 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecTok: Reconstruction Distillation along Rectified Flow
Dec 17, 2025Visual tokenizers play a crucial role in diffusion models. The dimensionality of latent space governs both reconstruction fidelity and the semantic expressiveness of the latent feature. However, a fundamental trade-off is inherent between dimensionality and generation quality, constraining existing methods to low-dimensional latent spaces. Although recent works have leveraged vision foundation models to enrich the semantics of visual tokenizers and accelerate convergence, high-dimensional tokenizers still underperform their low-dimensional counterparts. In this work, we propose RecTok, which overcomes the limitations of high-dimensional visual tokenizers through two key innovations: flow semantic distillation and reconstruction--alignment distillation. Our key insight is to make the forward flow in flow matching semantically rich, which serves as the training space of diffusion transformers, rather than focusing on the latent space as in previous works. Specifically, our method distills the semantic information in VFMs into the forward flow trajectories in flow matching. And we further enhance the semantics by introducing a masked feature reconstruction loss. Our RecTok achieves superior image reconstruction, generation quality, and discriminative performance. It achieves state-of-the-art results on the gFID-50K under both with and without classifier-free guidance settings, while maintaining a semantically rich latent space structure. Furthermore, as the latent dimensionality increases, we observe consistent improvements. Code and model are available at https://shi-qingyu.github.io/rectok.github.io.
MMaDA-Parallel: Multimodal Large Diffusion Language Models for Thinking-Aware Editing and Generation
Nov 18, 2025While thinking-aware generation aims to improve performance on complex tasks, we identify a critical failure mode where existing sequential, autoregressive approaches can paradoxically degrade performance due to error propagation. To systematically analyze this issue, we propose ParaBench, a new benchmark designed to evaluate both text and image output modalities. Our analysis using ParaBench reveals that this performance degradation is strongly correlated with poor alignment between the generated reasoning and the final image. To resolve this, we propose a parallel multimodal diffusion framework, MMaDA-Parallel, that enables continuous, bidirectional interaction between text and images throughout the entire denoising trajectory. MMaDA-Parallel is trained with supervised finetuning and then further optimized by Parallel Reinforcement Learning (ParaRL), a novel strategy that applies semantic rewards along the trajectory to enforce cross-modal consistency. Experiments validate that our model significantly improves cross-modal alignment and semantic consistency, achieving a 6.9\% improvement in Output Alignment on ParaBench compared to the state-of-the-art model, Bagel, establishing a more robust paradigm for thinking-aware image synthesis. Our code is open-sourced at https://github.com/tyfeld/MMaDA-Parallel
Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence
Oct 23, 2025Most video reasoning models only generate textual reasoning traces without indicating when and where key evidence appears. Recent models such as OpenAI-o3 have sparked wide interest in evidence-centered reasoning for images, yet extending this ability to videos is more challenging, as it requires joint temporal tracking and spatial localization across dynamic scenes. We introduce Open-o3 Video, a non-agent framework that integrates explicit spatio-temporal evidence into video reasoning, and carefully collect training data and design training strategies to address the aforementioned challenges. The model highlights key timestamps, objects, and bounding boxes alongside its answers, allowing reasoning to be grounded in concrete visual observations. To enable this functionality, we first curate and build two high-quality datasets, STGR-CoT-30k for SFT and STGR-RL-36k for RL, with carefully constructed temporal and spatial annotations, since most existing datasets offer either temporal spans for videos or spatial boxes on images, lacking unified spatio-temporal supervision and reasoning traces. Then, we adopt a cold-start reinforcement learning strategy with multiple specially designed rewards that jointly encourage answer accuracy, temporal alignment, and spatial precision. On V-STAR benchmark, Open-o3 Video achieves state-of-the-art performance, raising mAM by 14.4% and mLGM by 24.2% on the Qwen2.5-VL baseline. Consistent improvements are also observed on a broad range of video understanding benchmarks, including VideoMME, WorldSense, VideoMMMU, and TVGBench. Beyond accuracy, the reasoning traces produced by Open-o3 Video also provide valuable signals for test-time scaling, enabling confidence-aware verification and improving answer reliability.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
CyberV: Cybernetics for Test-time Scaling in Video Understanding
Jun 09, 2025



Current Multimodal Large Language Models (MLLMs) may struggle with understanding long or complex videos due to computational demands at test time, lack of robustness, and limited accuracy, primarily stemming from their feed-forward processing nature. These limitations could be more severe for models with fewer parameters. To address these limitations, we propose a novel framework inspired by cybernetic principles, redesigning video MLLMs as adaptive systems capable of self-monitoring, self-correction, and dynamic resource allocation during inference. Our approach, CyberV, introduces a cybernetic loop consisting of an MLLM Inference System, a Sensor, and a Controller. Specifically, the sensor monitors forward processes of the MLLM and collects intermediate interpretations, such as attention drift, then the controller determines when and how to trigger self-correction and generate feedback to guide the next round. This test-time adaptive scaling framework enhances frozen MLLMs without requiring retraining or additional components. Experiments demonstrate significant improvements: CyberV boosts Qwen2.5-VL-7B by 8.3% and InternVL3-8B by 5.5% on VideoMMMU, surpassing the competitive proprietary model GPT-4o. When applied to Qwen2.5-VL-72B, it yields a 10.0% improvement, achieving performance even comparable to human experts. Furthermore, our method demonstrates consistent gains on general-purpose benchmarks, such as VideoMME and WorldSense, highlighting its effectiveness and generalization capabilities in making MLLMs more robust and accurate for dynamic video understanding. The code is released at https://github.com/marinero4972/CyberV.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025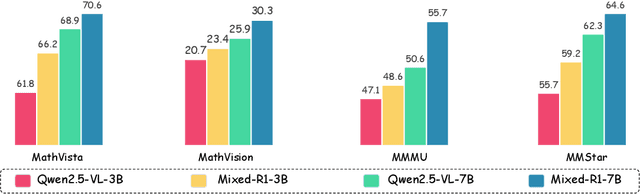
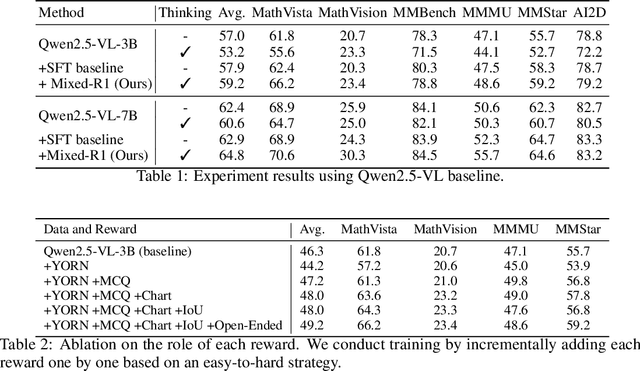
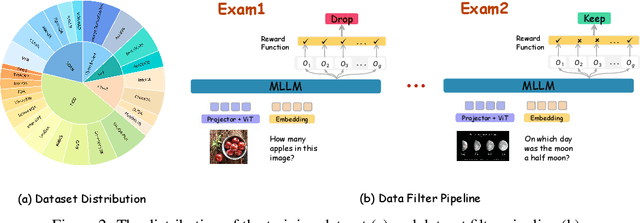

Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.
Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model
May 29, 2025Unified generation models aim to handle diverse tasks across modalities -- such as text generation, image generation, and vision-language reasoning -- within a single architecture and decoding paradigm. Autoregressive unified models suffer from slow inference due to sequential decoding, and non-autoregressive unified models suffer from weak generalization due to limited pretrained backbones. We introduce Muddit, a unified discrete diffusion transformer that enables fast and parallel generation across both text and image modalities. Unlike prior unified diffusion models trained from scratch, Muddit integrates strong visual priors from a pretrained text-to-image backbone with a lightweight text decoder, enabling flexible and high-quality multimodal generation under a unified architecture. Empirical results show that Muddit achieves competitive or superior performance compared to significantly larger autoregressive models in both quality and efficiency. The work highlights the potential of purely discrete diffusion, when equipped with strong visual priors, as a scalable and effective backbone for unified generation.
Conditional Panoramic Image Generation via Masked Autoregressive Modeling
May 22, 2025
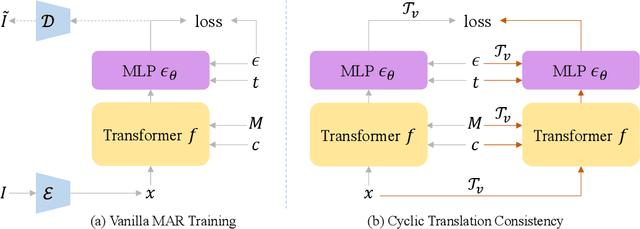
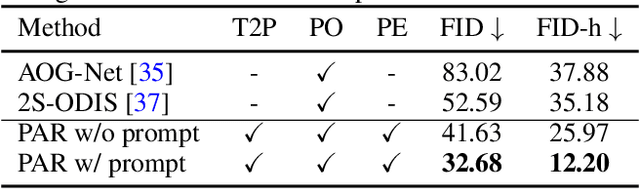

Recent progress in panoramic image generation has underscored two critical limitations in existing approaches. First, most methods are built upon diffusion models, which are inherently ill-suited for equirectangular projection (ERP) panoramas due to the violation of the identically and independently distributed (i.i.d.) Gaussian noise assumption caused by their spherical mapping. Second, these methods often treat text-conditioned generation (text-to-panorama) and image-conditioned generation (panorama outpainting) as separate tasks, relying on distinct architectures and task-specific data. In this work, we propose a unified framework, Panoramic AutoRegressive model (PAR), which leverages masked autoregressive modeling to address these challenges. PAR avoids the i.i.d. assumption constraint and integrates text and image conditioning into a cohesive architecture, enabling seamless generation across tasks. To address the inherent discontinuity in existing generative models, we introduce circular padding to enhance spatial coherence and propose a consistency alignment strategy to improve generation quality. Extensive experiments demonstrate competitive performance in text-to-image generation and panorama outpainting tasks while showcasing promising scalability and generalization capabilities.
MMaDA: Multimodal Large Diffusion Language Models
May 21, 2025We introduce MMaDA, a novel class of multimodal diffusion foundation models designed to achieve superior performance across diverse domains such as textual reasoning, multimodal understanding, and text-to-image generation. The approach is distinguished by three key innovations: (i) MMaDA adopts a unified diffusion architecture with a shared probabilistic formulation and a modality-agnostic design, eliminating the need for modality-specific components. This architecture ensures seamless integration and processing across different data types. (ii) We implement a mixed long chain-of-thought (CoT) fine-tuning strategy that curates a unified CoT format across modalities. By aligning reasoning processes between textual and visual domains, this strategy facilitates cold-start training for the final reinforcement learning (RL) stage, thereby enhancing the model's ability to handle complex tasks from the outset. (iii) We propose UniGRPO, a unified policy-gradient-based RL algorithm specifically tailored for diffusion foundation models. Utilizing diversified reward modeling, UniGRPO unifies post-training across both reasoning and generation tasks, ensuring consistent performance improvements. Experimental results demonstrate that MMaDA-8B exhibits strong generalization capabilities as a unified multimodal foundation model. It surpasses powerful models like LLaMA-3-7B and Qwen2-7B in textual reasoning, outperforms Show-o and SEED-X in multimodal understanding, and excels over SDXL and Janus in text-to-image generation. These achievements highlight MMaDA's effectiveness in bridging the gap between pretraining and post-training within unified diffusion architectures, providing a comprehensive framework for future research and development. We open-source our code and trained models at: https://github.com/Gen-Verse/MMaDA
Generative Classifier for Domain Generalization
Apr 03, 2025Domain generalization (DG) aims to improve the generalizability of computer vision models toward distribution shifts. The mainstream DG methods focus on learning domain invariance, however, such methods overlook the potential inherent in domain-specific information. While the prevailing practice of discriminative linear classifier has been tailored to domain-invariant features, it struggles when confronted with diverse domain-specific information, e.g., intra-class shifts, that exhibits multi-modality. To address these issues, we explore the theoretical implications of relying on domain invariance, revealing the crucial role of domain-specific information in mitigating the target risk for DG. Drawing from these insights, we propose Generative Classifier-driven Domain Generalization (GCDG), introducing a generative paradigm for the DG classifier based on Gaussian Mixture Models (GMMs) for each class across domains. GCDG consists of three key modules: Heterogeneity Learning Classifier~(HLC), Spurious Correlation Blocking~(SCB), and Diverse Component Balancing~(DCB). Concretely, HLC attempts to model the feature distributions and thereby capture valuable domain-specific information via GMMs. SCB identifies the neural units containing spurious correlations and perturbs them, mitigating the risk of HLC learning spurious patterns. Meanwhile, DCB ensures a balanced contribution of components in HLC, preventing the underestimation or neglect of critical components. In this way, GCDG excels in capturing the nuances of domain-specific information characterized by diverse distributions. GCDG demonstrates the potential to reduce the target risk and encourage flat minima, improving the generalizability. Extensive experiments show GCDG's comparable performance on five DG benchmarks and one face anti-spoofing dataset, seamlessly integrating into existing DG methods with consistent improvements.