 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWCF-Net: Similarity-weighted Convolution and Local-global Fusion for Efficient Large-scale Point Cloud Semantic Segmentation
Jun 17, 2024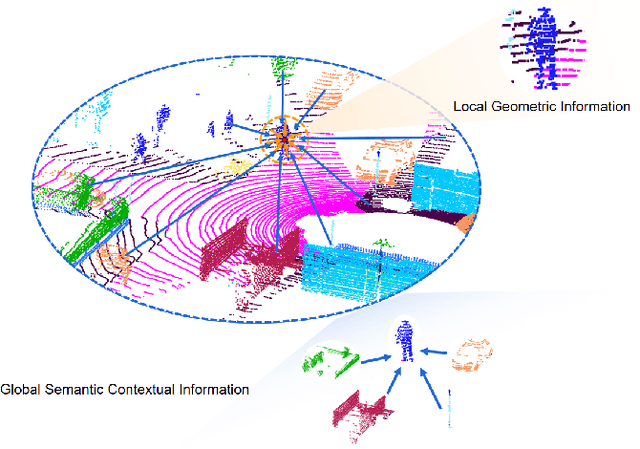
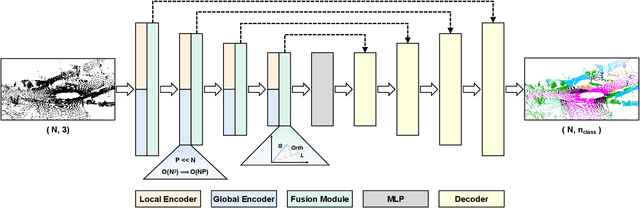
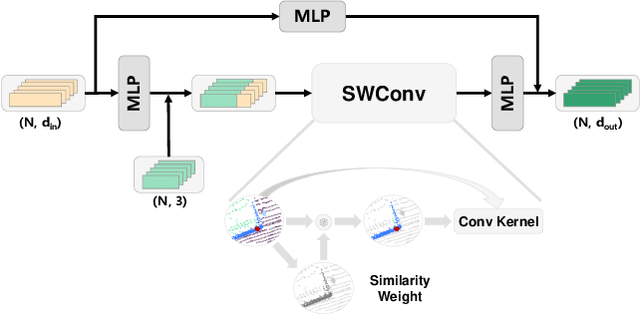
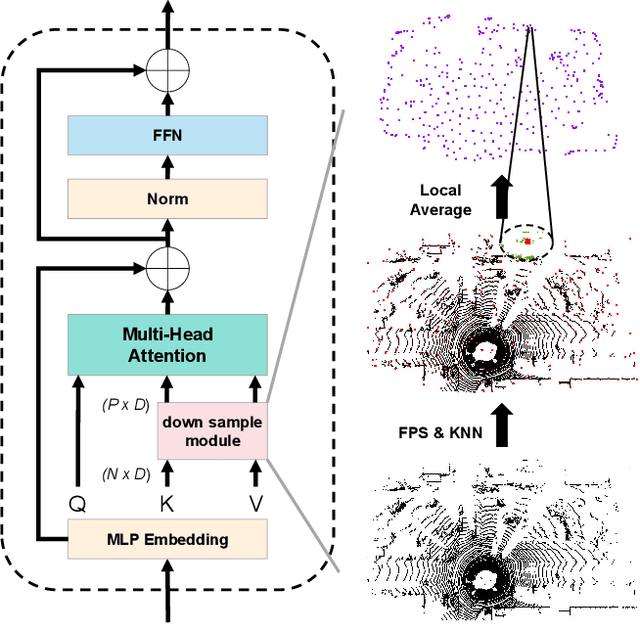
Large-scale point cloud consists of a multitude of individual objects, thereby encompassing rich structural and underlying semantic contextual information, resulting in a challenging problem in efficiently segmenting a point cloud. Most existing researches mainly focus on capturing intricate local features without giving due consideration to global ones, thus failing to leverage semantic context. In this paper, we propose a Similarity-Weighted Convolution and local-global Fusion Network, named SWCF-Net, which takes into account both local and global features. We propose a Similarity-Weighted Convolution (SWConv) to effectively extract local features, where similarity weights are incorporated into the convolution operation to enhance the generalization capabilities. Then, we employ a downsampling operation on the K and V channels within the attention module, thereby reducing the quadratic complexity to linear, enabling the Transformer to deal with large-scale point clouds. At last, orthogonal components are extracted in the global features and then aggregated with local features, thereby eliminating redundant information between local and global features and consequently promoting efficiency. We evaluate SWCF-Net on large-scale outdoor datasets SemanticKITTI and Toronto3D. Our experimental results demonstrate the effectiveness of the proposed network. Our method achieves a competitive result with less computational cost, and is able to handle large-scale point clouds efficiently.
NDD: A 3D Point Cloud Descriptor Based on Normal Distribution for Loop Closure Detection
Sep 26, 2022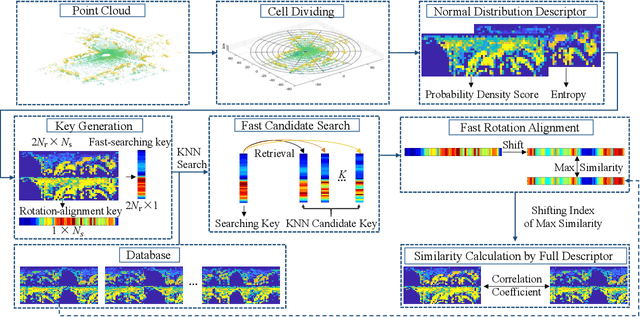
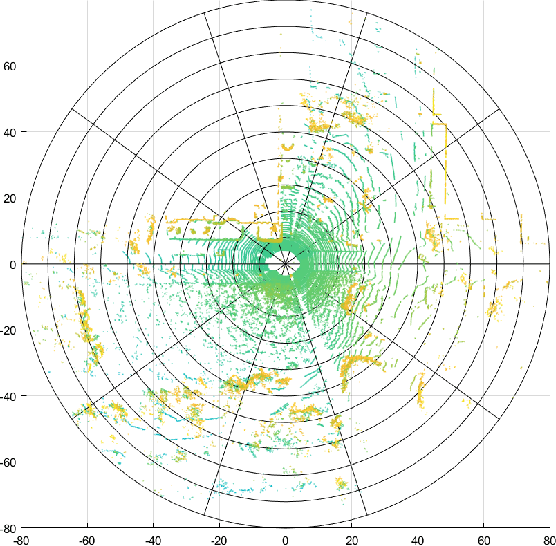
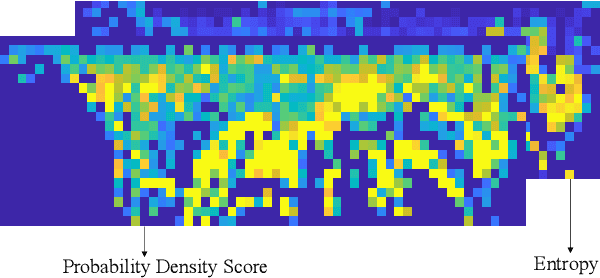

Loop closure detection is a key technology for long-term robot navigation in complex environments. In this paper, we present a global descriptor, named Normal Distribution Descriptor (NDD), for 3D point cloud loop closure detection. The descriptor encodes both the probability density score and entropy of a point cloud as the descriptor. We also propose a fast rotation alignment process and use correlation coefficient as the similarity between descriptors. Experimental results show that our approach outperforms the state-of-the-art point cloud descriptors in both accuracy and efficency. The source code is available and can be integrated into existing LiDAR odometry and mapping (LOAM) systems.
Perspective Phase Angle Model for Polarimetric 3D Reconstruction
Jul 21, 2022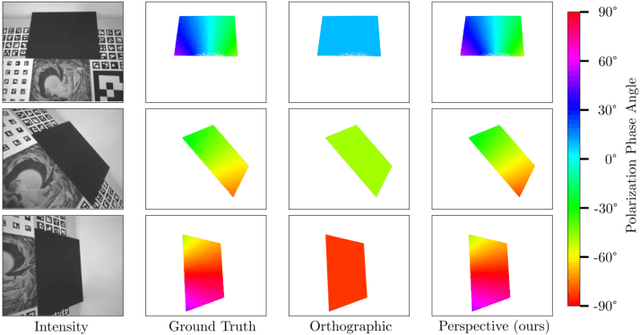

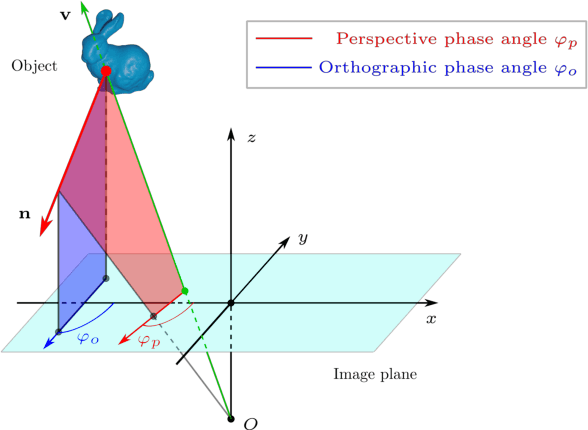
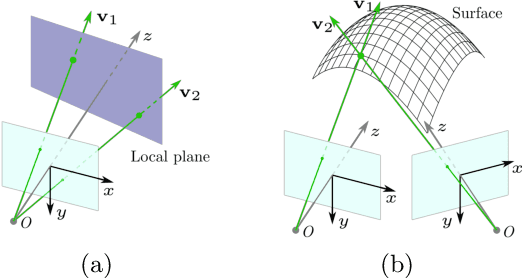
Current polarimetric 3D reconstruction methods, including those in the well-established shape from polarization literature, are all developed under the orthographic projection assumption. In the case of a large field of view, however, this assumption does not hold and may result in significant reconstruction errors in methods that make this assumption. To address this problem, we present the perspective phase angle (PPA) model that is applicable to perspective cameras. Compared with the orthographic model, the proposed PPA model accurately describes the relationship between polarization phase angle and surface normal under perspective projection. In addition, the PPA model makes it possible to estimate surface normals from only one single-view phase angle map and does not suffer from the so-called $\pi$-ambiguity problem. Experiments on real data show that the PPA model is more accurate for surface normal estimation with a perspective camera than the orthographic model.
Mapping While Following: 2D LiDAR SLAM in Indoor Dynamic Environments with a Person Tracker
Apr 18, 2022
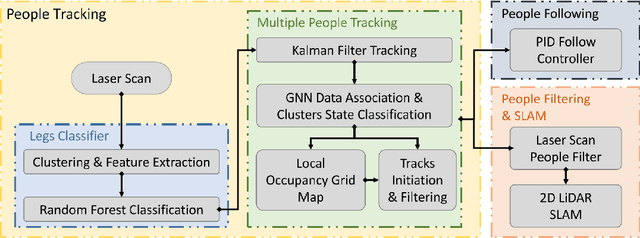

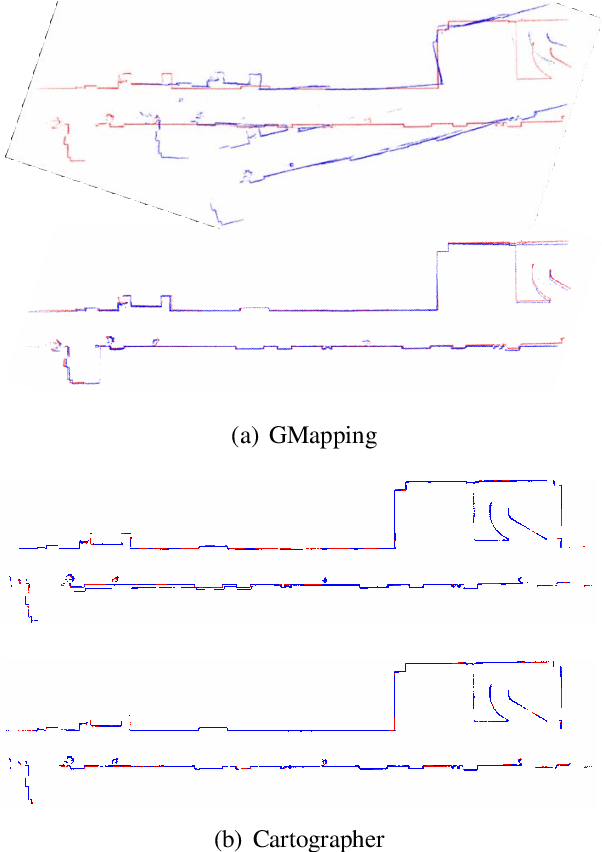
2D LiDAR SLAM (Simultaneous Localization and Mapping) is widely used in indoor environments due to its stability and flexibility. However, its mapping procedure is usually operated by a joystick in static environments, while indoor environments often are dynamic with moving objects such as people. The generated map with noisy points due to the dynamic objects is usually incomplete and distorted. To address this problem, we propose a framework of 2D-LiDAR-based SLAM without manual control that effectively excludes dynamic objects (people) and simplify the process for a robot to map an environment. The framework, which includes three parts: people tracking, filtering and following. We verify our proposed framework in experiments with two classic 2D-LiDAR-based SLAM algorithms in indoor environments. The results show that this framework is effective in handling dynamic objects and reducing the mapping error.
* Presented at 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO)
Condition-Invariant and Compact Visual Place Description by Convolutional Autoencoder
Apr 15, 2022

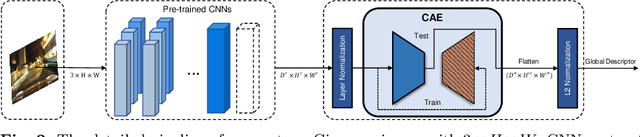
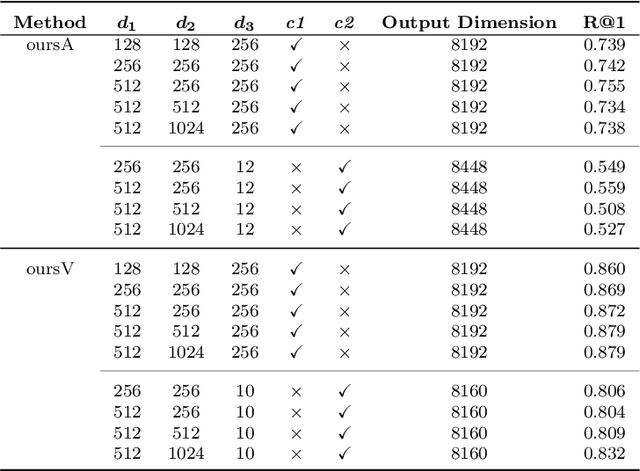
Visual place recognition (VPR) in condition-varying environments is still an open problem. Popular solutions are CNN-based image descriptors, which have been shown to outperform traditional image descriptors based on hand-crafted visual features. However, there are two drawbacks of current CNN-based descriptors: a) their high dimension and b) lack of generalization, leading to low efficiency and poor performance in applications. In this paper, we propose to use a convolutional autoencoder (CAE) to tackle this problem. We employ a high-level layer of a pre-trained CNN to generate features, and train a CAE to map the features to a low-dimensional space to improve the condition invariance property of the descriptor and reduce its dimension at the same time. We verify our method in three challenging datasets involving significant illumination changes, and our method is shown to be superior to the state-of-the-art. For the benefit of the community, we make public the source code.
Hyperparameter Auto-tuning in Self-Supervised Robotic Learning
Oct 19, 2020


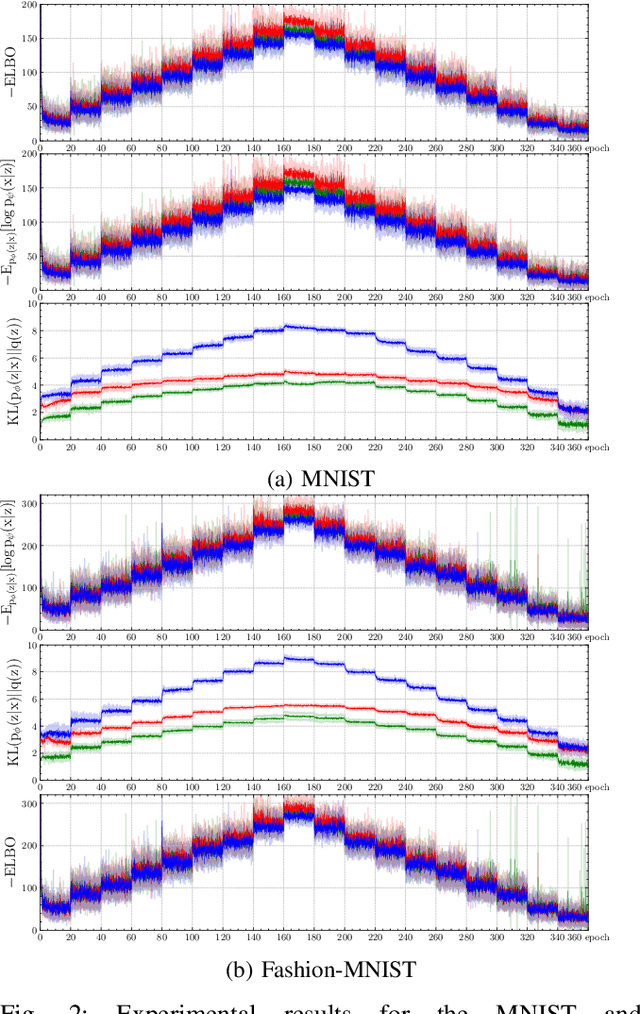
Policy optimization in reinforcement learning requires the selection of numerous hyperparameters across different environments. Fixing them incorrectly may negatively impact optimization performance leading notably to insufficient or redundant learning. Insufficient learning (due to convergence to local optima) results in under-performing policies whilst redundant learning wastes time and resources. The effects are further exacerbated when using single policies to solve multi-task learning problems. In this paper, we study how the Evidence Lower Bound (ELBO) used in Variational Auto-Encoders (VAEs) is affected by the diversity of image samples. Different tasks or setups in visual reinforcement learning incur varying diversity. We exploit the ELBO to create an auto-tuning technique in self-supervised reinforcement learning. Our approach can auto-tune three hyperparameters: the replay buffer size, the number of policy gradient updates during each epoch, and the number of exploration steps during each epoch. We use the state-of-the-art self-supervised robotic learning framework (Reinforcement Learning with Imagined Goals (RIG) using Soft Actor-Critic) as baseline for experimental verification. Experiments show that our method can auto-tune online and yields the best performance at a fraction of the time and computational resources. Code, video, and appendix for simulated and real-robot experiments can be found at http://www.JuanRojas.net/autotune.
Pose-based Modular Network for Human-Object Interaction Detection
Aug 05, 2020
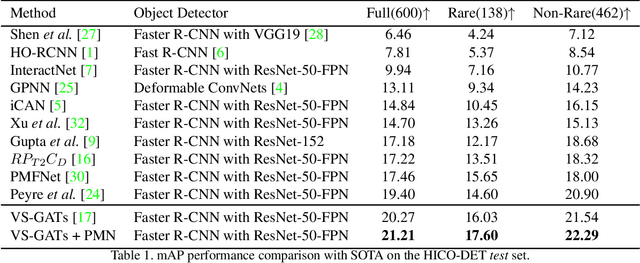
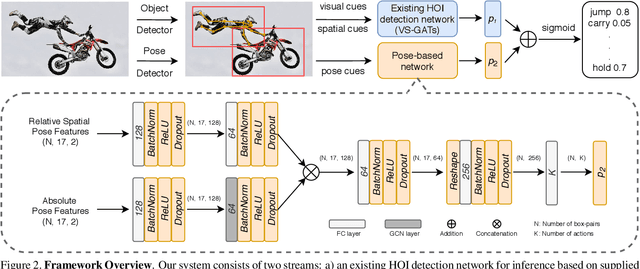
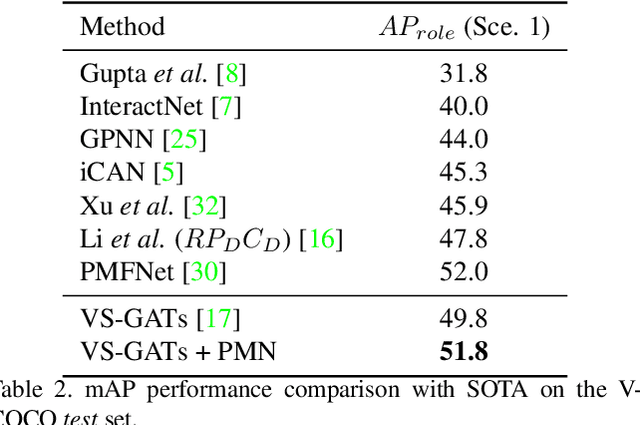
Human-object interaction(HOI) detection is a critical task in scene understanding. The goal is to infer the triplet <subject, predicate, object> in a scene. In this work, we note that the human pose itself as well as the relative spatial information of the human pose with respect to the target object can provide informative cues for HOI detection. We contribute a Pose-based Modular Network (PMN) which explores the absolute pose features and relative spatial pose features to improve HOI detection and is fully compatible with existing networks. Our module consists of a branch that first processes the relative spatial pose features of each joint independently. Another branch updates the absolute pose features via fully connected graph structures. The processed pose features are then fed into an action classifier. To evaluate our proposed method, we combine the module with the state-of-the-art model named VS-GATs and obtain significant improvement on two public benchmarks: V-COCO and HICO-DET, which shows its efficacy and flexibility. Code is available at \url{https://github.com/birlrobotics/PMN}.
Visual-Semantic Graph Attention Network for Human-Object Interaction Detection
Jan 07, 2020
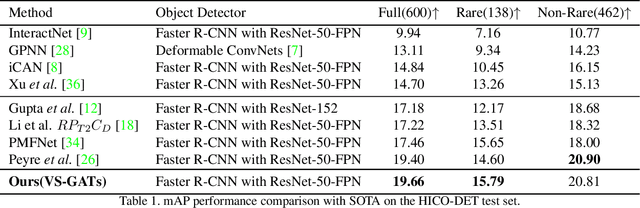
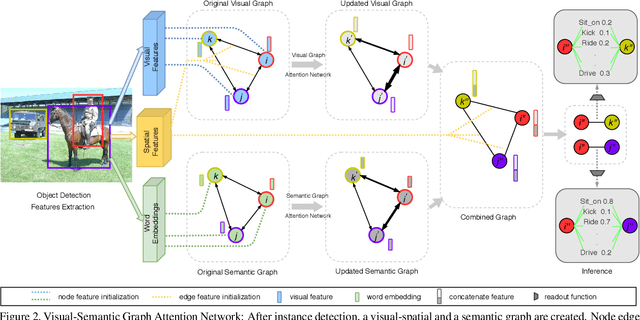
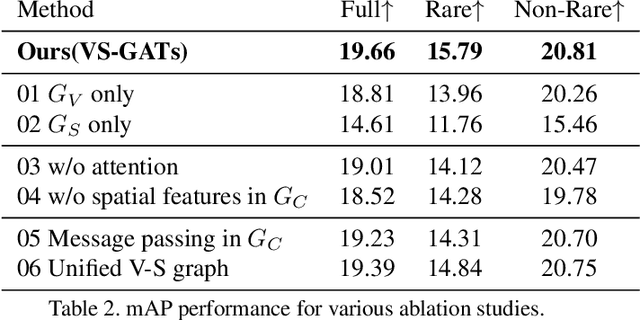
In scene understanding, machines benefit from not only detecting individual scene instances but also from learning their possible interactions. Human-Object Interaction (HOI) Detection tries to infer the predicate on a <subject,predicate,object> triplet. Contextual information has been found critical in inferring interactions. However, most works use features from single object instances that have a direct relation with the subject. Few works have studied the disambiguating contribution of subsidiary relations in addition to how attention might leverage them for inference. We contribute a dual-graph attention network that aggregates contextual visual, spatial, and semantic information dynamically for primary subject-object relations as well as subsidiary relations. Graph attention networks dynamically leverage node neighborhood information. Our network uses attention to first leverage visual-spatial and semantic cues from primary and subsidiary relations independently and then combines them before a final readout step. Our network learns to use primary and subsidiary relations to improve inference: encouraging the right interpretations and discouraging incorrect ones. We call our model: Visual-Semantic Graph Attention Networks (VS-GATs). We surpass state-of-the-art HOI detection mAPs in the challenging HICO-DET dataset, including in long-tail cases that are harder to interpret. Code, video, and supplementary information is available at http://www.juanrojas.net/VSGAT.
Large-scale Multi-modal Person Identification in Real Unconstrained Environments
Dec 17, 2019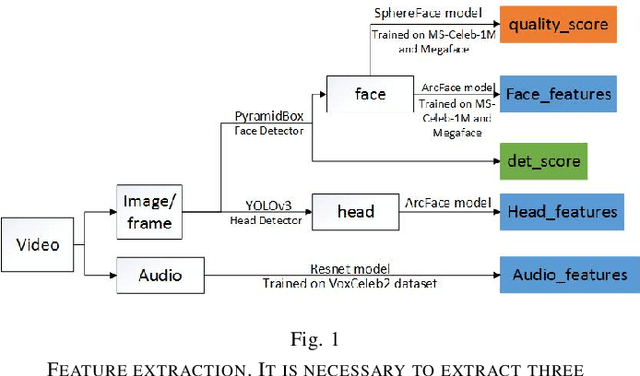
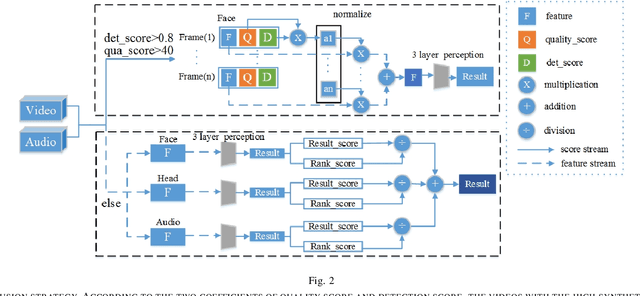

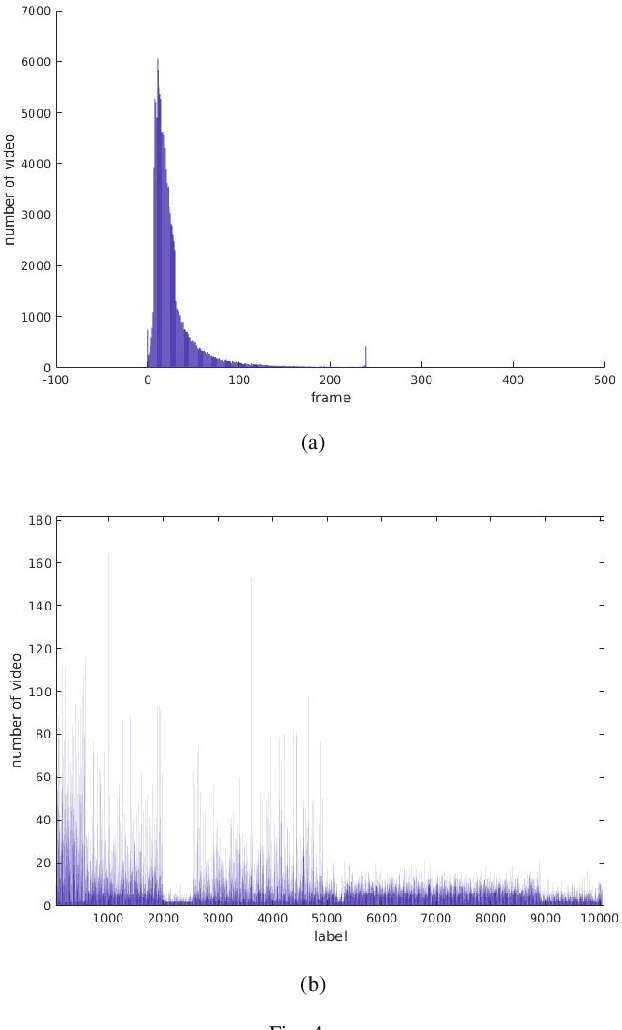
Person identification (P-ID) under real unconstrained noisy environments is a huge challenge. In multiple-feature learning with Deep Convolutional Neural Networks (DCNNs) or Machine Learning method for large-scale person identification in the wild, the key is to design an appropriate strategy for decision layer fusion or feature layer fusion which can enhance discriminative power. It is necessary to extract different types of valid features and establish a reasonable framework to fuse different types of information. In traditional methods, different persons are identified based on single modal features to identify, such as face feature, audio feature, and head feature. These traditional methods cannot realize a highly accurate level of person identification in real unconstrained environments. The study aims to propose a fusion module to fuse multi-modal features for person identification in real unconstrained environments.
Endowing Robots with Longer-term Autonomy by Recovering from External Disturbances in Manipulation through Grounded Anomaly Classification and Recovery Policies
Sep 11, 2018
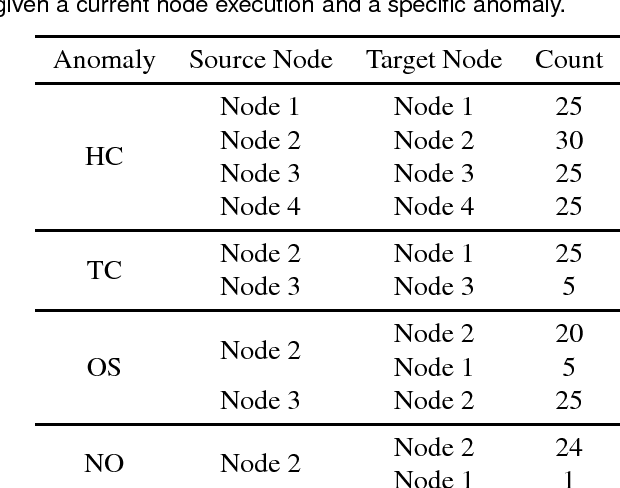
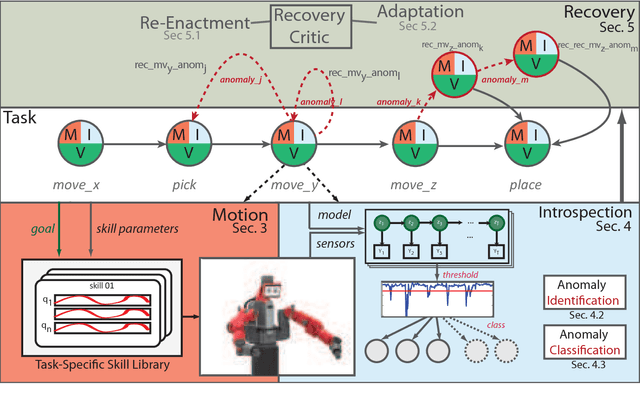

Robot manipulation is increasingly poised to interact with humans in co-shared workspaces. Despite increasingly robust manipulation and control algorithms, failure modes continue to exist whenever models do not capture the dynamics of the unstructured environment. To obtain longer-term horizons in robot automation, robots must develop introspection and recovery abilities. We contribute a set of recovery policies to deal with anomalies produced by external disturbances as well as anomaly classification through the use of non-parametric statistics with memoized variational inference with scalable adaptation. A recovery critic stands atop of a tightly-integrated, graph-based online motion-generation and introspection system that resolves a wide range of anomalous situations. Policies, skills, and introspection models are learned incrementally and contextually in a task. Two task-level recovery policies: re-enactment and adaptation resolve accidental and persistent anomalies respectively. The introspection system uses non-parametric priors along with Markov jump linear systems and memoized variational inference with scalable adaptation to learn a model from the data. Extensive real-robot experimentation with various strenuous anomalous conditions is induced and resolved at different phases of a task and in different combinations. The system executes around-the-clock introspection and recovery and even elicited self-recovery when misclassifications occurred.