 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperparameter Auto-tuning in Self-Supervised Robotic Learning
Paper and Code



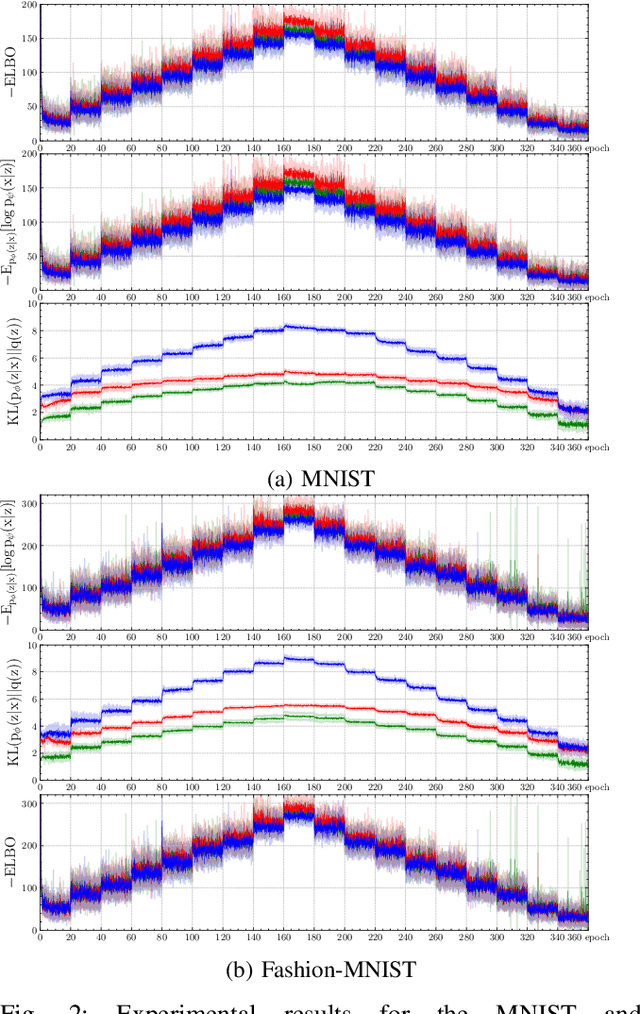
Policy optimization in reinforcement learning requires the selection of numerous hyperparameters across different environments. Fixing them incorrectly may negatively impact optimization performance leading notably to insufficient or redundant learning. Insufficient learning (due to convergence to local optima) results in under-performing policies whilst redundant learning wastes time and resources. The effects are further exacerbated when using single policies to solve multi-task learning problems. In this paper, we study how the Evidence Lower Bound (ELBO) used in Variational Auto-Encoders (VAEs) is affected by the diversity of image samples. Different tasks or setups in visual reinforcement learning incur varying diversity. We exploit the ELBO to create an auto-tuning technique in self-supervised reinforcement learning. Our approach can auto-tune three hyperparameters: the replay buffer size, the number of policy gradient updates during each epoch, and the number of exploration steps during each epoch. We use the state-of-the-art self-supervised robotic learning framework (Reinforcement Learning with Imagined Goals (RIG) using Soft Actor-Critic) as baseline for experimental verification. Experiments show that our method can auto-tune online and yields the best performance at a fraction of the time and computational resources. Code, video, and appendix for simulated and real-robot experiments can be found at http://www.JuanRojas.net/autotune.