 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHerculean: An Agentic Benchmark for Financial Intelligence
May 14, 2026As AI agents improve, the central question is no longer whether they can solve isolated well-defined financial tasks, but whether they can reliably carry out financial professional work. Existing financial benchmarks offer only a partial view of this ability, as they primarily evaluate static competencies such as question answering, retrieval, summarization, and classification. We introduce Herculean, the first skilled benchmark for agentic financial intelligence spanning four representative workflows, including Trading, Hedging, Market Insights, and Auditing. Each workflow is instantiated as a standardized MCP-based skill environment with its own tools, interaction dynamics, constraints, and success criteria, enabling consistent end-to-end assessment of heterogeneous agent systems. Across frontier agents, we find agents perform relatively well on Trading and Market Insights, but struggle substantially on Hedging and Auditing, where long-horizon coordination, state consistency, and structured verification are critical. Overall, our results point to a key gap in current agents in turning financial reasoning into dependable workflow execution in high-stakes financial workflows.
Ebisu: Benchmarking Large Language Models in Japanese Finance
Feb 01, 2026Japanese finance combines agglutinative, head-final linguistic structure, mixed writing systems, and high-context communication norms that rely on indirect expression and implicit commitment, posing a substantial challenge for LLMs. We introduce Ebisu, a benchmark for native Japanese financial language understanding, comprising two linguistically and culturally grounded, expert-annotated tasks: JF-ICR, which evaluates implicit commitment and refusal recognition in investor-facing Q&A, and JF-TE, which assesses hierarchical extraction and ranking of nested financial terminology from professional disclosures. We evaluate a diverse set of open-source and proprietary LLMs spanning general-purpose, Japanese-adapted, and financial models. Results show that even state-of-the-art systems struggle on both tasks. While increased model scale yields limited improvements, language- and domain-specific adaptation does not reliably improve performance, leaving substantial gaps unresolved. Ebisu provides a focused benchmark for advancing linguistically and culturally grounded financial NLP. All datasets and evaluation scripts are publicly released.
ROAD: Responsibility-Oriented Reward Design for Reinforcement Learning in Autonomous Driving
May 30, 2025Reinforcement learning (RL) in autonomous driving employs a trial-and-error mechanism, enhancing robustness in unpredictable environments. However, crafting effective reward functions remains challenging, as conventional approaches rely heavily on manual design and demonstrate limited efficacy in complex scenarios. To address this issue, this study introduces a responsibility-oriented reward function that explicitly incorporates traffic regulations into the RL framework. Specifically, we introduced a Traffic Regulation Knowledge Graph and leveraged Vision-Language Models alongside Retrieval-Augmented Generation techniques to automate reward assignment. This integration guides agents to adhere strictly to traffic laws, thus minimizing rule violations and optimizing decision-making performance in diverse driving conditions. Experimental validations demonstrate that the proposed methodology significantly improves the accuracy of assigning accident responsibilities and effectively reduces the agent's liability in traffic incidents.
Embodied Escaping: End-to-End Reinforcement Learning for Robot Navigation in Narrow Environment
Mar 05, 2025



Autonomous navigation is a fundamental task for robot vacuum cleaners in indoor environments. Since their core function is to clean entire areas, robots inevitably encounter dead zones in cluttered and narrow scenarios. Existing planning methods often fail to escape due to complex environmental constraints, high-dimensional search spaces, and high difficulty maneuvers. To address these challenges, this paper proposes an embodied escaping model that leverages reinforcement learning-based policy with an efficient action mask for dead zone escaping. To alleviate the issue of the sparse reward in training, we introduce a hybrid training policy that improves learning efficiency. In handling redundant and ineffective action options, we design a novel action representation to reshape the discrete action space with a uniform turning radius. Furthermore, we develop an action mask strategy to select valid action quickly, balancing precision and efficiency. In real-world experiments, our robot is equipped with a Lidar, IMU, and two-wheel encoders. Extensive quantitative and qualitative experiments across varying difficulty levels demonstrate that our robot can consistently escape from challenging dead zones. Moreover, our approach significantly outperforms compared path planning and reinforcement learning methods in terms of success rate and collision avoidance.
RL-OGM-Parking: Lidar OGM-Based Hybrid Reinforcement Learning Planner for Autonomous Parking
Feb 26, 2025Autonomous parking has become a critical application in automatic driving research and development. Parking operations often suffer from limited space and complex environments, requiring accurate perception and precise maneuvering. Traditional rule-based parking algorithms struggle to adapt to diverse and unpredictable conditions, while learning-based algorithms lack consistent and stable performance in various scenarios. Therefore, a hybrid approach is necessary that combines the stability of rule-based methods and the generalizability of learning-based methods. Recently, reinforcement learning (RL) based policy has shown robust capability in planning tasks. However, the simulation-to-reality (sim-to-real) transfer gap seriously blocks the real-world deployment. To address these problems, we employ a hybrid policy, consisting of a rule-based Reeds-Shepp (RS) planner and a learning-based reinforcement learning (RL) planner. A real-time LiDAR-based Occupancy Grid Map (OGM) representation is adopted to bridge the sim-to-real gap, leading the hybrid policy can be applied to real-world systems seamlessly. We conducted extensive experiments both in the simulation environment and real-world scenarios, and the result demonstrates that the proposed method outperforms pure rule-based and learning-based methods. The real-world experiment further validates the feasibility and efficiency of the proposed method.
End-to-end Driving in High-Interaction Traffic Scenarios with Reinforcement Learning
Oct 03, 2024Dynamic and interactive traffic scenarios pose significant challenges for autonomous driving systems. Reinforcement learning (RL) offers a promising approach by enabling the exploration of driving policies beyond the constraints of pre-collected datasets and predefined conditions, particularly in complex environments. However, a critical challenge lies in effectively extracting spatial and temporal features from sequences of high-dimensional, multi-modal observations while minimizing the accumulation of errors over time. Additionally, efficiently guiding large-scale RL models to converge on optimal driving policies without frequent failures during the training process remains tricky. We propose an end-to-end model-based RL algorithm named Ramble to address these issues. Ramble processes multi-view RGB images and LiDAR point clouds into low-dimensional latent features to capture the context of traffic scenarios at each time step. A transformer-based architecture is then employed to model temporal dependencies and predict future states. By learning a dynamics model of the environment, Ramble can foresee upcoming traffic events and make more informed, strategic decisions. Our implementation demonstrates that prior experience in feature extraction and decision-making plays a pivotal role in accelerating the convergence of RL models toward optimal driving policies. Ramble achieves state-of-the-art performance regarding route completion rate and driving score on the CARLA Leaderboard 2.0, showcasing its effectiveness in managing complex and dynamic traffic situations.
HOPE: A Reinforcement Learning-based Hybrid Policy Path Planner for Diverse Parking Scenarios
May 31, 2024
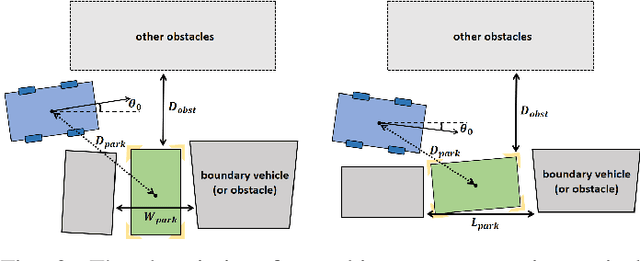


Path planning plays a pivotal role in automated parking, yet current methods struggle to efficiently handle the intricate and diverse parking scenarios. One potential solution is the reinforcement learning-based method, leveraging its exploration in unrecorded situations. However, a key challenge lies in training reinforcement learning methods is the inherent randomness in converging to a feasible policy. This paper introduces a novel solution, the Hybrid POlicy Path plannEr (HOPE), which integrates a reinforcement learning agent with Reeds-Shepp curves, enabling effective planning across diverse scenarios. The paper presents a method to calculate and implement an action mask mechanism in path planning, significantly boosting the efficiency and effectiveness of reinforcement learning training. A transformer is employed as the network structure to fuse environmental information and generate planned paths. To facilitate the training and evaluation of the proposed planner, we propose a criterion for categorizing the difficulty level of parking scenarios based on space and obstacle distribution. Experimental results demonstrate that our approach outperforms typical rule-based algorithms and traditional reinforcement learning methods, showcasing higher planning success rates and generalization across various scenarios. The code for our solution will be openly available on \href{GitHub}{https://github.com/jiamiya/HOPE}. % after the paper's acceptance.
Tactics2D: A Multi-agent Reinforcement Learning Environment for Driving Decision-making
Nov 18, 2023Tactics2D is an open-source multi-agent reinforcement learning library with a Python backend. Its goal is to provide a convenient toolset for researchers to develop decision-making algorithms for autonomous driving. The library includes diverse traffic scenarios implemented as gym-based environments equipped with multi-sensory capabilities and violation detection for traffic rules. Additionally, it features a reinforcement learning baseline tested with reasonable evaluation metrics. Tactics2D is highly modular and customizable. The source code of Tactics2D is available at https://github.com/WoodOxen/Tactics2D.
PointSIFT: A SIFT-like Network Module for 3D Point Cloud Semantic Segmentation
Jul 02, 2018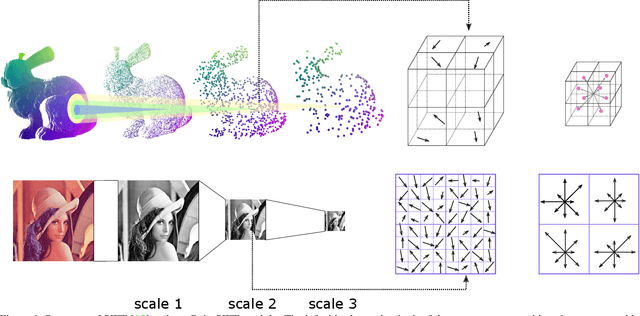



Recently, 3D understanding research pays more attention to extracting the feature from point cloud directly. Therefore, exploring shape pattern description in points is essential. Inspired by SIFT that is an outstanding 2D shape representation, we design a PointSIFT module that encodes information of different orientations and is adaptive to scale of shape. Especially, an orientation-encoding unit is designed to describe eight crucial orientations. Thus, by stacking several orientation-encoding units, we can get the multi-scale representation. Extensive experiments show our PointS IF T-based framework outperforms state-of-the-art method on standard benchmarking datasets. The code and trained model will be published accompanied by this paper.