 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAR-AVIO: Fast and Robust Schur-Complement Based Acoustic-Visual-Inertial Fusion Odometry with Sensor Calibration
Dec 23, 2025



Underwater environments impose severe challenges to visual-inertial odometry systems, as strong light attenuation, marine snow and turbidity, together with weakly exciting motions, degrade inertial observability and cause frequent tracking failures over long-term operation. While tightly coupled acoustic-visual-inertial fusion, typically implemented through an acoustic Doppler Velocity Log (DVL) integrated with visual-inertial measurements, can provide accurate state estimation, the associated graph-based optimization is often computationally prohibitive for real-time deployment on resource-constrained platforms. Here we present FAR-AVIO, a Schur-Complement based, tightly coupled acoustic-visual-inertial odometry framework tailored for underwater robots. FAR-AVIO embeds a Schur complement formulation into an Extended Kalman Filter(EKF), enabling joint pose-landmark optimization for accuracy while maintaining constant-time updates by efficiently marginalizing landmark states. On top of this backbone, we introduce Adaptive Weight Adjustment and Reliability Evaluation(AWARE), an online sensor health module that continuously assesses the reliability of visual, inertial and DVL measurements and adaptively regulates their sigma weights, and we develop an efficient online calibration scheme that jointly estimates DVL-IMU extrinsics, without dedicated calibration manoeuvres. Numerical simulations and real-world underwater experiments consistently show that FAR-AVIO outperforms state-of-the-art underwater SLAM baselines in both localization accuracy and computational efficiency, enabling robust operation on low-power embedded platforms. Our implementation has been released as open source software at https://far-vido.gitbook.io/far-vido-docs.
Intelligent Multimodal Multi-Sensor Fusion-Based UAV Identification, Localization, and Countermeasures for Safeguarding Low-Altitude Economy
Oct 27, 2025The development of the low-altitude economy has led to a growing prominence of uncrewed aerial vehicle (UAV) safety management issues. Therefore, accurate identification, real-time localization, and effective countermeasures have become core challenges in airspace security assurance. This paper introduces an integrated UAV management and control system based on deep learning, which integrates multimodal multi-sensor fusion perception, precise positioning, and collaborative countermeasures. By incorporating deep learning methods, the system combines radio frequency (RF) spectral feature analysis, radar detection, electro-optical identification, and other methods at the detection level to achieve the identification and classification of UAVs. At the localization level, the system relies on multi-sensor data fusion and the air-space-ground integrated communication network to conduct real-time tracking and prediction of UAV flight status, providing support for early warning and decision-making. At the countermeasure level, it adopts comprehensive measures that integrate ``soft kill'' and ``hard kill'', including technologies such as electromagnetic signal jamming, navigation spoofing, and physical interception, to form a closed-loop management and control process from early warning to final disposal, which significantly enhances the response efficiency and disposal accuracy of low-altitude UAV management.
Embodied Escaping: End-to-End Reinforcement Learning for Robot Navigation in Narrow Environment
Mar 05, 2025



Autonomous navigation is a fundamental task for robot vacuum cleaners in indoor environments. Since their core function is to clean entire areas, robots inevitably encounter dead zones in cluttered and narrow scenarios. Existing planning methods often fail to escape due to complex environmental constraints, high-dimensional search spaces, and high difficulty maneuvers. To address these challenges, this paper proposes an embodied escaping model that leverages reinforcement learning-based policy with an efficient action mask for dead zone escaping. To alleviate the issue of the sparse reward in training, we introduce a hybrid training policy that improves learning efficiency. In handling redundant and ineffective action options, we design a novel action representation to reshape the discrete action space with a uniform turning radius. Furthermore, we develop an action mask strategy to select valid action quickly, balancing precision and efficiency. In real-world experiments, our robot is equipped with a Lidar, IMU, and two-wheel encoders. Extensive quantitative and qualitative experiments across varying difficulty levels demonstrate that our robot can consistently escape from challenging dead zones. Moreover, our approach significantly outperforms compared path planning and reinforcement learning methods in terms of success rate and collision avoidance.
RL-OGM-Parking: Lidar OGM-Based Hybrid Reinforcement Learning Planner for Autonomous Parking
Feb 26, 2025Autonomous parking has become a critical application in automatic driving research and development. Parking operations often suffer from limited space and complex environments, requiring accurate perception and precise maneuvering. Traditional rule-based parking algorithms struggle to adapt to diverse and unpredictable conditions, while learning-based algorithms lack consistent and stable performance in various scenarios. Therefore, a hybrid approach is necessary that combines the stability of rule-based methods and the generalizability of learning-based methods. Recently, reinforcement learning (RL) based policy has shown robust capability in planning tasks. However, the simulation-to-reality (sim-to-real) transfer gap seriously blocks the real-world deployment. To address these problems, we employ a hybrid policy, consisting of a rule-based Reeds-Shepp (RS) planner and a learning-based reinforcement learning (RL) planner. A real-time LiDAR-based Occupancy Grid Map (OGM) representation is adopted to bridge the sim-to-real gap, leading the hybrid policy can be applied to real-world systems seamlessly. We conducted extensive experiments both in the simulation environment and real-world scenarios, and the result demonstrates that the proposed method outperforms pure rule-based and learning-based methods. The real-world experiment further validates the feasibility and efficiency of the proposed method.
GS-LIVO: Real-Time LiDAR, Inertial, and Visual Multi-sensor Fused Odometry with Gaussian Mapping
Jan 15, 2025



In recent years, 3D Gaussian splatting (3D-GS) has emerged as a novel scene representation approach. However, existing vision-only 3D-GS methods often rely on hand-crafted heuristics for point-cloud densification and face challenges in handling occlusions and high GPU memory and computation consumption. LiDAR-Inertial-Visual (LIV) sensor configuration has demonstrated superior performance in localization and dense mapping by leveraging complementary sensing characteristics: rich texture information from cameras, precise geometric measurements from LiDAR, and high-frequency motion data from IMU. Inspired by this, we propose a novel real-time Gaussian-based simultaneous localization and mapping (SLAM) system. Our map system comprises a global Gaussian map and a sliding window of Gaussians, along with an IESKF-based odometry. The global Gaussian map consists of hash-indexed voxels organized in a recursive octree, effectively covering sparse spatial volumes while adapting to different levels of detail and scales. The Gaussian map is initialized through multi-sensor fusion and optimized with photometric gradients. Our system incrementally maintains a sliding window of Gaussians, significantly reducing GPU computation and memory consumption by only optimizing the map within the sliding window. Moreover, we implement a tightly coupled multi-sensor fusion odometry with an iterative error state Kalman filter (IESKF), leveraging real-time updating and rendering of the Gaussian map. Our system represents the first real-time Gaussian-based SLAM framework deployable on resource-constrained embedded systems, demonstrated on the NVIDIA Jetson Orin NX platform. The framework achieves real-time performance while maintaining robust multi-sensor fusion capabilities. All implementation algorithms, hardware designs, and CAD models will be publicly available.
Cross-Modal Visual Relocalization in Prior LiDAR Maps Utilizing Intensity Textures
Dec 02, 2024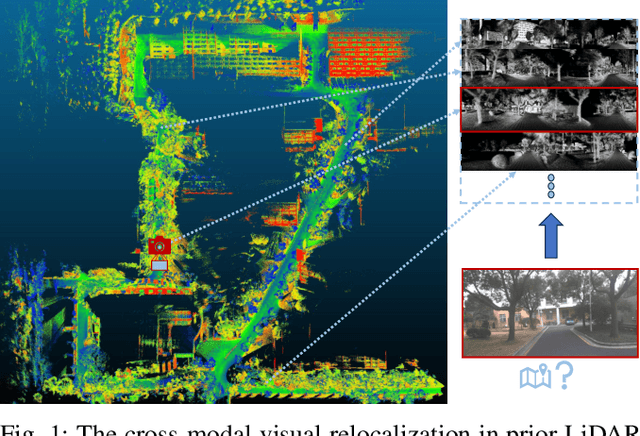


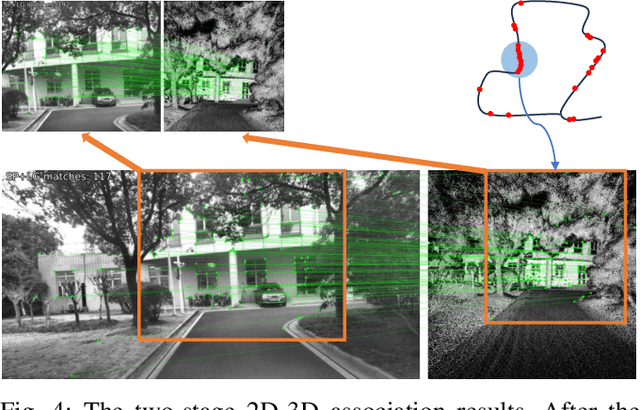
Cross-modal localization has drawn increasing attention in recent years, while the visual relocalization in prior LiDAR maps is less studied. Related methods usually suffer from inconsistency between the 2D texture and 3D geometry, neglecting the intensity features in the LiDAR point cloud. In this paper, we propose a cross-modal visual relocalization system in prior LiDAR maps utilizing intensity textures, which consists of three main modules: map projection, coarse retrieval, and fine relocalization. In the map projection module, we construct the database of intensity channel map images leveraging the dense characteristic of panoramic projection. The coarse retrieval module retrieves the top-K most similar map images to the query image from the database, and retains the top-K' results by covisibility clustering. The fine relocalization module applies a two-stage 2D-3D association and a covisibility inlier selection method to obtain robust correspondences for 6DoF pose estimation. The experimental results on our self-collected datasets demonstrate the effectiveness in both place recognition and pose estimation tasks.
Integrated Location Sensing and Communication for Ultra-Massive MIMO With Hybrid-Field Beam-Squint Effect
Nov 08, 2024



The advent of ultra-massive multiple-input-multiple output systems holds great promise for next-generation communications, yet their channels exhibit hybrid far- and near- field beam-squint (HFBS) effect. In this paper, we not only overcome but also harness the HFBS effect to propose an integrated location sensing and communication (ILSC) framework. During the uplink training stage, user terminals (UTs) transmit reference signals for simultaneous channel estimation and location sensing. This stage leverages an elaborately designed hybrid-field projection matrix to overcome the HFBS effect and estimate the channel in compressive manner. Subsequently, the scatterers' locations can be sensed from the spherical wavefront based on the channel estimation results. By treating the sensed scatterers as virtual anchors, we employ a weighted least-squares approach to derive UT' s location. Moreover, we propose an iterative refinement mechanism, which utilizes the accurately estimated time difference of arrival of multipath components to enhance location sensing precision. In the following downlink data transmission stage, we leverage the acquired location information to further optimize the hybrid beamformer, which combines the beam broadening and focusing to mitigate the spectral efficiency degradation resulted from the HFBS effect. Extensive simulation experiments demonstrate that the proposed ILSC scheme has superior location sensing and communication performance than conventional methods.
ParkingE2E: Camera-based End-to-end Parking Network, from Images to Planning
Aug 04, 2024



Autonomous parking is a crucial task in the intelligent driving field. Traditional parking algorithms are usually implemented using rule-based schemes. However, these methods are less effective in complex parking scenarios due to the intricate design of the algorithms. In contrast, neural-network-based methods tend to be more intuitive and versatile than the rule-based methods. By collecting a large number of expert parking trajectory data and emulating human strategy via learning-based methods, the parking task can be effectively addressed. In this paper, we employ imitation learning to perform end-to-end planning from RGB images to path planning by imitating human driving trajectories. The proposed end-to-end approach utilizes a target query encoder to fuse images and target features, and a transformer-based decoder to autoregressively predict future waypoints. We conducted extensive experiments in real-world scenarios, and the results demonstrate that the proposed method achieved an average parking success rate of 87.8% across four different real-world garages. Real-vehicle experiments further validate the feasibility and effectiveness of the method proposed in this paper.
MapLocNet: Coarse-to-Fine Feature Registration for Visual Re-Localization in Navigation Maps
Jul 11, 2024



Robust localization is the cornerstone of autonomous driving, especially in challenging urban environments where GPS signals suffer from multipath errors. Traditional localization approaches rely on high-definition (HD) maps, which consist of precisely annotated landmarks. However, building HD map is expensive and challenging to scale up. Given these limitations, leveraging navigation maps has emerged as a promising low-cost alternative for localization. Current approaches based on navigation maps can achieve highly accurate localization, but their complex matching strategies lead to unacceptable inference latency that fails to meet the real-time demands. To address these limitations, we propose a novel transformer-based neural re-localization method. Inspired by image registration, our approach performs a coarse-to-fine neural feature registration between navigation map and visual bird's-eye view features. Our method significantly outperforms the current state-of-the-art OrienterNet on both the nuScenes and Argoverse datasets, which is nearly 10%/20% localization accuracy and 30/16 FPS improvement on single-view and surround-view input settings, separately. We highlight that our research presents an HD-map-free localization method for autonomous driving, offering cost-effective, reliable, and scalable performance in challenging driving environments.
BLOS-BEV: Navigation Map Enhanced Lane Segmentation Network, Beyond Line of Sight
Jul 11, 2024



Bird's-eye-view (BEV) representation is crucial for the perception function in autonomous driving tasks. It is difficult to balance the accuracy, efficiency and range of BEV representation. The existing works are restricted to a limited perception range within 50 meters. Extending the BEV representation range can greatly benefit downstream tasks such as topology reasoning, scene understanding, and planning by offering more comprehensive information and reaction time. The Standard-Definition (SD) navigation maps can provide a lightweight representation of road structure topology, characterized by ease of acquisition and low maintenance costs. An intuitive idea is to combine the close-range visual information from onboard cameras with the beyond line-of-sight (BLOS) environmental priors from SD maps to realize expanded perceptual capabilities. In this paper, we propose BLOS-BEV, a novel BEV segmentation model that incorporates SD maps for accurate beyond line-of-sight perception, up to 200m. Our approach is applicable to common BEV architectures and can achieve excellent results by incorporating information derived from SD maps. We explore various feature fusion schemes to effectively integrate the visual BEV representations and semantic features from the SD map, aiming to leverage the complementary information from both sources optimally. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in BEV segmentation on nuScenes and Argoverse benchmark. Through multi-modal inputs, BEV segmentation is significantly enhanced at close ranges below 50m, while also demonstrating superior performance in long-range scenarios, surpassing other methods by over 20% mIoU at distances ranging from 50-200m.