 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mean Field Ansatz for Zero-Shot Weight Transfer
Aug 16, 2024



The pre-training cost of large language models (LLMs) is prohibitive. One cutting-edge approach to reduce the cost is zero-shot weight transfer, also known as model growth for some cases, which magically transfers the weights trained in a small model to a large model. However, there are still some theoretical mysteries behind the weight transfer. In this paper, inspired by prior applications of mean field theory to neural network dynamics, we introduce a mean field ansatz to provide a theoretical explanation for weight transfer. Specifically, we propose the row-column (RC) ansatz under the mean field point of view, which describes the measure structure of the weights in the neural network (NN) and admits a close measure dynamic. Thus, the weights of different sizes NN admit a common distribution under proper assumptions, and weight transfer methods can be viewed as sampling methods. We empirically validate the RC ansatz by exploring simple MLP examples and LLMs such as GPT-3 and Llama-3.1. We show the mean-field point of view is adequate under suitable assumptions which can provide theoretical support for zero-shot weight transfer.
SPPNet: A Single-Point Prompt Network for Nuclei Image Segmentation
Aug 23, 2023Image segmentation plays an essential role in nuclei image analysis. Recently, the segment anything model has made a significant breakthrough in such tasks. However, the current model exists two major issues for cell segmentation: (1) the image encoder of the segment anything model involves a large number of parameters. Retraining or even fine-tuning the model still requires expensive computational resources. (2) in point prompt mode, points are sampled from the center of the ground truth and more than one set of points is expected to achieve reliable performance, which is not efficient for practical applications. In this paper, a single-point prompt network is proposed for nuclei image segmentation, called SPPNet. We replace the original image encoder with a lightweight vision transformer. Also, an effective convolutional block is added in parallel to extract the low-level semantic information from the image and compensate for the performance degradation due to the small image encoder. We propose a new point-sampling method based on the Gaussian kernel. The proposed model is evaluated on the MoNuSeg-2018 dataset. The result demonstrated that SPPNet outperforms existing U-shape architectures and shows faster convergence in training. Compared to the segment anything model, SPPNet shows roughly 20 times faster inference, with 1/70 parameters and computational cost. Particularly, only one set of points is required in both the training and inference phases, which is more reasonable for clinical applications. The code for our work and more technical details can be found at https://github.com/xq141839/SPPNet.
Task-specific Fine-tuning via Variational Information Bottleneck for Weakly-supervised Pathology Whole Slide Image Classification
Mar 15, 2023While Multiple Instance Learning (MIL) has shown promising results in digital Pathology Whole Slide Image (WSI) classification, such a paradigm still faces performance and generalization problems due to challenges in high computational costs on Gigapixel WSIs and limited sample size for model training. To deal with the computation problem, most MIL methods utilize a frozen pretrained model from ImageNet to obtain representations first. This process may lose essential information owing to the large domain gap and hinder the generalization of model due to the lack of image-level training-time augmentations. Though Self-supervised Learning (SSL) proposes viable representation learning schemes, the improvement of the downstream task still needs to be further explored in the conversion from the task-agnostic features of SSL to the task-specifics under the partial label supervised learning. To alleviate the dilemma of computation cost and performance, we propose an efficient WSI fine-tuning framework motivated by the Information Bottleneck theory. The theory enables the framework to find the minimal sufficient statistics of WSI, thus supporting us to fine-tune the backbone into a task-specific representation only depending on WSI-level weak labels. The WSI-MIL problem is further analyzed to theoretically deduce our fine-tuning method. Our framework is evaluated on five pathology WSI datasets on various WSI heads. The experimental results of our fine-tuned representations show significant improvements in both accuracy and generalization compared with previous works. Source code will be available at https://github.com/invoker-LL/WSI-finetuning.
Online Robot Introspection via Wrench-based Action Grammars
Jul 19, 2017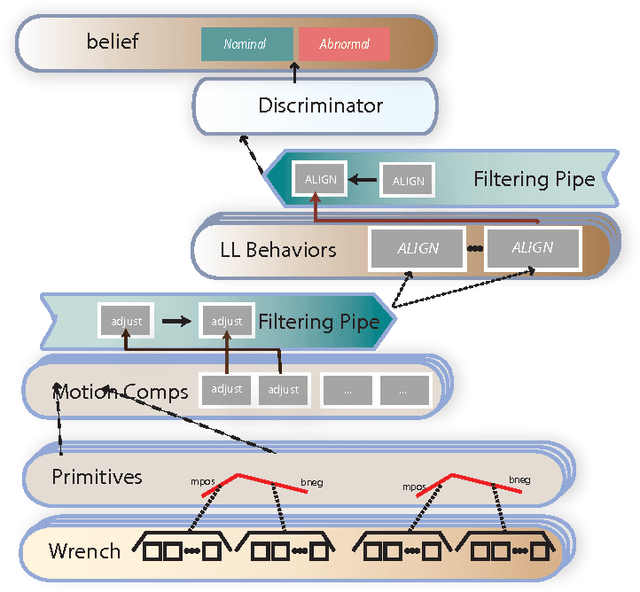
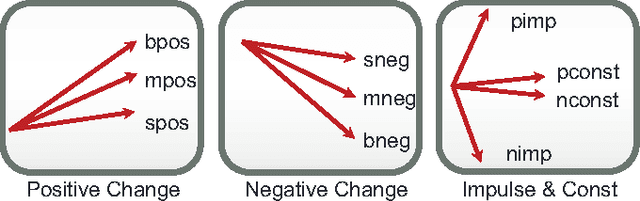
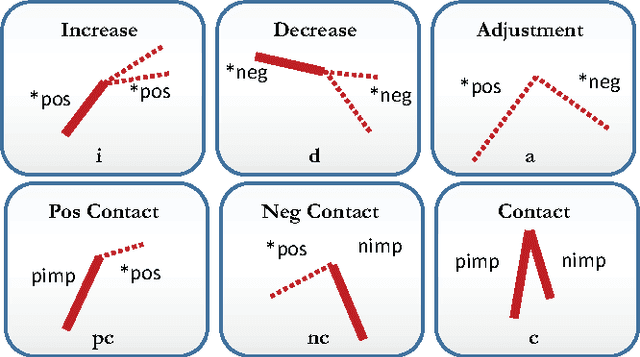

Robotic failure is all too common in unstructured robot tasks. Despite well-designed controllers, robots often fail due to unexpected events. How do robots measure unexpected events? Many do not. Most robots are driven by the sense-plan act paradigm, however more recently robots are undergoing a sense-plan-act-verify paradigm. In this work, we present a principled methodology to bootstrap online robot introspection for contact tasks. In effect, we are trying to enable the robot to answer the question: what did I do? Is my behavior as expected or not? To this end, we analyze noisy wrench data and postulate that the latter inherently contains patterns that can be effectively represented by a vocabulary. The vocabulary is generated by segmenting and encoding the data. When the wrench information represents a sequence of sub-tasks, we can think of the vocabulary forming a sentence (set of words with grammar rules) for a given sub-task; allowing the latter to be uniquely represented. The grammar, which can also include unexpected events, was classified in offline and online scenarios as well as for simulated and real robot experiments. Multiclass Support Vector Machines (SVMs) were used offline, while online probabilistic SVMs were are used to give temporal confidence to the introspection result. The contribution of our work is the presentation of a generalizable online semantic scheme that enables a robot to understand its high-level state whether nominal or abnormal. It is shown to work in offline and online scenarios for a particularly challenging contact task: snap assemblies. We perform the snap assembly in one-arm simulated and real one-arm experiments and a simulated two-arm experiment. This verification mechanism can be used by high-level planners or reasoning systems to enable intelligent failure recovery or determine the next most optima manipulation skill to be used.