 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models for General Surgical Grasping
May 28, 2024



Intelligent vision control systems for surgical robots should adapt to unknown and diverse objects while being robust to system disturbances. Previous methods did not meet these requirements due to mainly relying on pose estimation and feature tracking. We propose a world-model-based deep reinforcement learning framework "Grasp Anything for Surgery" (GAS), that learns a pixel-level visuomotor policy for surgical grasping, enhancing both generality and robustness. In particular, a novel method is proposed to estimate the values and uncertainties of depth pixels for a rigid-link object's inaccurate region based on the empirical prior of the object's size; both depth and mask images of task objects are encoded to a single compact 3-channel image (size: 64x64x3) by dynamically zooming in the mask regions, minimizing the information loss. The learned controller's effectiveness is extensively evaluated in simulation and in a real robot. Our learned visuomotor policy handles: i) unseen objects, including 5 types of target grasping objects and a robot gripper, in unstructured real-world surgery environments, and ii) disturbances in perception and control. Note that we are the first work to achieve a unified surgical control system that grasps diverse surgical objects using different robot grippers on real robots in complex surgery scenes (average success rate: 69%). Our system also demonstrates significant robustness across 6 conditions including background variation, target disturbance, camera pose variation, kinematic control error, image noise, and re-grasping after the gripped target object drops from the gripper. Videos and codes can be found on our project page: https://linhongbin.github.io/gas/.
Towards Safe Control of Continuum Manipulator Using Shielded Multiagent Reinforcement Learning
Jun 15, 2021
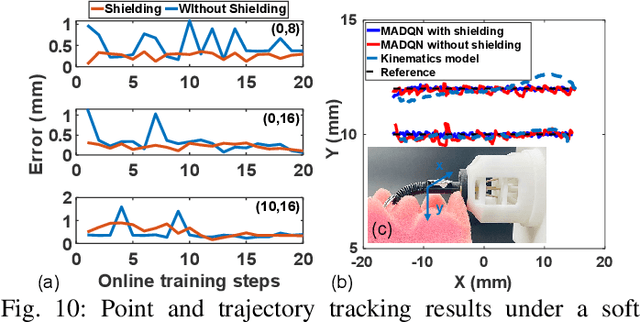
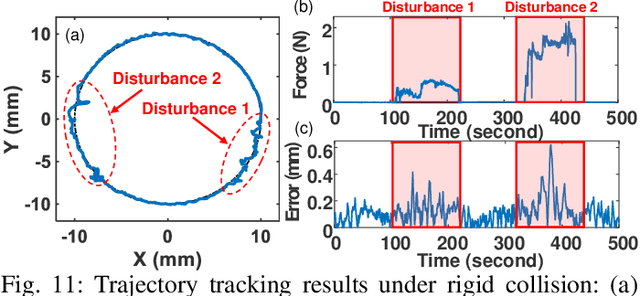
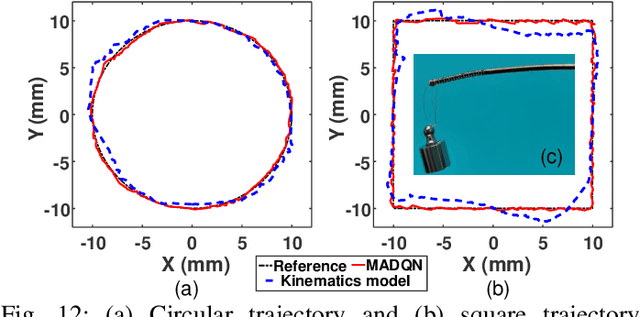
Continuum robotic manipulators are increasingly adopted in minimal invasive surgery. However, their nonlinear behavior is challenging to model accurately, especially when subject to external interaction, potentially leading to poor control performance. In this letter, we investigate the feasibility of adopting a model-free multiagent reinforcement learning (RL), namely multiagent deep Q network (MADQN), to control a 2-degree of freedom (DoF) cable-driven continuum surgical manipulator. The control of the robot is formulated as a one-DoF, one agent problem in the MADQN framework to improve the learning efficiency. Combined with a shielding scheme that enables dynamic variation of the action set boundary, MADQN leads to efficient and importantly safer control of the robot. Shielded MADQN enabled the robot to perform point and trajectory tracking with submillimeter root mean square errors under external loads, soft obstacles, and rigid collision, which are common interaction scenarios encountered by surgical manipulators. The controller was further proven to be effective in a miniature continuum robot with high structural nonlinearitiy, achieving trajectory tracking with submillimeter accuracy under external payload.
Error Identification and Recovery in Robotic Snap Assembly
Mar 24, 2021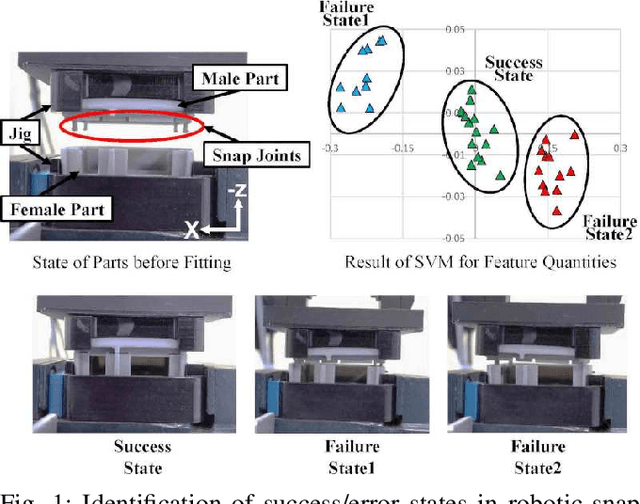
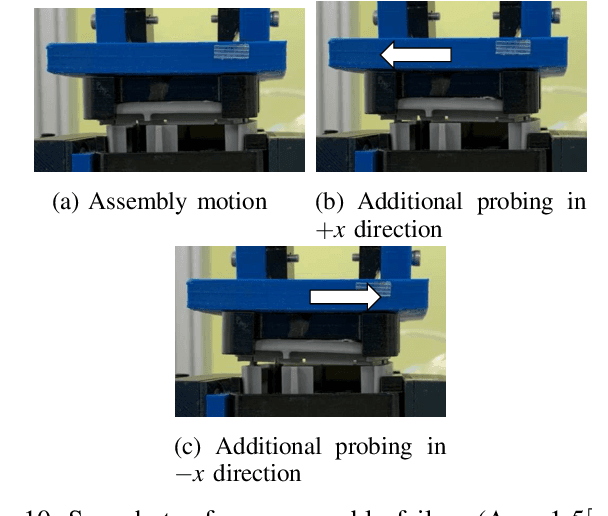
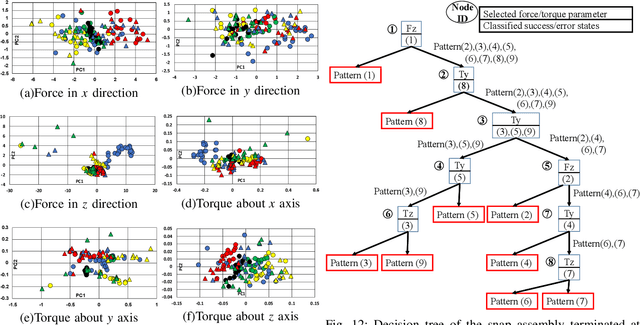
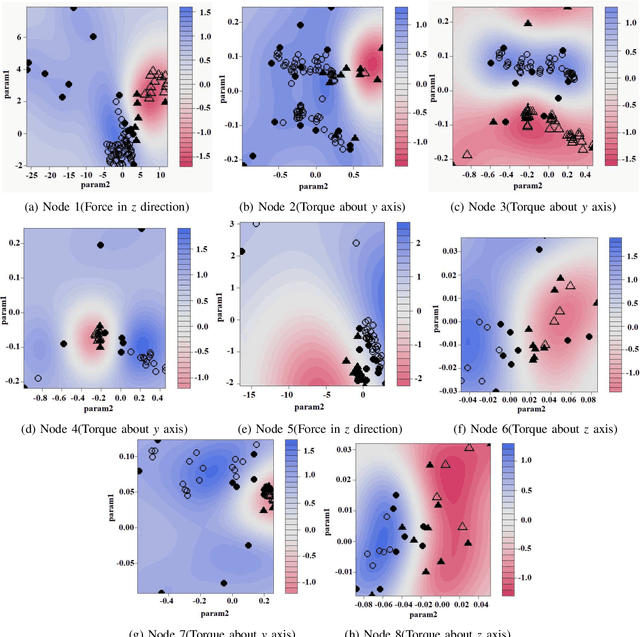
Existing methods for predicting robotic snap joint assembly cannot predict failures before their occurrence. To address this limitation, this paper proposes a method for predicting error states before the occurence of error, thereby enabling timely recovery. Robotic snap joint assembly requires precise positioning; therefore, even a slight offset between parts can lead to assembly failure. To correctly predict error states, we apply functional principal component analysis (fPCA) to 6D force/torque profiles that are terminated before the occurence of an error. The error state is identified by applying a feature vector to a decision tree, wherein the support vector machine (SVM) is employed at each node. If the estimation accuracy is low, we perform additional probing to more correctly identify the error state. Finally, after identifying the error state, a robot performs the error recovery motion based on the identified error state. Through the experimental results of assembling plastic parts with four snap joints, we show that the error states can be correctly estimated and a robot can recover from the identified error state.
Hyperparameter Auto-tuning in Self-Supervised Robotic Learning
Oct 19, 2020


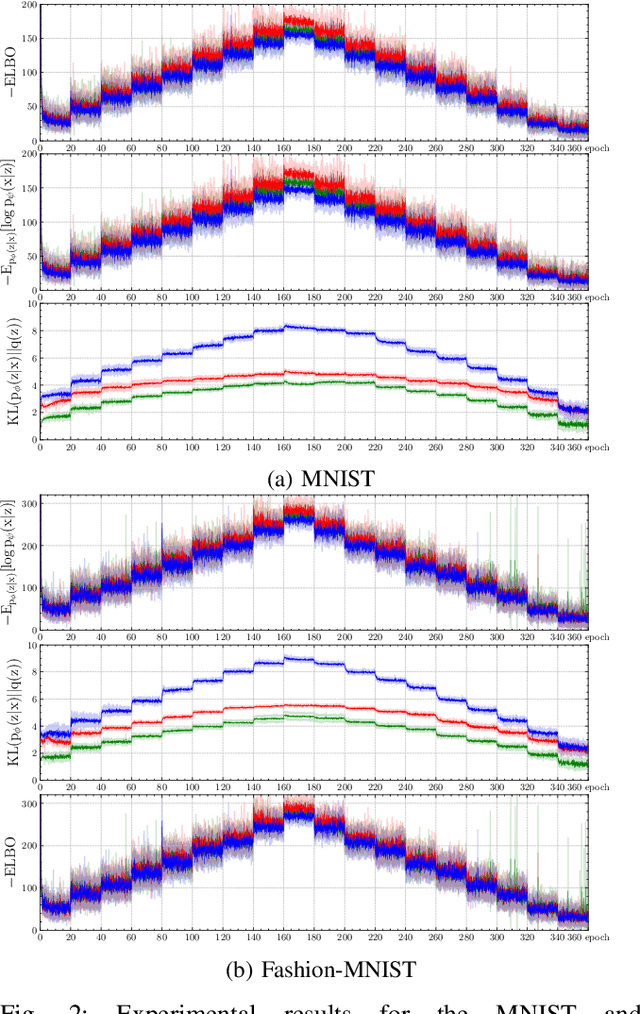
Policy optimization in reinforcement learning requires the selection of numerous hyperparameters across different environments. Fixing them incorrectly may negatively impact optimization performance leading notably to insufficient or redundant learning. Insufficient learning (due to convergence to local optima) results in under-performing policies whilst redundant learning wastes time and resources. The effects are further exacerbated when using single policies to solve multi-task learning problems. In this paper, we study how the Evidence Lower Bound (ELBO) used in Variational Auto-Encoders (VAEs) is affected by the diversity of image samples. Different tasks or setups in visual reinforcement learning incur varying diversity. We exploit the ELBO to create an auto-tuning technique in self-supervised reinforcement learning. Our approach can auto-tune three hyperparameters: the replay buffer size, the number of policy gradient updates during each epoch, and the number of exploration steps during each epoch. We use the state-of-the-art self-supervised robotic learning framework (Reinforcement Learning with Imagined Goals (RIG) using Soft Actor-Critic) as baseline for experimental verification. Experiments show that our method can auto-tune online and yields the best performance at a fraction of the time and computational resources. Code, video, and appendix for simulated and real-robot experiments can be found at http://www.JuanRojas.net/autotune.
Pose-based Modular Network for Human-Object Interaction Detection
Aug 05, 2020
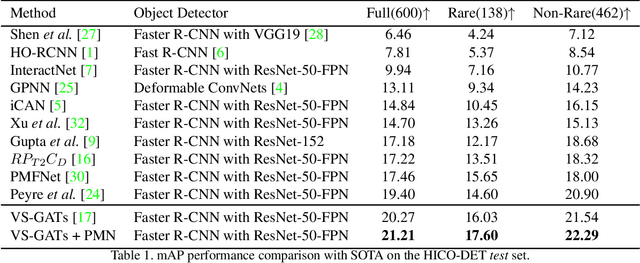
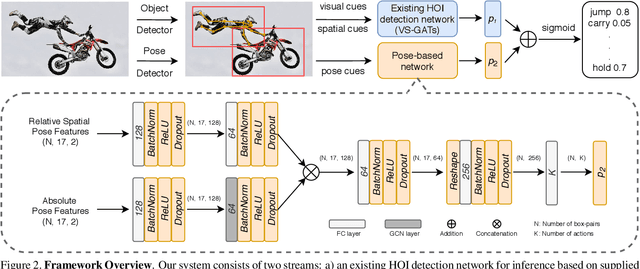
Human-object interaction(HOI) detection is a critical task in scene understanding. The goal is to infer the triplet <subject, predicate, object> in a scene. In this work, we note that the human pose itself as well as the relative spatial information of the human pose with respect to the target object can provide informative cues for HOI detection. We contribute a Pose-based Modular Network (PMN) which explores the absolute pose features and relative spatial pose features to improve HOI detection and is fully compatible with existing networks. Our module consists of a branch that first processes the relative spatial pose features of each joint independently. Another branch updates the absolute pose features via fully connected graph structures. The processed pose features are then fed into an action classifier. To evaluate our proposed method, we combine the module with the state-of-the-art model named VS-GATs and obtain significant improvement on two public benchmarks: V-COCO and HICO-DET, which shows its efficacy and flexibility. Code is available at \url{https://github.com/birlrobotics/PMN}.
GAST-Net: Graph Attention Spatio-temporal Convolutional Networks for 3D Human Pose Estimation in Video
Mar 11, 2020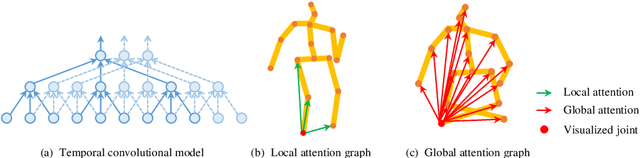
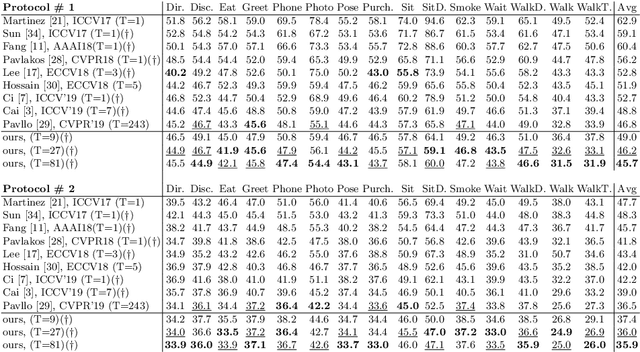
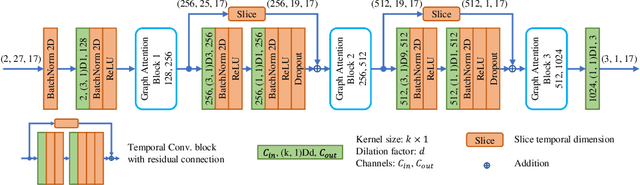

3D pose estimation in video can benefit greatly from both temporal and spatial information. Occlusions and depth ambiguities remain outstanding problems. In this work, we study how to learn the kinematic constraints of the human skeleton by modeling additional spatial information through attention and interleaving it in a synergistic way with temporal models. We contribute a graph attention spatio-temporal convolutional network (GAST-Net) that makes full use of spatio-temporal information and mitigates the problems of occlusion and depth ambiguities. We also contribute attention mechanisms that learn inter-joint relations that are easily visualizable. GAST-Net comprises of interleaved temporal convolutional and graph attention blocks. We use dilated temporal convolution networks (TCNs) to model long-term patterns. More critically, graph attention blocks encode local and global representations through novel convolutional kernels that express human skeletal symmetrical structure and adaptively extract global semantics over time. GAST-Net outperforms SOTA by approximately 10\% for mean per-joint position error for ground-truth labels on Human3.6M and achieves competitive results on HumanEva-I.
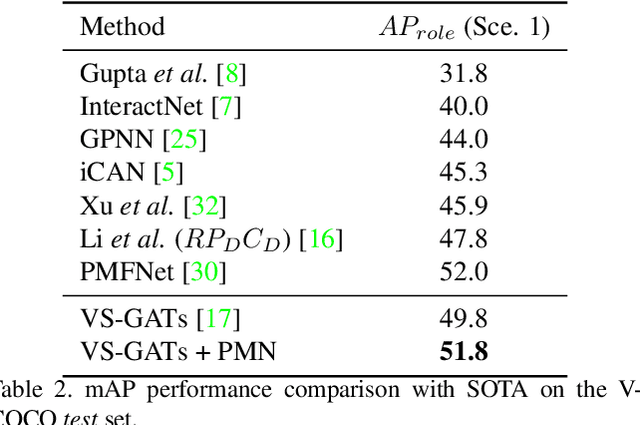
Visual-Semantic Graph Attention Network for Human-Object Interaction Detection
Jan 07, 2020
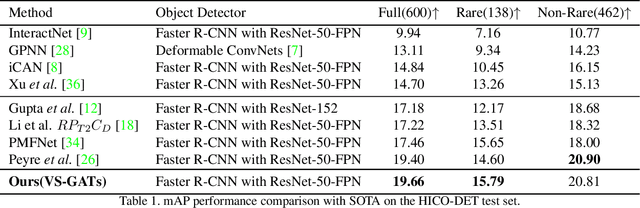
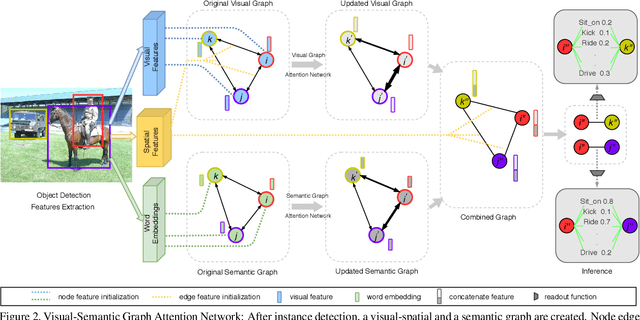
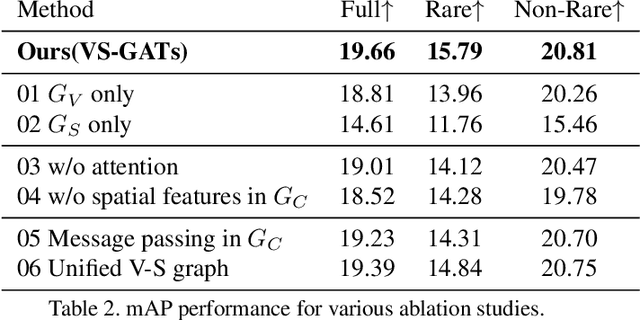
In scene understanding, machines benefit from not only detecting individual scene instances but also from learning their possible interactions. Human-Object Interaction (HOI) Detection tries to infer the predicate on a <subject,predicate,object> triplet. Contextual information has been found critical in inferring interactions. However, most works use features from single object instances that have a direct relation with the subject. Few works have studied the disambiguating contribution of subsidiary relations in addition to how attention might leverage them for inference. We contribute a dual-graph attention network that aggregates contextual visual, spatial, and semantic information dynamically for primary subject-object relations as well as subsidiary relations. Graph attention networks dynamically leverage node neighborhood information. Our network uses attention to first leverage visual-spatial and semantic cues from primary and subsidiary relations independently and then combines them before a final readout step. Our network learns to use primary and subsidiary relations to improve inference: encouraging the right interpretations and discouraging incorrect ones. We call our model: Visual-Semantic Graph Attention Networks (VS-GATs). We surpass state-of-the-art HOI detection mAPs in the challenging HICO-DET dataset, including in long-tail cases that are harder to interpret. Code, video, and supplementary information is available at http://www.juanrojas.net/VSGAT.
Towards More Sample Efficiency in Reinforcement Learning with Data Augmentation
Nov 15, 2019
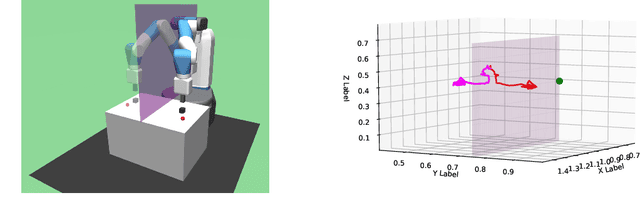

Deep reinforcement learning (DRL) is a promising approach for adaptive robot control, but its current application to robotics is currently hindered by high sample requirements. We propose two novel data augmentation techniques for DRL in order to reuse more efficiently observed data. The first one called Kaleidoscope Experience Replay exploits reflectional symmetries, while the second called Goal-augmented Experience Replay takes advantage of lax goal definitions. Our preliminary experimental results show a large increase in learning speed.
Invariant Transform Experience Replay
Oct 10, 2019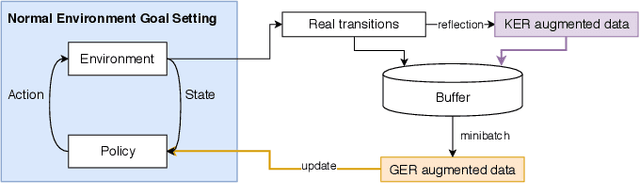
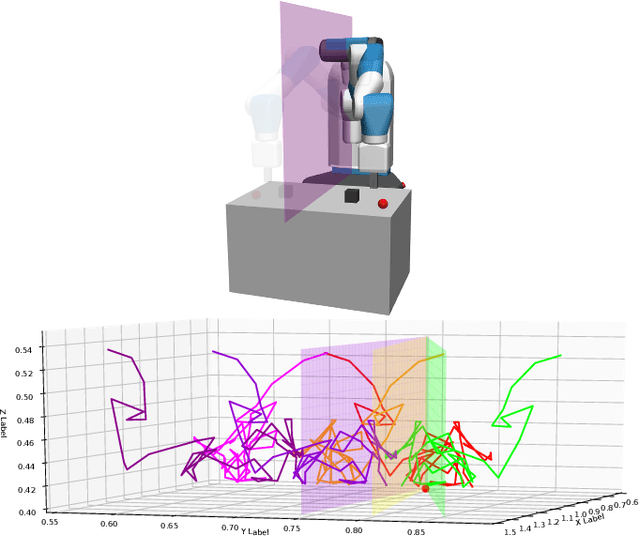
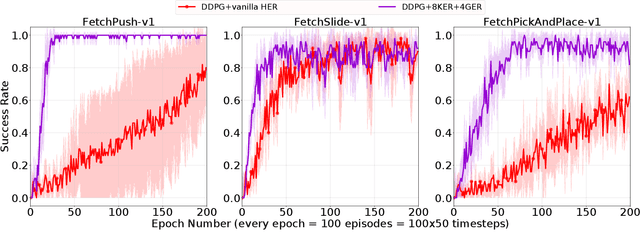
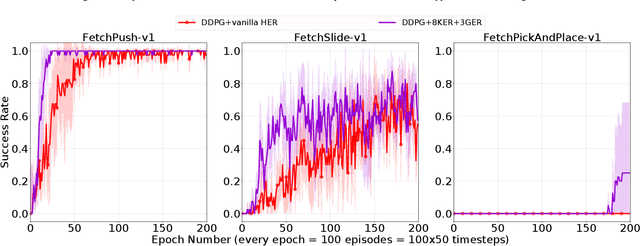
Deep reinforcement learning (DRL) is a promising approach for adaptive robot control, but its current application to robotics is currently hindered by high sample requirements. We propose two novel data augmentation techniques for DRL based on invariant transformations of trajectories in order to reuse more efficiently observed interaction. The first one called Kaleidoscope Experience Replay exploits reflectional symmetries, while the second called Goal-augmented Experience Replay takes advantage of lax goal definitions. In the Fetch tasks from OpenAI Gym, our experimental results show a large increase in learning speed.
Dynamic Interaction Probabilistic Movement Primitives
Jan 30, 2019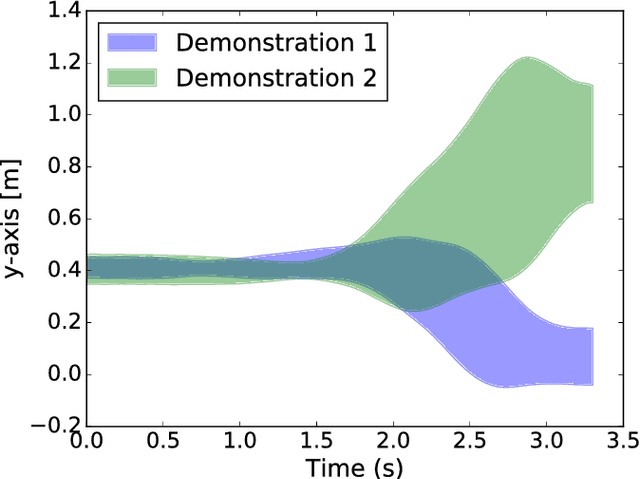
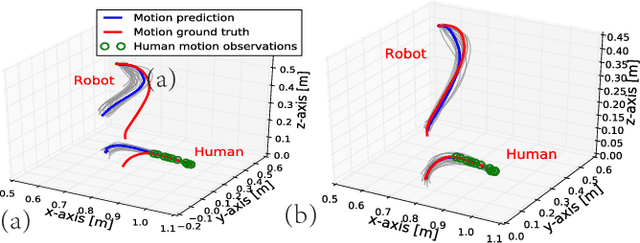
Human-robot collaboration is on the rise. Robots need to increasingly improve the efficiency and smoothness with which they assist humans by properly anticipating a human's intention. To do so, prediction models need to increase their accuracy and responsiveness. This work builds on top of Interaction Movement Primitives with phase estimation and re-formulates the framework to use dynamic human-motion observations which constantly update anticipatory motions. The original framework only considers a single fixed-duration static human observation which is used to perform only one anticipatory motion. Dynamic observations, with built-in phase estimation, yield a series of updated robot motion distributions. Co-activation is performed between the existing and newest most probably robot motion distribution. This results in smooth anticipatory robot motions that are highly accurate and with enhanced responsiveness.