the model's performance to the state-of-the-art level, without introducing additional parameters. Our code is available at \url{https://github.com/LanchJL/ProLT-CZSL}.