 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Conditional Conformal Prediction via Branched Normalizing Flow
May 03, 2026Conformal prediction (CP) constructs prediction sets with marginal coverage guarantees under the assumption that the calibration and test distributions are identical. However, under distribution shift, existing approaches primarily align marginal conformal score distributions, which is sufficient to preserve marginal coverage but does not control the conditional coverage error at individual test inputs. As a consequence, CP can remain unreliable in regions where the conditional score distributions are mismatched. In this work, we bound the conditional invalidity of CP under distribution shift in terms of the Wasserstein distance between the calibration and test distributions. This result highlights the role of invertible transport in mitigating conditional coverage degradation. Motivated by this insight, we introduce Branched Normalizing Flow (BNF), a two-branch architecture that normalizes a test input to the calibration distribution and transforms the prediction set of the normalized input back to the test distribution while preserving conditional guarantees. Empirically, BNF consistently improves conditional coverage robustness on nine datasets across a wide range of confidence levels.
A Mean Field Ansatz for Zero-Shot Weight Transfer
Aug 16, 2024



The pre-training cost of large language models (LLMs) is prohibitive. One cutting-edge approach to reduce the cost is zero-shot weight transfer, also known as model growth for some cases, which magically transfers the weights trained in a small model to a large model. However, there are still some theoretical mysteries behind the weight transfer. In this paper, inspired by prior applications of mean field theory to neural network dynamics, we introduce a mean field ansatz to provide a theoretical explanation for weight transfer. Specifically, we propose the row-column (RC) ansatz under the mean field point of view, which describes the measure structure of the weights in the neural network (NN) and admits a close measure dynamic. Thus, the weights of different sizes NN admit a common distribution under proper assumptions, and weight transfer methods can be viewed as sampling methods. We empirically validate the RC ansatz by exploring simple MLP examples and LLMs such as GPT-3 and Llama-3.1. We show the mean-field point of view is adequate under suitable assumptions which can provide theoretical support for zero-shot weight transfer.
Tactics2D: A Multi-agent Reinforcement Learning Environment for Driving Decision-making
Nov 18, 2023Tactics2D is an open-source multi-agent reinforcement learning library with a Python backend. Its goal is to provide a convenient toolset for researchers to develop decision-making algorithms for autonomous driving. The library includes diverse traffic scenarios implemented as gym-based environments equipped with multi-sensory capabilities and violation detection for traffic rules. Additionally, it features a reinforcement learning baseline tested with reasonable evaluation metrics. Tactics2D is highly modular and customizable. The source code of Tactics2D is available at https://github.com/WoodOxen/Tactics2D.
Dynamic ensemble selection based on Deep Neural Network Uncertainty Estimation for Adversarial Robustness
Aug 01, 2023


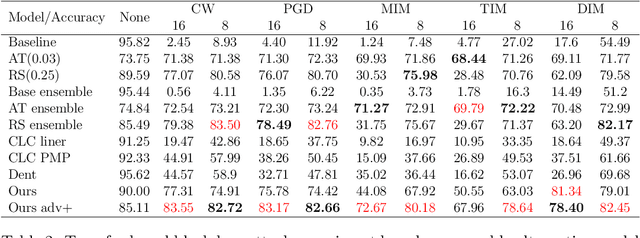
The deep neural network has attained significant efficiency in image recognition. However, it has vulnerable recognition robustness under extensive data uncertainty in practical applications. The uncertainty is attributed to the inevitable ambient noise and, more importantly, the possible adversarial attack. Dynamic methods can effectively improve the defense initiative in the arms race of attack and defense of adversarial examples. Different from the previous dynamic method depend on input or decision, this work explore the dynamic attributes in model level through dynamic ensemble selection technology to further protect the model from white-box attacks and improve the robustness. Specifically, in training phase the Dirichlet distribution is apply as prior of sub-models' predictive distribution, and the diversity constraint in parameter space is introduced under the lightweight sub-models to construct alternative ensembel model spaces. In test phase, the certain sub-models are dynamically selected based on their rank of uncertainty value for the final prediction to ensure the majority accurate principle in ensemble robustness and accuracy. Compared with the previous dynamic method and staic adversarial traning model, the presented approach can achieve significant robustness results without damaging accuracy by combining dynamics and diversity property.
Application of Machine Learning Methods in Inferring Surface Water Groundwater Exchanges using High Temporal Resolution Temperature Measurements
Jan 03, 2022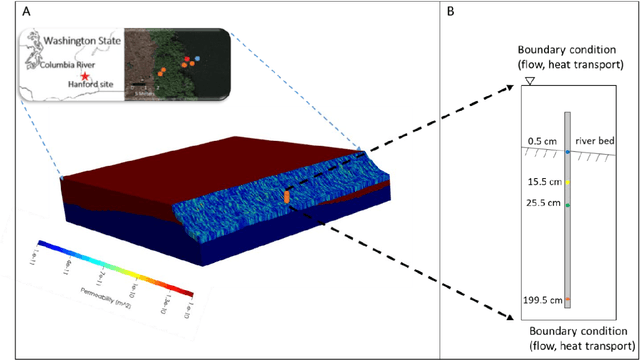

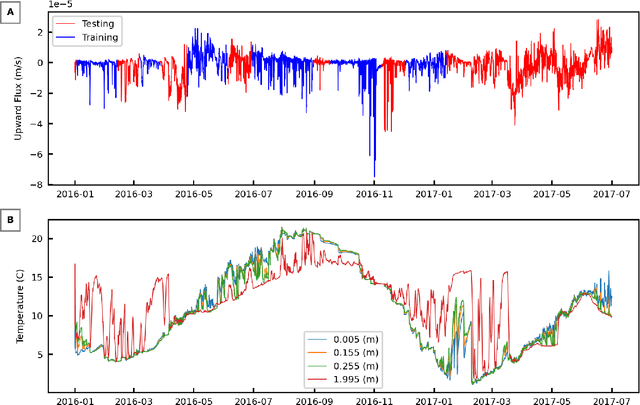
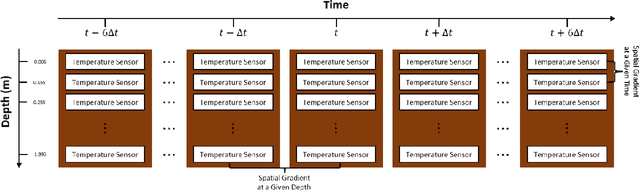
We examine the ability of machine learning (ML) and deep learning (DL) algorithms to infer surface/ground exchange flux based on subsurface temperature observations. The observations and fluxes are produced from a high-resolution numerical model representing conditions in the Columbia River near the Department of Energy Hanford site located in southeastern Washington State. Random measurement error, of varying magnitude, is added to the synthetic temperature observations. The results indicate that both ML and DL methods can be used to infer the surface/ground exchange flux. DL methods, especially convolutional neural networks, outperform the ML methods when used to interpret noisy temperature data with a smoothing filter applied. However, the ML methods also performed well and they are can better identify a reduced number of important observations, which could be useful for measurement network optimization. Surprisingly, the ML and DL methods better inferred upward flux than downward flux. This is in direct contrast to previous findings using numerical models to infer flux from temperature observations and it may suggest that combined use of ML or DL inference with numerical inference could improve flux estimation beneath river systems.
Dynamic Defense Approach for Adversarial Robustness in Deep Neural Networks via Stochastic Ensemble Smoothed Model
May 06, 2021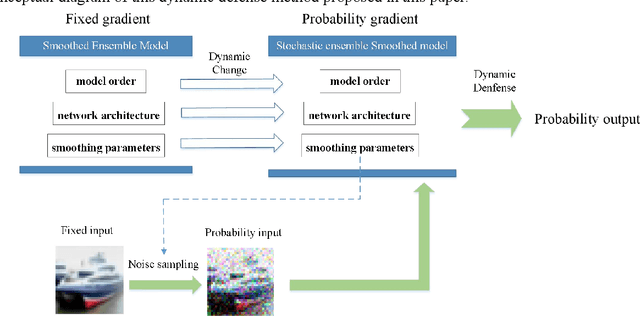
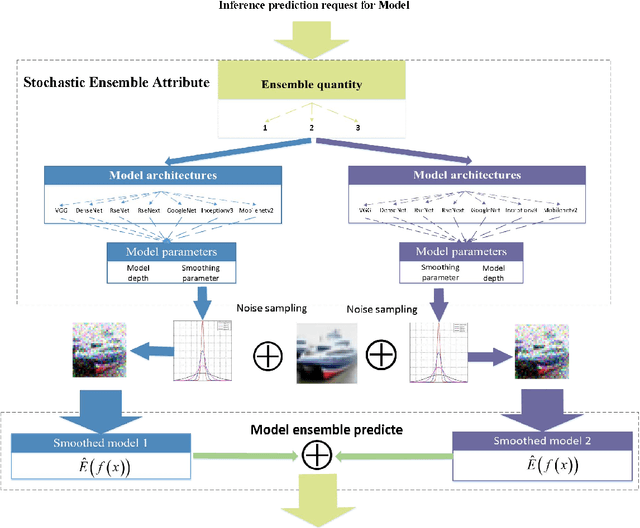
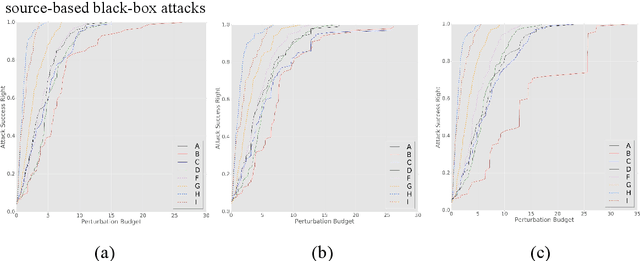
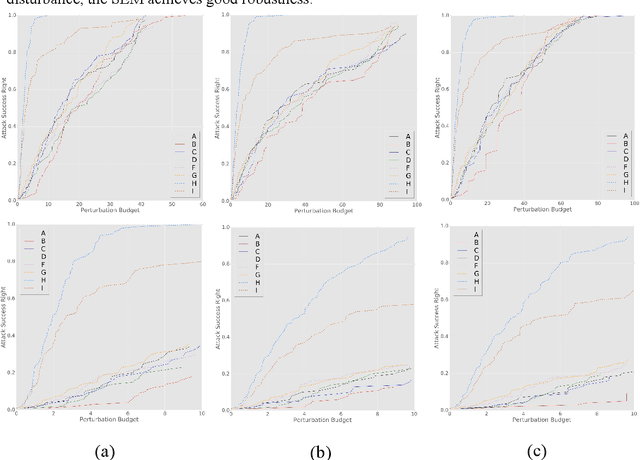
Deep neural networks have been shown to suffer from critical vulnerabilities under adversarial attacks. This phenomenon stimulated the creation of different attack and defense strategies similar to those adopted in cyberspace security. The dependence of such strategies on attack and defense mechanisms makes the associated algorithms on both sides appear as closely reciprocating processes. The defense strategies are particularly passive in these processes, and enhancing initiative of such strategies can be an effective way to get out of this arms race. Inspired by the dynamic defense approach in cyberspace, this paper builds upon stochastic ensemble smoothing based on defense method of random smoothing and model ensemble. Proposed method employs network architecture and smoothing parameters as ensemble attributes, and dynamically change attribute-based ensemble model before every inference prediction request. The proposed method handles the extreme transferability and vulnerability of ensemble models under white-box attacks. Experimental comparison of ASR-vs-distortion curves with different attack scenarios shows that even the attacker with the highest attack capability cannot easily exceed the attack success rate associated with the ensemble smoothed model, especially under untargeted attacks.
Distributional Discrepancy: A Metric for Unconditional Text Generation
May 04, 2020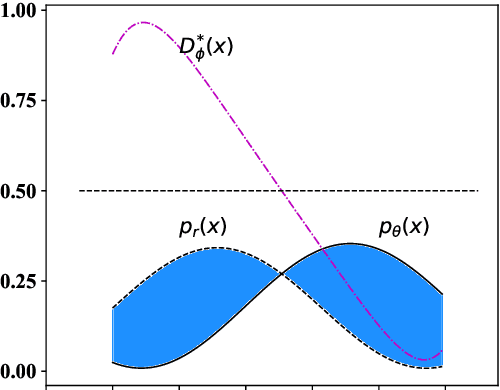

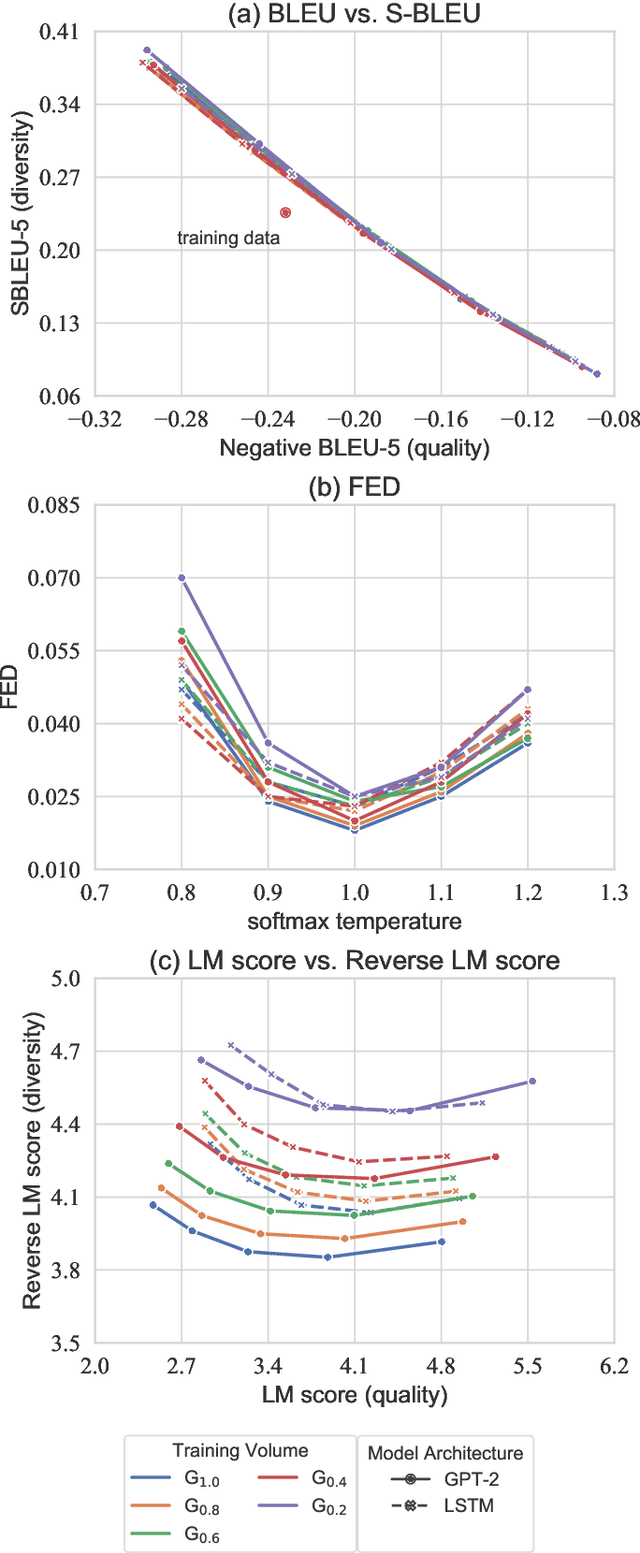
The goal of unconditional text generation is training a model with real sentences, to generate novel sentences which should be the same quality and diversity as the training data. However, when different metrics are used for comparing these methods, the contradictory conclusions are drawn. The difficulty is that both the sample diversity and the sample quality should be taken into account simultaneously, when a generative model is evaluated. To solve this issue, a novel metric of distributional discrepancy (DD) is designed to evaluate generators according to the discrepancy between the generated sentences and the real training sentences. But, a challenge is that it can't compute DD directly because the distribution of real sentences is unavailable. Thus, we propose a method to estimate DD by training a neural-network-based text classifier. For comparison, three existing metrics, Bilingual Evaluation Understudy (BLEU) verse self-BLEU, language model score verse reverse language model score, Fr'chet Embedding Distance (FED), together with the proposed DD, are used to evaluate two popular generative models of LSTM and GPT-2 on both syntactic and real data. Experimental results show DD is much better than the three existing metrics in ranking these generative models.
A Discriminator Improves Unconditional Text Generation without Updating the Generator
Apr 09, 2020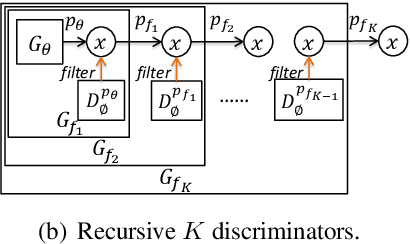
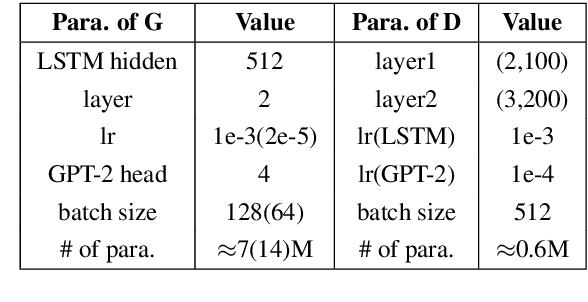
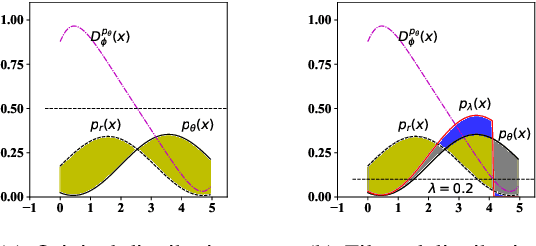
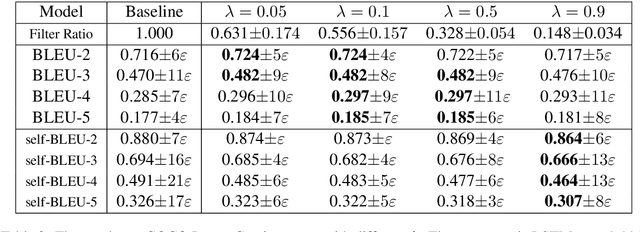
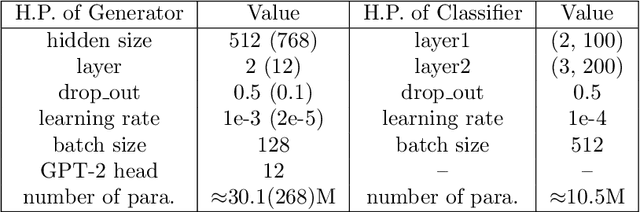
We propose a novel mechanism to improve an unconditional text generator with a discriminator, which is trained to estimate the probability that a sample comes from real or generated data. In contrast to recent discrete language generative adversarial networks (GAN) which update the parameters of the generator directly, our method only retains generated samples which are determined to come from real data with relatively high probability by the discriminator. This not only detects valuable information, but also avoids the mode collapse introduced by GAN. To the best of our knowledge, this is the first method which improves the neural language models (LM) trained with maximum likelihood estimation (MLE) by using a discriminator as a filter. Experimental results show that our mechanism improves both RNN-based and Transformer-based LMs when measuring in sample quality and sample diversity simultaneously at different softmax temperatures (a previously noted deficit of language GANs). Further, by recursively adding more discriminators, more powerful generators are created.
The Detection of Distributional Discrepancy for Text Generation
Sep 28, 2019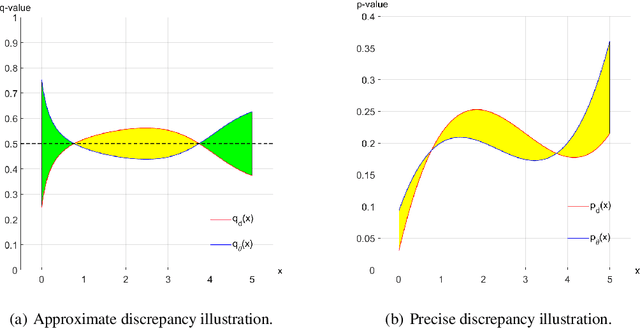


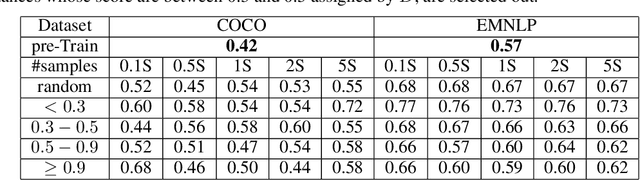
The text generated by neural language models is not as good as the real text. This means that their distributions are different. Generative Adversarial Nets (GAN) are used to alleviate it. However, some researchers argue that GAN variants do not work at all. When both sample quality (such as Bleu) and sample diversity (such as self-Bleu) are taken into account, the GAN variants even are worse than a well-adjusted language model. But, Bleu and self-Bleu can not precisely measure this distributional discrepancy. In fact, how to measure the distributional discrepancy between real text and generated text is still an open problem. In this paper, we theoretically propose two metric functions to measure the distributional difference between real text and generated text. Besides that, a method is put forward to estimate them. First, we evaluate language model with these two functions and find the difference is huge. Then, we try several methods to use the detected discrepancy signal to improve the generator. However the difference becomes even bigger than before. Experimenting on two existing language GANs, the distributional discrepancy between real text and generated text increases with more adversarial learning rounds. It demonstrates both of these language GANs fail.
Adversarial Sub-sequence for Text Generation
May 30, 2019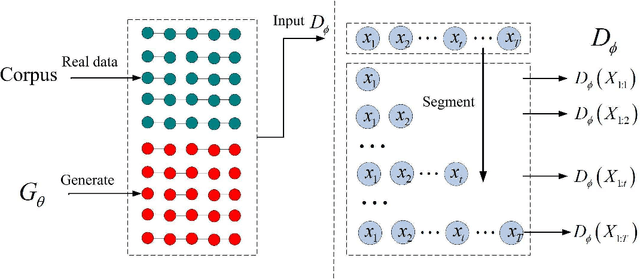

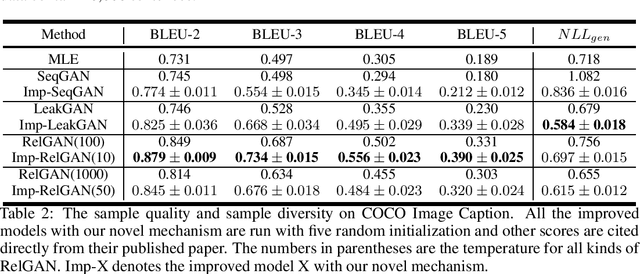
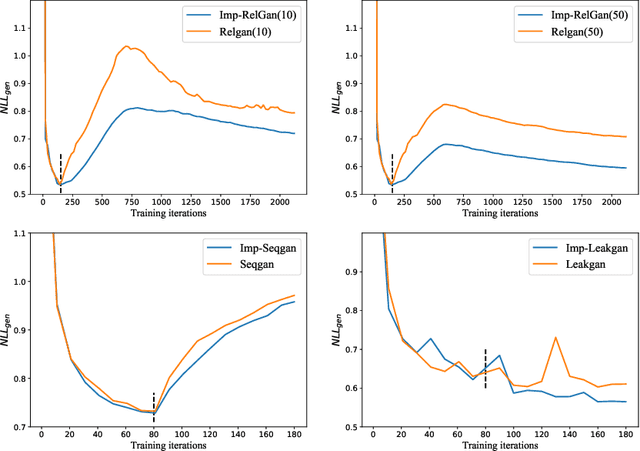
Generative adversarial nets (GAN) has been successfully introduced for generating text to alleviate the exposure bias. However, discriminators in these models only evaluate the entire sequence, which causes feedback sparsity and mode collapse. To tackle these problems, we propose a novel mechanism. It first segments the entire sequence into several sub-sequences. Then these sub-sequences, together with the entire sequence, are evaluated individually by the discriminator. At last these feedback signals are all used to guide the learning of GAN. This mechanism learns the generation of both the entire sequence and the sub-sequences simultaneously. Learning to generate sub-sequences is easy and is helpful in generating an entire sequence. It is easy to improve the existing GAN-based models with this mechanism. We rebuild three previous well-designed models with our mechanism, and the experimental results on benchmark data show these models are improved significantly, the best one outperforms the state-of-the-art model.\footnote[1]{All code and data are available at https://github.com/liyzcj/seggan.git