 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMP: One-step Meanflow Policy with Directional Alignment
Dec 22, 2025Robot manipulation, a key capability of embodied AI, has turned to data-driven generative policy frameworks, but mainstream approaches like Diffusion Models suffer from high inference latency and Flow-based Methods from increased architectural complexity. While simply applying meanFlow on robotic tasks achieves single-step inference and outperforms FlowPolicy, it lacks few-shot generalization due to fixed temperature hyperparameters in its Dispersive Loss and misaligned predicted-true mean velocities. To solve these issues, this study proposes an improved MeanFlow-based Policies: we introduce a lightweight Cosine Loss to align velocity directions and use the Differential Derivation Equation (DDE) to optimize the Jacobian-Vector Product (JVP) operator. Experiments on Adroit and Meta-World tasks show the proposed method outperforms MP1 and FlowPolicy in average success rate, especially in challenging Meta-World tasks, effectively enhancing few-shot generalization and trajectory accuracy of robot manipulation policies while maintaining real-time performance, offering a more robust solution for high-precision robotic manipulation.
Intervention Efficiency and Perturbation Validation Framework: Capacity-Aware and Robust Clinical Model Selection under the Rashomon Effect
Nov 18, 2025In clinical machine learning, the coexistence of multiple models with comparable performance -- a manifestation of the Rashomon Effect -- poses fundamental challenges for trustworthy deployment and evaluation. Small, imbalanced, and noisy datasets, coupled with high-dimensional and weakly identified clinical features, amplify this multiplicity and make conventional validation schemes unreliable. As a result, selecting among equally performing models becomes uncertain, particularly when resource constraints and operational priorities are not considered by conventional metrics like F1 score. To address these issues, we propose two complementary tools for robust model assessment and selection: Intervention Efficiency (IE) and the Perturbation Validation Framework (PVF). IE is a capacity-aware metric that quantifies how efficiently a model identifies actionable true positives when only limited interventions are feasible, thereby linking predictive performance with clinical utility. PVF introduces a structured approach to assess the stability of models under data perturbations, identifying models whose performance remains most invariant across noisy or shifted validation sets. Empirical results on synthetic and real-world healthcare datasets show that using these tools facilitates the selection of models that generalize more robustly and align with capacity constraints, offering a new direction for tackling the Rashomon Effect in clinical settings.
Time Reversal Symmetry for Efficient Robotic Manipulations in Deep Reinforcement Learning
May 20, 2025Symmetry is pervasive in robotics and has been widely exploited to improve sample efficiency in deep reinforcement learning (DRL). However, existing approaches primarily focus on spatial symmetries, such as reflection, rotation, and translation, while largely neglecting temporal symmetries. To address this gap, we explore time reversal symmetry, a form of temporal symmetry commonly found in robotics tasks such as door opening and closing. We propose Time Reversal symmetry enhanced Deep Reinforcement Learning (TR-DRL), a framework that combines trajectory reversal augmentation and time reversal guided reward shaping to efficiently solve temporally symmetric tasks. Our method generates reversed transitions from fully reversible transitions, identified by a proposed dynamics-consistent filter, to augment the training data. For partially reversible transitions, we apply reward shaping to guide learning, according to successful trajectories from the reversed task. Extensive experiments on the Robosuite and MetaWorld benchmarks demonstrate that TR-DRL is effective in both single-task and multi-task settings, achieving higher sample efficiency and stronger final performance compared to baseline methods.
ASAP: Learning Generalizable Online Bin Packing via Adaptive Selection After Pruning
Jan 29, 2025

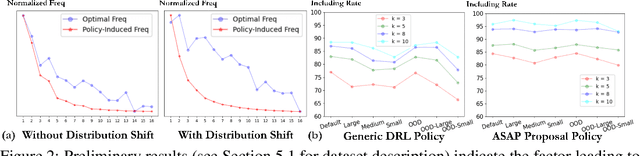

Recently, deep reinforcement learning (DRL) has achieved promising results in solving online 3D Bin Packing Problems (3D-BPP). However, these DRL-based policies may perform poorly on new instances due to distribution shift. Besides generalization, we also consider adaptation, completely overlooked by previous work, which aims at rapidly finetuning these policies to a new test distribution. To tackle both generalization and adaptation issues, we propose Adaptive Selection After Pruning (ASAP), which decomposes a solver's decision-making into two policies, one for pruning and one for selection. The role of the pruning policy is to remove inherently bad actions, which allows the selection policy to choose among the remaining most valuable actions. To learn these policies, we propose a training scheme based on a meta-learning phase of both policies followed by a finetuning phase of the sole selection policy to rapidly adapt it to a test distribution. Our experiments demonstrate that ASAP exhibits excellent generalization and adaptation capabilities on in-distribution and out-of-distribution instances under both discrete and continuous setup.
Enhancing Online Reinforcement Learning with Meta-Learned Objective from Offline Data
Jan 13, 2025A major challenge in Reinforcement Learning (RL) is the difficulty of learning an optimal policy from sparse rewards. Prior works enhance online RL with conventional Imitation Learning (IL) via a handcrafted auxiliary objective, at the cost of restricting the RL policy to be sub-optimal when the offline data is generated by a non-expert policy. Instead, to better leverage valuable information in offline data, we develop Generalized Imitation Learning from Demonstration (GILD), which meta-learns an objective that distills knowledge from offline data and instills intrinsic motivation towards the optimal policy. Distinct from prior works that are exclusive to a specific RL algorithm, GILD is a flexible module intended for diverse vanilla off-policy RL algorithms. In addition, GILD introduces no domain-specific hyperparameter and minimal increase in computational cost. In four challenging MuJoCo tasks with sparse rewards, we show that three RL algorithms enhanced with GILD significantly outperform state-of-the-art methods.
Imitation Learning from Suboptimal Demonstrations via Meta-Learning An Action Ranker
Dec 28, 2024



A major bottleneck in imitation learning is the requirement of a large number of expert demonstrations, which can be expensive or inaccessible. Learning from supplementary demonstrations without strict quality requirements has emerged as a powerful paradigm to address this challenge. However, previous methods often fail to fully utilize their potential by discarding non-expert data. Our key insight is that even demonstrations that fall outside the expert distribution but outperform the learned policy can enhance policy performance. To utilize this potential, we propose a novel approach named imitation learning via meta-learning an action ranker (ILMAR). ILMAR implements weighted behavior cloning (weighted BC) on a limited set of expert demonstrations along with supplementary demonstrations. It utilizes the functional of the advantage function to selectively integrate knowledge from the supplementary demonstrations. To make more effective use of supplementary demonstrations, we introduce meta-goal in ILMAR to optimize the functional of the advantage function by explicitly minimizing the distance between the current policy and the expert policy. Comprehensive experiments using extensive tasks demonstrate that ILMAR significantly outperforms previous methods in handling suboptimal demonstrations. Code is available at https://github.com/F-GOD6/ILMAR.
State-Novelty Guided Action Persistence in Deep Reinforcement Learning
Sep 09, 2024While a powerful and promising approach, deep reinforcement learning (DRL) still suffers from sample inefficiency, which can be notably improved by resorting to more sophisticated techniques to address the exploration-exploitation dilemma. One such technique relies on action persistence (i.e., repeating an action over multiple steps). However, previous work exploiting action persistence either applies a fixed strategy or learns additional value functions (or policy) for selecting the repetition number. In this paper, we propose a novel method to dynamically adjust the action persistence based on the current exploration status of the state space. In such a way, our method does not require training of additional value functions or policy. Moreover, the use of a smooth scheduling of the repeat probability allows a more effective balance between exploration and exploitation. Furthermore, our method can be seamlessly integrated into various basic exploration strategies to incorporate temporal persistence. Finally, extensive experiments on different DMControl tasks demonstrate that our state-novelty guided action persistence method significantly improves the sample efficiency.
Revisiting Data Augmentation in Deep Reinforcement Learning
Feb 19, 2024



Various data augmentation techniques have been recently proposed in image-based deep reinforcement learning (DRL). Although they empirically demonstrate the effectiveness of data augmentation for improving sample efficiency or generalization, which technique should be preferred is not always clear. To tackle this question, we analyze existing methods to better understand them and to uncover how they are connected. Notably, by expressing the variance of the Q-targets and that of the empirical actor/critic losses of these methods, we can analyze the effects of their different components and compare them. We furthermore formulate an explanation about how these methods may be affected by choosing different data augmentation transformations in calculating the target Q-values. This analysis suggests recommendations on how to exploit data augmentation in a more principled way. In addition, we include a regularization term called tangent prop, previously proposed in computer vision, but whose adaptation to DRL is novel to the best of our knowledge. We evaluate our proposition and validate our analysis in several domains. Compared to different relevant baselines, we demonstrate that it achieves state-of-the-art performance in most environments and shows higher sample efficiency and better generalization ability in some complex environments.
INViT: A Generalizable Routing Problem Solver with Invariant Nested View Transformer
Feb 12, 2024Recently, deep reinforcement learning has shown promising results for learning fast heuristics to solve routing problems. Meanwhile, most of the solvers suffer from generalizing to an unseen distribution or distributions with different scales. To address this issue, we propose a novel architecture, called Invariant Nested View Transformer (INViT), which is designed to enforce a nested design together with invariant views inside the encoders to promote the generalizability of the learned solver. It applies a modified policy gradient algorithm enhanced with data augmentations. We demonstrate that the proposed INViT achieves a dominant generalization performance on both TSP and CVRP problems with various distributions and different problem scales.
A Survey of Reinforcement Learning from Human Feedback
Dec 22, 2023Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of Large Language Models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in targeting the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between machine agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.