 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
ViCO: A Training Strategy towards Semantic Aware Dynamic High-Resolution
Oct 14, 2025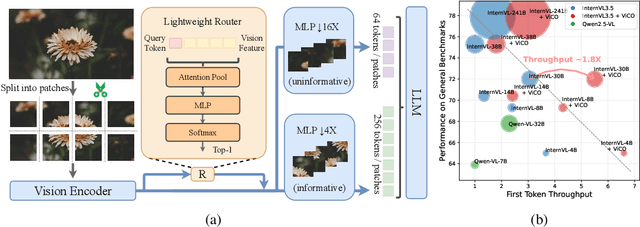
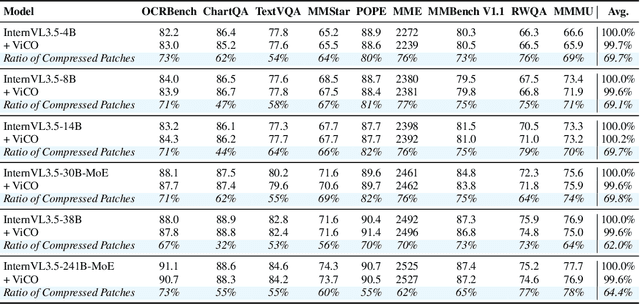
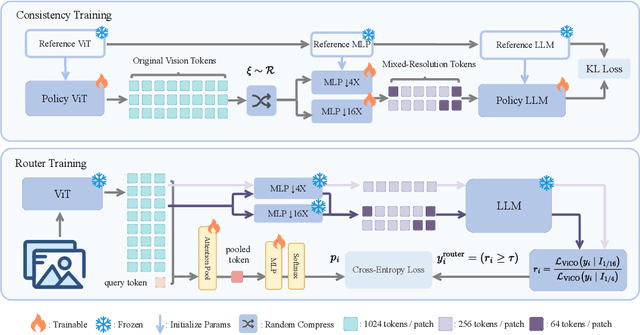
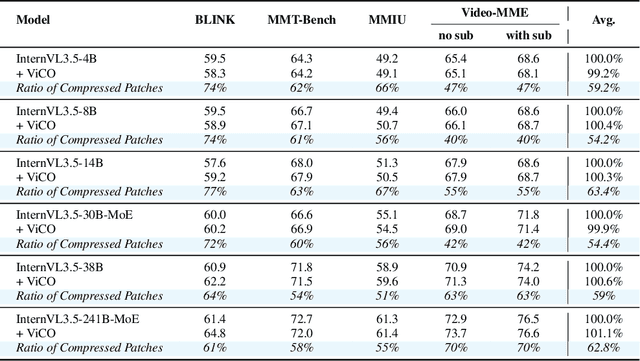
Existing Multimodal Large Language Models (MLLMs) suffer from increased inference costs due to the additional vision tokens introduced by image inputs. In this work, we propose Visual Consistency Learning (ViCO), a novel training algorithm that enables the model to represent images of varying semantic complexities using different numbers of vision tokens. The key idea behind our method is to employ multiple MLP connectors, each with a different image compression ratio, to downsample the vision tokens based on the semantic complexity of the image. During training, we minimize the KL divergence between the responses conditioned on different MLP connectors. At inference time, we introduce an image router, termed Visual Resolution Router (ViR), that automatically selects the appropriate compression rate for each image patch. Compared with existing dynamic high-resolution strategies, which adjust the number of visual tokens based on image resolutions, our method dynamically adapts the number of visual tokens according to semantic complexity. Experimental results demonstrate that our method can reduce the number of vision tokens by up to 50% while maintaining the model's perception, reasoning, and OCR capabilities. We hope this work will contribute to the development of more efficient MLLMs. The code and models will be released to facilitate future research.
Factuality Matters: When Image Generation and Editing Meet Structured Visuals
Oct 06, 2025While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
Enhanced Influence-aware Group Recommendation for Online Media Propagation
Jul 02, 2025Group recommendation over social media streams has attracted significant attention due to its wide applications in domains such as e-commerce, entertainment, and online news broadcasting. By leveraging social connections and group behaviours, group recommendation (GR) aims to provide more accurate and engaging content to a set of users rather than individuals. Recently, influence-aware GR has emerged as a promising direction, as it considers the impact of social influence on group decision-making. In earlier work, we proposed Influence-aware Group Recommendation (IGR) to solve this task. However, this task remains challenging due to three key factors: the large and ever-growing scale of social graphs, the inherently dynamic nature of influence propagation within user groups, and the high computational overhead of real-time group-item matching. To tackle these issues, we propose an Enhanced Influence-aware Group Recommendation (EIGR) framework. First, we introduce a Graph Extraction-based Sampling (GES) strategy to minimise redundancy across multiple temporal social graphs and effectively capture the evolving dynamics of both groups and items. Second, we design a novel DYnamic Independent Cascade (DYIC) model to predict how influence propagates over time across social items and user groups. Finally, we develop a two-level hash-based User Group Index (UG-Index) to efficiently organise user groups and enable real-time recommendation generation. Extensive experiments on real-world datasets demonstrate that our proposed framework, EIGR, consistently outperforms state-of-the-art baselines in both effectiveness and efficiency.
CreatiPoster: Towards Editable and Controllable Multi-Layer Graphic Design Generation
Jun 12, 2025Graphic design plays a crucial role in both commercial and personal contexts, yet creating high-quality, editable, and aesthetically pleasing graphic compositions remains a time-consuming and skill-intensive task, especially for beginners. Current AI tools automate parts of the workflow, but struggle to accurately incorporate user-supplied assets, maintain editability, and achieve professional visual appeal. Commercial systems, like Canva Magic Design, rely on vast template libraries, which are impractical for replicate. In this paper, we introduce CreatiPoster, a framework that generates editable, multi-layer compositions from optional natural-language instructions or assets. A protocol model, an RGBA large multimodal model, first produces a JSON specification detailing every layer (text or asset) with precise layout, hierarchy, content and style, plus a concise background prompt. A conditional background model then synthesizes a coherent background conditioned on this rendered foreground layers. We construct a benchmark with automated metrics for graphic-design generation and show that CreatiPoster surpasses leading open-source approaches and proprietary commercial systems. To catalyze further research, we release a copyright-free corpus of 100,000 multi-layer designs. CreatiPoster supports diverse applications such as canvas editing, text overlay, responsive resizing, multilingual adaptation, and animated posters, advancing the democratization of AI-assisted graphic design. Project homepage: https://github.com/graphic-design-ai/creatiposter
Who Reasons in the Large Language Models?
May 27, 2025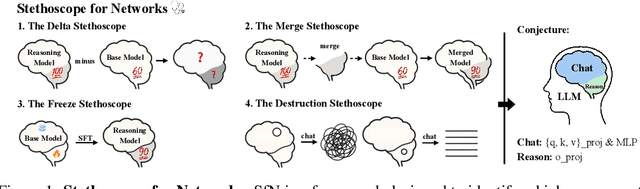

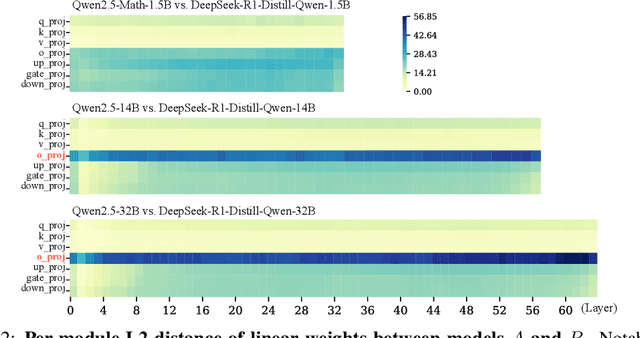

Despite the impressive performance of large language models (LLMs), the process of endowing them with new capabilities--such as mathematical reasoning--remains largely empirical and opaque. A critical open question is whether reasoning abilities stem from the entire model, specific modules, or are merely artifacts of overfitting. In this work, we hypothesize that the reasoning capabilities in well-trained LLMs are primarily attributed to the output projection module (oproj) in the Transformer's multi-head self-attention (MHSA) mechanism. To support this hypothesis, we introduce Stethoscope for Networks (SfN), a suite of diagnostic tools designed to probe and analyze the internal behaviors of LLMs. Using SfN, we provide both circumstantial and empirical evidence suggesting that oproj plays a central role in enabling reasoning, whereas other modules contribute more to fluent dialogue. These findings offer a new perspective on LLM interpretability and open avenues for more targeted training strategies, potentially enabling more efficient and specialized LLMs.
CreatiDesign: A Unified Multi-Conditional Diffusion Transformer for Creative Graphic Design
May 25, 2025Graphic design plays a vital role in visual communication across advertising, marketing, and multimedia entertainment. Prior work has explored automated graphic design generation using diffusion models, aiming to streamline creative workflows and democratize design capabilities. However, complex graphic design scenarios require accurately adhering to design intent specified by multiple heterogeneous user-provided elements (\eg images, layouts, and texts), which pose multi-condition control challenges for existing methods. Specifically, previous single-condition control models demonstrate effectiveness only within their specialized domains but fail to generalize to other conditions, while existing multi-condition methods often lack fine-grained control over each sub-condition and compromise overall compositional harmony. To address these limitations, we introduce CreatiDesign, a systematic solution for automated graphic design covering both model architecture and dataset construction. First, we design a unified multi-condition driven architecture that enables flexible and precise integration of heterogeneous design elements with minimal architectural modifications to the base diffusion model. Furthermore, to ensure that each condition precisely controls its designated image region and to avoid interference between conditions, we propose a multimodal attention mask mechanism. Additionally, we develop a fully automated pipeline for constructing graphic design datasets, and introduce a new dataset with 400K samples featuring multi-condition annotations, along with a comprehensive benchmark. Experimental results show that CreatiDesign outperforms existing models by a clear margin in faithfully adhering to user intent.
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Apr 15, 2025We introduce InternVL3, a significant advancement in the InternVL series featuring a native multimodal pre-training paradigm. Rather than adapting a text-only large language model (LLM) into a multimodal large language model (MLLM) that supports visual inputs, InternVL3 jointly acquires multimodal and linguistic capabilities from both diverse multimodal data and pure-text corpora during a single pre-training stage. This unified training paradigm effectively addresses the complexities and alignment challenges commonly encountered in conventional post-hoc training pipelines for MLLMs. To further improve performance and scalability, InternVL3 incorporates variable visual position encoding (V2PE) to support extended multimodal contexts, employs advanced post-training techniques such as supervised fine-tuning (SFT) and mixed preference optimization (MPO), and adopts test-time scaling strategies alongside an optimized training infrastructure. Extensive empirical evaluations demonstrate that InternVL3 delivers superior performance across a wide range of multi-modal tasks. In particular, InternVL3-78B achieves a score of 72.2 on the MMMU benchmark, setting a new state-of-the-art among open-source MLLMs. Its capabilities remain highly competitive with leading proprietary models, including ChatGPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro, while also maintaining strong pure-language proficiency. In pursuit of open-science principles, we will publicly release both the training data and model weights to foster further research and development in next-generation MLLMs.
BlockDance: Reuse Structurally Similar Spatio-Temporal Features to Accelerate Diffusion Transformers
Mar 20, 2025Diffusion models have demonstrated impressive generation capabilities, particularly with recent advancements leveraging transformer architectures to improve both visual and artistic quality. However, Diffusion Transformers (DiTs) continue to encounter challenges related to low inference speed, primarily due to the iterative denoising process. To address this issue, we propose BlockDance, a training-free approach that explores feature similarities at adjacent time steps to accelerate DiTs. Unlike previous feature-reuse methods that lack tailored reuse strategies for features at different scales, BlockDance prioritizes the identification of the most structurally similar features, referred to as Structurally Similar Spatio-Temporal (STSS) features. These features are primarily located within the structure-focused blocks of the transformer during the later stages of denoising. BlockDance caches and reuses these highly similar features to mitigate redundant computation, thereby accelerating DiTs while maximizing consistency with the generated results of the original model. Furthermore, considering the diversity of generated content and the varying distributions of redundant features, we introduce BlockDance-Ada, a lightweight decision-making network tailored for instance-specific acceleration. BlockDance-Ada dynamically allocates resources and provides superior content quality. Both BlockDance and BlockDance-Ada have proven effective across various generation tasks and models, achieving accelerations between 25% and 50% while maintaining generation quality.