 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreatiPoster: Towards Editable and Controllable Multi-Layer Graphic Design Generation
Jun 12, 2025Graphic design plays a crucial role in both commercial and personal contexts, yet creating high-quality, editable, and aesthetically pleasing graphic compositions remains a time-consuming and skill-intensive task, especially for beginners. Current AI tools automate parts of the workflow, but struggle to accurately incorporate user-supplied assets, maintain editability, and achieve professional visual appeal. Commercial systems, like Canva Magic Design, rely on vast template libraries, which are impractical for replicate. In this paper, we introduce CreatiPoster, a framework that generates editable, multi-layer compositions from optional natural-language instructions or assets. A protocol model, an RGBA large multimodal model, first produces a JSON specification detailing every layer (text or asset) with precise layout, hierarchy, content and style, plus a concise background prompt. A conditional background model then synthesizes a coherent background conditioned on this rendered foreground layers. We construct a benchmark with automated metrics for graphic-design generation and show that CreatiPoster surpasses leading open-source approaches and proprietary commercial systems. To catalyze further research, we release a copyright-free corpus of 100,000 multi-layer designs. CreatiPoster supports diverse applications such as canvas editing, text overlay, responsive resizing, multilingual adaptation, and animated posters, advancing the democratization of AI-assisted graphic design. Project homepage: https://github.com/graphic-design-ai/creatiposter
CreatiDesign: A Unified Multi-Conditional Diffusion Transformer for Creative Graphic Design
May 25, 2025Graphic design plays a vital role in visual communication across advertising, marketing, and multimedia entertainment. Prior work has explored automated graphic design generation using diffusion models, aiming to streamline creative workflows and democratize design capabilities. However, complex graphic design scenarios require accurately adhering to design intent specified by multiple heterogeneous user-provided elements (\eg images, layouts, and texts), which pose multi-condition control challenges for existing methods. Specifically, previous single-condition control models demonstrate effectiveness only within their specialized domains but fail to generalize to other conditions, while existing multi-condition methods often lack fine-grained control over each sub-condition and compromise overall compositional harmony. To address these limitations, we introduce CreatiDesign, a systematic solution for automated graphic design covering both model architecture and dataset construction. First, we design a unified multi-condition driven architecture that enables flexible and precise integration of heterogeneous design elements with minimal architectural modifications to the base diffusion model. Furthermore, to ensure that each condition precisely controls its designated image region and to avoid interference between conditions, we propose a multimodal attention mask mechanism. Additionally, we develop a fully automated pipeline for constructing graphic design datasets, and introduce a new dataset with 400K samples featuring multi-condition annotations, along with a comprehensive benchmark. Experimental results show that CreatiDesign outperforms existing models by a clear margin in faithfully adhering to user intent.
Graphic Design with Large Multimodal Model
Apr 22, 2024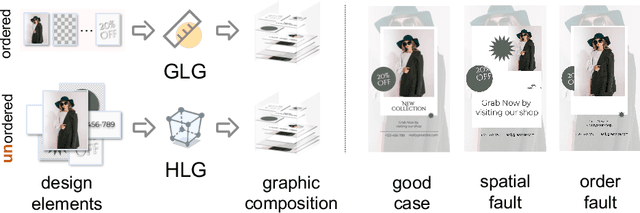
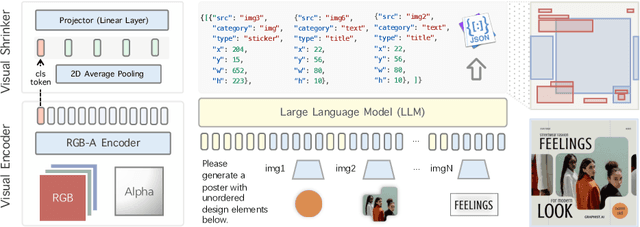
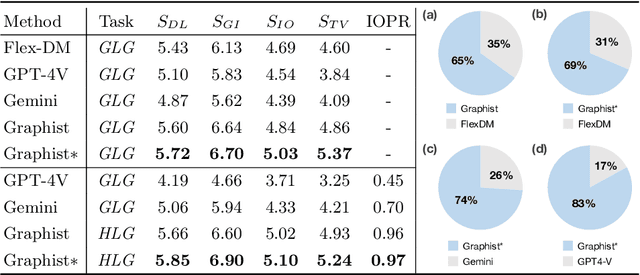
In the field of graphic design, automating the integration of design elements into a cohesive multi-layered artwork not only boosts productivity but also paves the way for the democratization of graphic design. One existing practice is Graphic Layout Generation (GLG), which aims to layout sequential design elements. It has been constrained by the necessity for a predefined correct sequence of layers, thus limiting creative potential and increasing user workload. In this paper, we present Hierarchical Layout Generation (HLG) as a more flexible and pragmatic setup, which creates graphic composition from unordered sets of design elements. To tackle the HLG task, we introduce Graphist, the first layout generation model based on large multimodal models. Graphist efficiently reframes the HLG as a sequence generation problem, utilizing RGB-A images as input, outputs a JSON draft protocol, indicating the coordinates, size, and order of each element. We develop new evaluation metrics for HLG. Graphist outperforms prior arts and establishes a strong baseline for this field. Project homepage: https://github.com/graphic-design-ai/graphist
Semantic Flow for Fast and Accurate Scene Parsing
Feb 24, 2020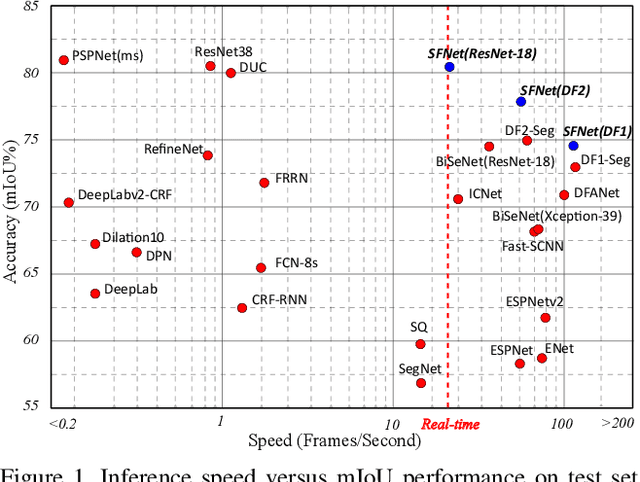
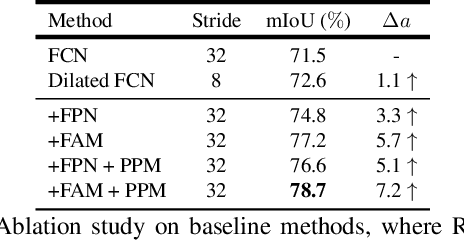
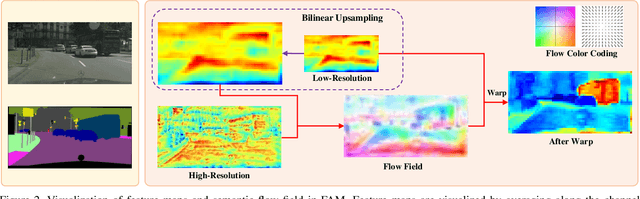
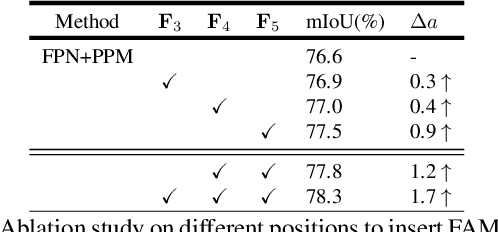
In this paper, we focus on effective methods for fast and accurate scene parsing. A common practice to improve the performance is to attain high resolution feature maps with strong semantic representation. Two strategies are widely used---astrous convolutions and feature pyramid fusion, are either computation intensive or ineffective. Inspired by Optical Flow for motion alignment between adjacent video frames, we propose a Flow Alignment Module (FAM) to learn Semantic Flow between feature maps of adjacent levels and broadcast high-level features to high resolution features effectively and efficiently. Furthermore, integrating our module to a common feature pyramid structure exhibits superior performance over other real-time methods even on very light-weight backbone networks, such as ResNet-18. Extensive experiments are conducted on several challenging datasets, including Cityscapes, PASCAL Context, ADE20K and CamVid. Particularly, our network is the first to achieve 80.4\% mIoU on Cityscapes with a frame rate of 26 FPS. The code will be available at \url{https://github.com/donnyyou/torchcv}.
Global Aggregation then Local Distribution in Fully Convolutional Networks
Sep 16, 2019
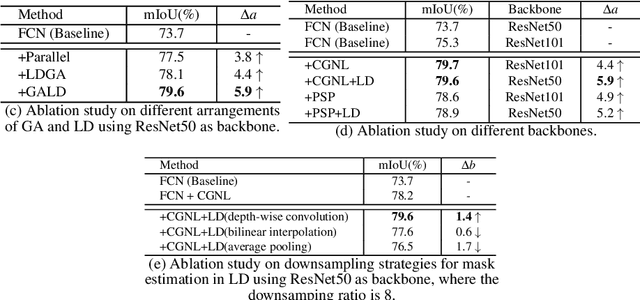
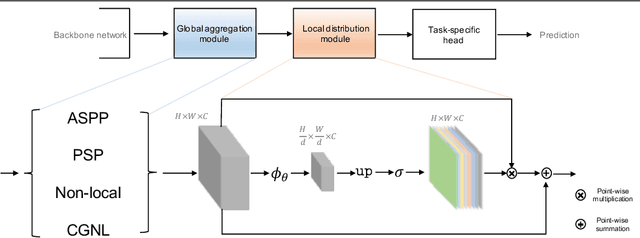

It has been widely proven that modelling long-range dependencies in fully convolutional networks (FCNs) via global aggregation modules is critical for complex scene understanding tasks such as semantic segmentation and object detection. However, global aggregation is often dominated by features of large patterns and tends to oversmooth regions that contain small patterns (e.g., boundaries and small objects). To resolve this problem, we propose to first use \emph{Global Aggregation} and then \emph{Local Distribution}, which is called GALD, where long-range dependencies are more confidently used inside large pattern regions and vice versa. The size of each pattern at each position is estimated in the network as a per-channel mask map. GALD is end-to-end trainable and can be easily plugged into existing FCNs with various global aggregation modules for a wide range of vision tasks, and consistently improves the performance of state-of-the-art object detection and instance segmentation approaches. In particular, GALD used in semantic segmentation achieves new state-of-the-art performance on Cityscapes test set with mIoU 83.3\%. Code is available at: \url{https://github.com/lxtGH/GALD-Net}