 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Frequency Attention Networks for Single Snapshot Sparse Array Interpolation
Mar 07, 2025Sparse arrays have been widely exploited in radar systems because of their advantages in achieving large array aperture at low hardware cost, while significantly reducing mutual coupling. However, sparse arrays suffer from high sidelobes which may lead to false detections. Missing elements in sparse arrays can be interpolated using the sparse array measurements. In snapshot-limited scenarios, such as automotive radar, it is challenging to utilize difference coarrays which require a large number of snapshots to construct a covariance matrix for interpolation. For single snapshot sparse array interpolation, traditional model-based methods, while effective, require expert knowledge for hyperparameter tuning, lack task-specific adaptability, and incur high computational costs. In this paper, we propose a novel deep learning-based single snapshot sparse array interpolation network that addresses these challenges by leveraging a frequency-domain attention mechanism. The proposed approach transforms the sparse signal into the frequency domain, where the attention mechanism focuses on key spectral regions, enabling improved interpolation of missing elements even in low signal-to-noise ratio (SNR) conditions. By minimizing computational costs and enhancing interpolation accuracy, the proposed method demonstrates superior performance compared to traditional approaches, making it well-suited for automotive radar applications.
Advancing Single-Snapshot DOA Estimation with Siamese Neural Networks for Sparse Linear Arrays
Jan 13, 2025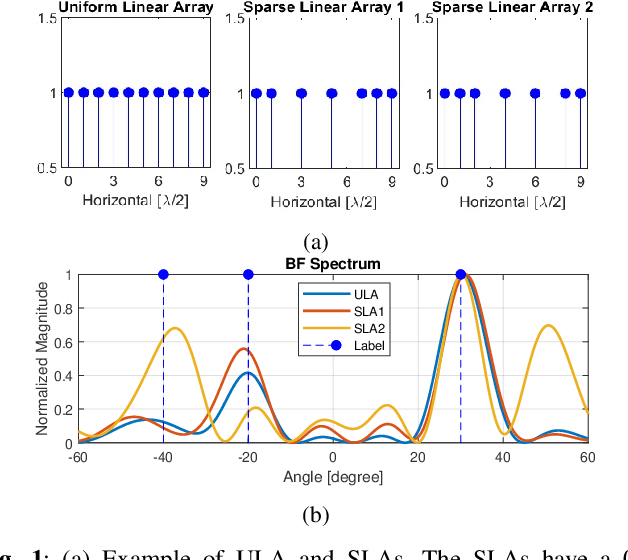
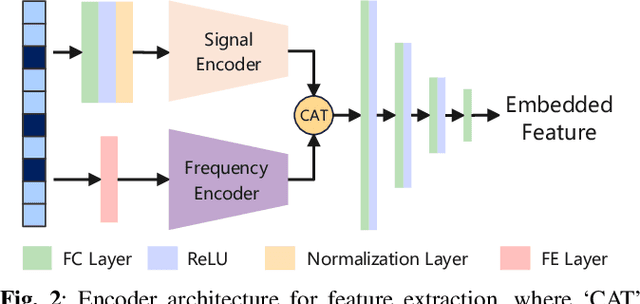
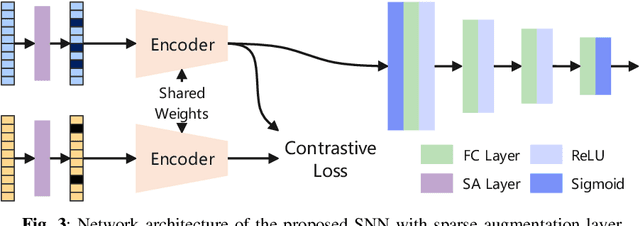
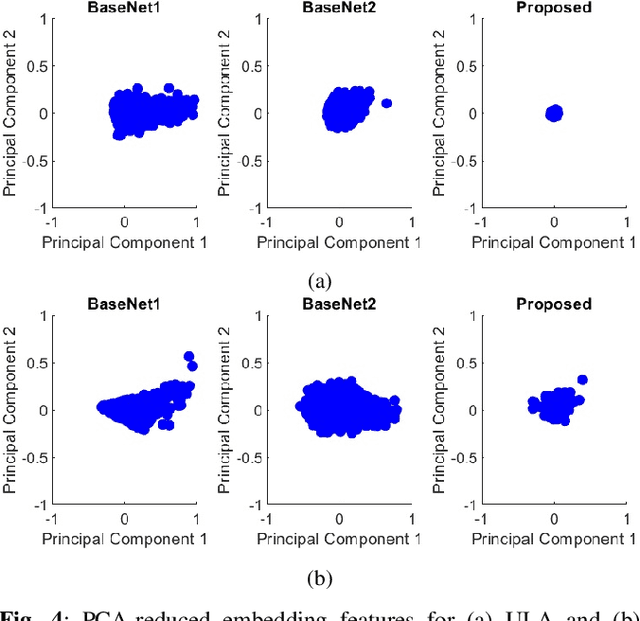
Single-snapshot signal processing in sparse linear arrays has become increasingly vital, particularly in dynamic environments like automotive radar systems, where only limited snapshots are available. These arrays are often utilized either to cut manufacturing costs or result from unintended antenna failures, leading to challenges such as high sidelobe levels and compromised accuracy in direction-of-arrival (DOA) estimation. Despite deep learning's success in tasks such as DOA estimation, the need for extensive training data to increase target numbers or improve angular resolution poses significant challenges. In response, this paper presents a novel Siamese neural network (SNN) featuring a sparse augmentation layer, which enhances signal feature embedding and DOA estimation accuracy in sparse arrays. We demonstrate the enhanced DOA estimation performance of our approach through detailed feature analysis and performance evaluation. The code for this study is available at https://github.com/ruxinzh/SNNS_SLA.
Antenna Failure Resilience: Deep Learning-Enabled Robust DOA Estimation with Single Snapshot Sparse Arrays
May 05, 2024
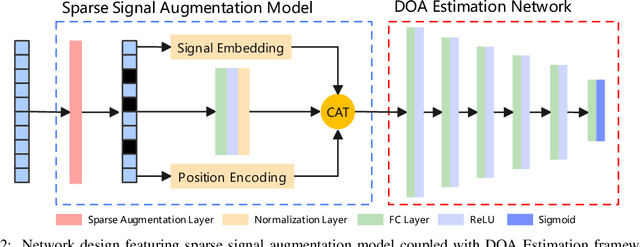
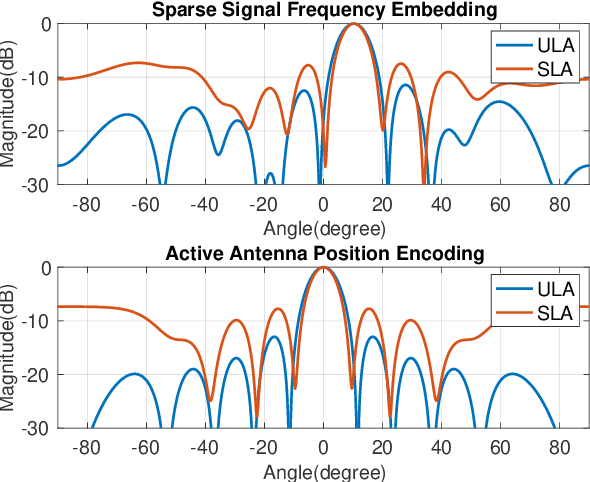
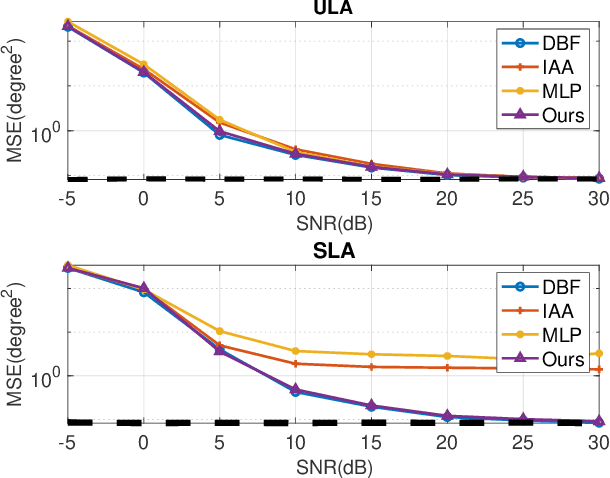
Recent advancements in Deep Learning (DL) for Direction of Arrival (DOA) estimation have highlighted its superiority over traditional methods, offering faster inference, enhanced super-resolution, and robust performance in low Signal-to-Noise Ratio (SNR) environments. Despite these advancements, existing research predominantly focuses on multi-snapshot scenarios, a limitation in the context of automotive radar systems which demand high angular resolution and often rely on limited snapshots, sometimes as scarce as a single snapshot. Furthermore, the increasing interest in sparse arrays for automotive radar, owing to their cost-effectiveness and reduced antenna element coupling, presents additional challenges including susceptibility to random sensor failures. This paper introduces a pioneering DL framework featuring a sparse signal augmentation layer, meticulously crafted to bolster single snapshot DOA estimation across diverse sparse array setups and amidst antenna failures. To our best knowledge, this is the first work to tackle this issue. Our approach improves the adaptability of deep learning techniques to overcome the unique difficulties posed by sparse arrays with single snapshot. We conduct thorough evaluations of our network's performance using simulated and real-world data, showcasing the efficacy and real-world viability of our proposed solution. The code and real-world dataset employed in this study are available at https://github.com/ruxinzh/Deep_RSA_DOA.
Near-Space Communications: The Last Piece of 6G Space-Air-Ground-Sea Integrated Network Puzzle
Dec 30, 2023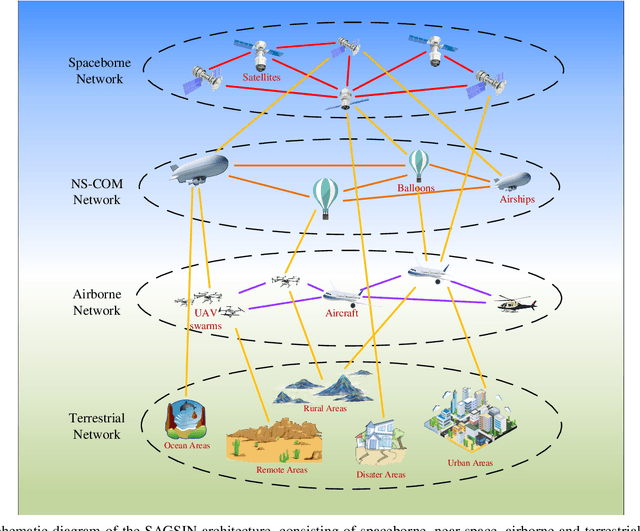
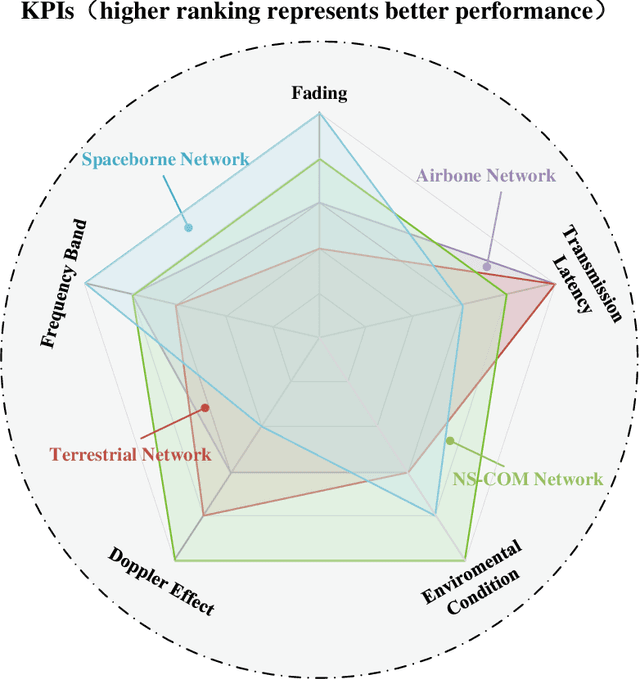
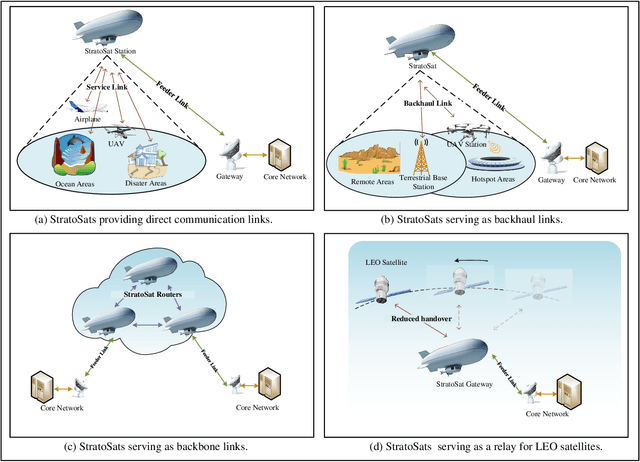
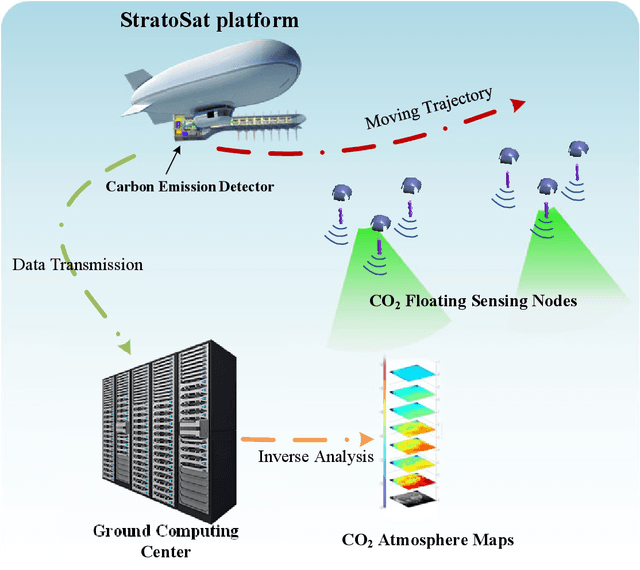
This article presents a comprehensive study on the emerging near-space communications (NS-COM) within the context of space-air-ground-sea integrated network (SAGSIN). Specifically, we firstly explore the recent technical developments of NS-COM, followed by the discussions about motivations behind integrating NS-COM into SAGSIN. To further demonstrate the necessity of NS-COM, a comparative analysis between the NS-COM network and other counterparts in SAGSIN is conducted, covering aspects of deployment, coverage and channel characteristics. Afterwards, the technical aspects of NS-COM, including channel modeling, random access, channel estimation, array-based beam management and joint network optimization, are examined in detail. Furthermore, we explore the potential applications of NS-COM, such as structural expansion in SAGSIN communications, remote and urgent communications, weather monitoring and carbon neutrality. Finally, some promising research avenues are identified, including near-space-ground direct links, reconfigurable multiple input multiple output (MIMO) array, federated learning assisted NS-COM, maritime communication and free space optical (FSO) communication. Overall, this paper highlights that the NS-COM plays an indispensable role in the SAGSIN puzzle, providing substantial performance and coverage enhancement to the traditional SAGSIN architecture.
Interpretable and Efficient Beamforming-Based Deep Learning for Single Snapshot DOA Estimation
Sep 14, 2023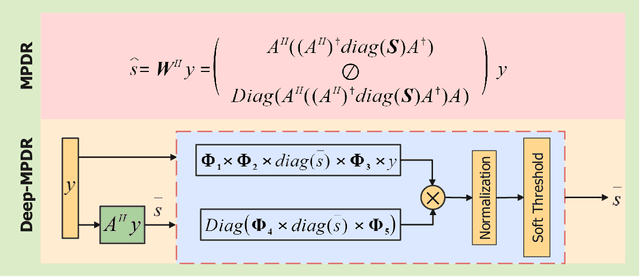
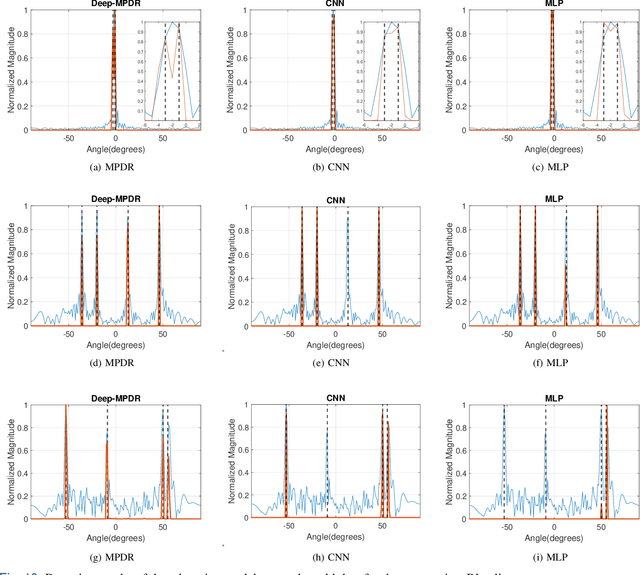


We introduce an interpretable deep learning approach for direction of arrival (DOA) estimation with a single snapshot. Classical subspace-based methods like MUSIC and ESPRIT use spatial smoothing on uniform linear arrays for single snapshot DOA estimation but face drawbacks in reduced array aperture and inapplicability to sparse arrays. Single-snapshot methods such as compressive sensing and iterative adaptation approach (IAA) encounter challenges with high computational costs and slow convergence, hampering real-time use. Recent deep learning DOA methods offer promising accuracy and speed. However, the practical deployment of deep networks is hindered by their black-box nature. To address this, we propose a deep-MPDR network translating minimum power distortionless response (MPDR)-type beamformer into deep learning, enhancing generalization and efficiency. Comprehensive experiments conducted using both simulated and real-world datasets substantiate its dominance in terms of inference time and accuracy in comparison to conventional methods. Moreover, it excels in terms of efficiency, generalizability, and interpretability when contrasted with other deep learning DOA estimation networks.
Push the Boundary of SAM: A Pseudo-label Correction Framework for Medical Segmentation
Aug 02, 2023Segment anything model (SAM) has emerged as the leading approach for zero-shot learning in segmentation, offering the advantage of avoiding pixel-wise annotation. It is particularly appealing in medical image segmentation where annotation is laborious and expertise-demanding. However, the direct application of SAM often yields inferior results compared to conventional fully supervised segmentation networks. While using SAM generated pseudo label could also benefit the training of fully supervised segmentation, the performance is limited by the quality of pseudo labels. In this paper, we propose a novel label corruption to push the boundary of SAM-based segmentation. Our model utilizes a novel noise detection module to distinguish between noisy labels from clean labels. This enables us to correct the noisy labels using an uncertainty-based self-correction module, thereby enriching the clean training set. Finally, we retrain the network with updated labels to optimize its weights for future predictions. One key advantage of our model is its ability to train deep networks using SAM-generated pseudo labels without relying on a subset of expert-level annotations. We demonstrate the effectiveness of our proposed model on both X-ray and lung CT datasets, indicating its ability to improve segmentation accuracy and outperform baseline methods in label correction.
SCPAT-GAN: Structural Constrained and Pathology Aware Convolutional Transformer-GAN for Virtual Histology Staining of Human Coronary OCT images
Jul 22, 2023There is a significant need for the generation of virtual histological information from coronary optical coherence tomography (OCT) images to better guide the treatment of coronary artery disease. However, existing methods either require a large pixel-wisely paired training dataset or have limited capability to map pathological regions. To address these issues, we proposed a structural constrained, pathology aware, transformer generative adversarial network, namely SCPAT-GAN, to generate virtual stained H&E histology from OCT images. The proposed SCPAT-GAN advances existing methods via a novel design to impose pathological guidance on structural layers using transformer-based network.
Frequency-aware optical coherence tomography image super-resolution via conditional generative adversarial neural network
Jul 20, 2023



Optical coherence tomography (OCT) has stimulated a wide range of medical image-based diagnosis and treatment in fields such as cardiology and ophthalmology. Such applications can be further facilitated by deep learning-based super-resolution technology, which improves the capability of resolving morphological structures. However, existing deep learning-based method only focuses on spatial distribution and disregard frequency fidelity in image reconstruction, leading to a frequency bias. To overcome this limitation, we propose a frequency-aware super-resolution framework that integrates three critical frequency-based modules (i.e., frequency transformation, frequency skip connection, and frequency alignment) and frequency-based loss function into a conditional generative adversarial network (cGAN). We conducted a large-scale quantitative study from an existing coronary OCT dataset to demonstrate the superiority of our proposed framework over existing deep learning frameworks. In addition, we confirmed the generalizability of our framework by applying it to fish corneal images and rat retinal images, demonstrating its capability to super-resolve morphological details in eye imaging.
Structural constrained virtual histology staining for human coronary imaging using deep learning
Nov 12, 2022



Histopathological analysis is crucial in artery characterization for coronary artery disease (CAD). However, histology requires an invasive and time-consuming process. In this paper, we propose to generate virtual histology staining using Optical Coherence Tomography (OCT) images to enable real-time histological visualization. We develop a deep learning network, namely Coronary-GAN, to transfer coronary OCT images to virtual histology images. With a special consideration on the structural constraints in coronary OCT images, our method achieves better image generation performance than the conventional GAN-based method. The experimental results indicate that Coronary-GAN generates virtual histology images that are similar to real histology images, revealing the human coronary layers.
Towards reliable calcification detection: calibration of uncertainty in coronary optical coherence tomography images
Nov 12, 2022Optical coherence tomography (OCT) has become increasingly essential in assisting the treatment of coronary artery disease (CAD). Image-guided solutions such as Percutaneous Coronary Intervention (PCI) are extensively used during the treatment of CAD. However, unidentified calcified regions within a narrowed artery could impair the outcome of the PCI. Prior to treatments, object detection is paramount to automatically procure accurate readings on the location and thickness of calcifications within the artery. Deep learning-based object detection methods have been explored in a variety of applications. The quality of object detection predictions could lead to uncertain results, which are not desirable in safety-critical scenarios. In this work, we implement an object detection model, You-Only-Look-Once v5 (YOLO), on a calcification detection framework within coronary OCT images. We evaluate the uncertainty of predictions based on the expected calibration errors, thus assessing the certainty level of detection results. To calibrate confidence scores of predictions, we implement dependent logistic calibration using each detection result's confidence and center coordinates. With the calibrated confidence score of each prediction, we lower the uncertainty of predictions in calcification detection. Our results show that the YOLO achieves higher precision and recall in comparison with the other object detection model, meanwhile producing more reliable results. The calibrated confidence of prediction results in a confidence error of approximately 0.13, suggesting that the confidence calibration on calcification detection could provide a more trustworthy result, indicating a great potential to assist clinical evaluation of treating the CAD during the imaging-guided procedure.