 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMTok: Representing Any Mask with Two Words
Jan 22, 2026Pixel-wise capabilities are essential for building interactive intelligent systems. However, pixel-wise multi-modal LLMs (MLLMs) remain difficult to scale due to complex region-level encoders, specialized segmentation decoders, and incompatible training objectives. To address these challenges, we present SAMTok, a discrete mask tokenizer that converts any region mask into two special tokens and reconstructs the mask using these tokens with high fidelity. By treating masks as new language tokens, SAMTok enables base MLLMs (such as the QwenVL series) to learn pixel-wise capabilities through standard next-token prediction and simple reinforcement learning, without architectural modifications and specialized loss design. SAMTok builds on SAM2 and is trained on 209M diverse masks using a mask encoder and residual vector quantizer to produce discrete, compact, and information-rich tokens. With 5M SAMTok-formatted mask understanding and generation data samples, QwenVL-SAMTok attains state-of-the-art or comparable results on region captioning, region VQA, grounded conversation, referring segmentation, scene graph parsing, and multi-round interactive segmentation. We further introduce a textual answer-matching reward that enables efficient reinforcement learning for mask generation, delivering substantial improvements on GRES and GCG benchmarks. Our results demonstrate a scalable and straightforward paradigm for equipping MLLMs with strong pixel-wise capabilities. Our code and models are available.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025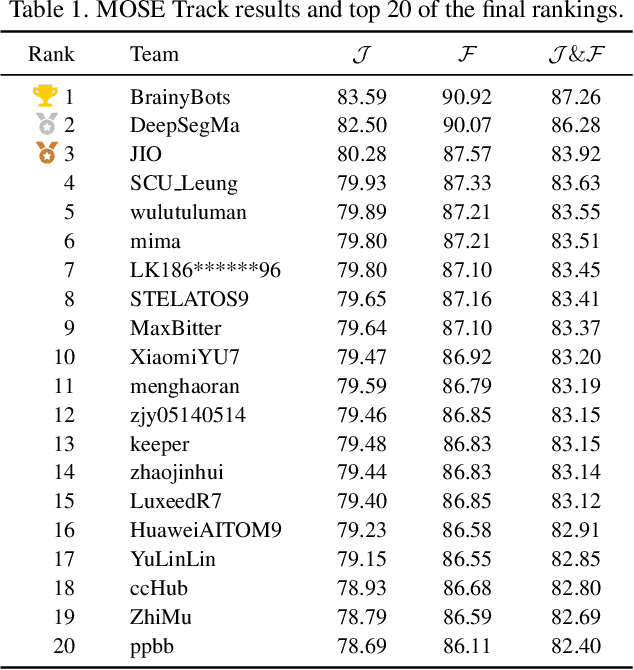
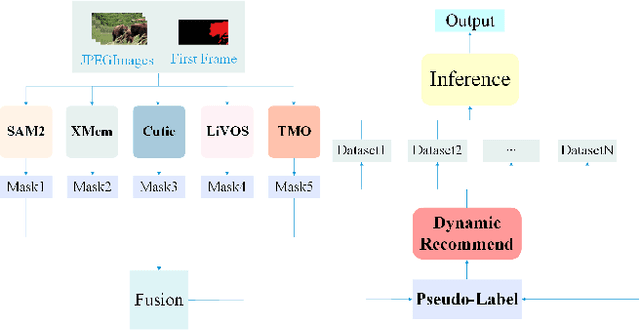
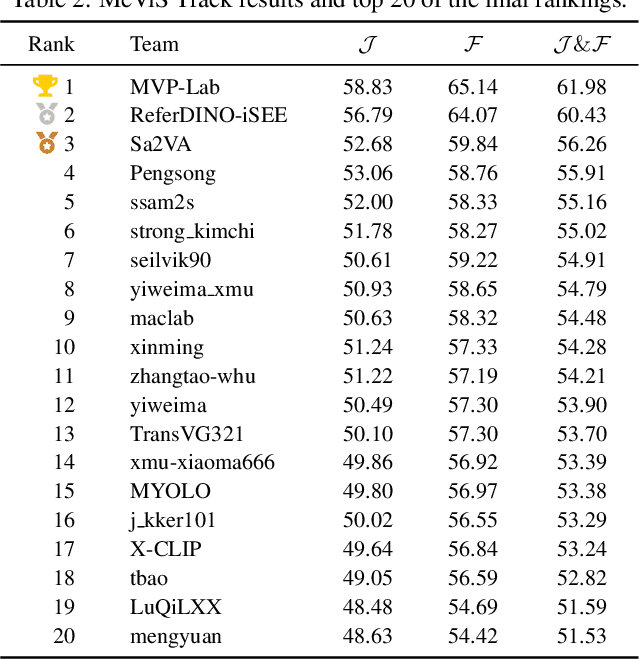
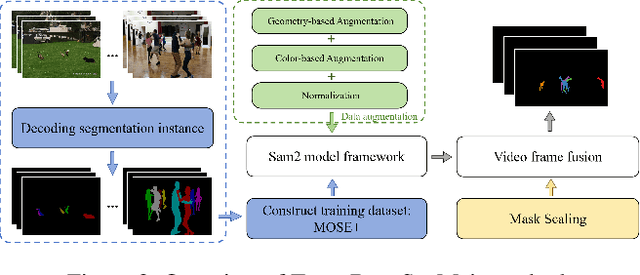
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
4th PVUW MeViS 3rd Place Report: Sa2VA
Apr 01, 2025Referring video object segmentation (RVOS) is a challenging task that requires the model to segment the object in a video given the language description. MeViS is a recently proposed dataset that contains motion expressions of the target objects, leading to a challenging benchmark, compared with existing RVOS benchmarks. On the other hand, for referring expression tasks, a new trend is to adopt multi-modal large language model (MLLM) to achieve better image and text alignment. In this report, we show that with a simple modification to the test time inference method on stronger MLLMs, we can lead to stronger results on MeVIS. In particular, we adopt the recent method Sa2VA, a unified model for dense grounded understanding of both images and videos. By enlarging the scope of key frames, without any further training, we can achieve the 3rd place in the 4th PVUW workshop.
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Jan 07, 2025



This work presents Sa2VA, the first unified model for dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning. Sa2VA combines SAM-2, a foundation video segmentation model, with LLaVA, an advanced vision-language model, and unifies text, image, and video into a shared LLM token space. Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content. Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance. We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves state-of-the-art across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications.
LLAVADI: What Matters For Multimodal Large Language Models Distillation
Jul 28, 2024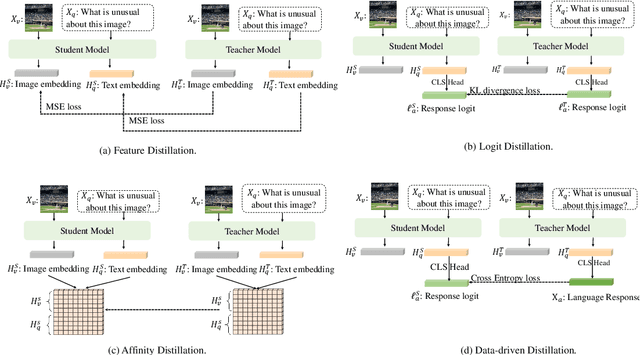



The recent surge in Multimodal Large Language Models (MLLMs) has showcased their remarkable potential for achieving generalized intelligence by integrating visual understanding into Large Language Models.Nevertheless, the sheer model size of MLLMs leads to substantial memory and computational demands that hinder their widespread deployment. In this work, we do not propose a new efficient model structure or train small-scale MLLMs from scratch. Instead, we focus on what matters for training small-scale MLLMs through knowledge distillation, which is the first step from the multimodal distillation perspective. Our extensive studies involve training strategies, model choices, and distillation algorithms in the knowledge distillation process. These results show that joint alignment for both tokens and logit alignment plays critical roles in teacher-student frameworks. In addition, we draw a series of intriguing observations from this study. By evaluating different benchmarks and proper strategy, even a 2.7B small-scale model can perform on par with larger models with 7B or 13B parameters. Our code and models will be publicly available for further research.
OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding
Jun 27, 2024



Current universal segmentation methods demonstrate strong capabilities in pixel-level image and video understanding. However, they lack reasoning abilities and cannot be controlled via text instructions. In contrast, large vision-language multimodal models exhibit powerful vision-based conversation and reasoning capabilities but lack pixel-level understanding and have difficulty accepting visual prompts for flexible user interaction. This paper proposes OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Specifically, we use a universal segmentation method as the visual encoder, integrating image information, perception priors, and visual prompts into visual tokens provided to the LLM. The LLM is responsible for understanding the user's text instructions and providing text responses and pixel-level segmentation results based on the visual information. We propose perception prior embedding to better integrate perception priors with image features. OMG-LLaVA achieves image-level, object-level, and pixel-level reasoning and understanding in a single model, matching or surpassing the performance of specialized methods on multiple benchmarks. Rather than using LLM to connect each specialist, our work aims at end-to-end training on one encoder, one decoder, and one LLM. The code and model have been released for further research.
Mamba or RWKV: Exploring High-Quality and High-Efficiency Segment Anything Model
Jun 27, 2024Transformer-based segmentation methods face the challenge of efficient inference when dealing with high-resolution images. Recently, several linear attention architectures, such as Mamba and RWKV, have attracted much attention as they can process long sequences efficiently. In this work, we focus on designing an efficient segment-anything model by exploring these different architectures. Specifically, we design a mixed backbone that contains convolution and RWKV operation, which achieves the best for both accuracy and efficiency. In addition, we design an efficient decoder to utilize the multiscale tokens to obtain high-quality masks. We denote our method as RWKV-SAM, a simple, effective, fast baseline for SAM-like models. Moreover, we build a benchmark containing various high-quality segmentation datasets and jointly train one efficient yet high-quality segmentation model using this benchmark. Based on the benchmark results, our RWKV-SAM achieves outstanding performance in efficiency and segmentation quality compared to transformers and other linear attention models. For example, compared with the same-scale transformer model, RWKV-SAM achieves more than 2x speedup and can achieve better segmentation performance on various datasets. In addition, RWKV-SAM outperforms recent vision Mamba models with better classification and semantic segmentation results. Code and models will be publicly available.
Point Could Mamba: Point Cloud Learning via State Space Model
Mar 01, 2024



In this work, for the first time, we demonstrate that Mamba-based point cloud methods can outperform point-based methods. Mamba exhibits strong global modeling capabilities and linear computational complexity, making it highly attractive for point cloud analysis. To enable more effective processing of 3-D point cloud data by Mamba, we propose a novel Consistent Traverse Serialization to convert point clouds into 1-D point sequences while ensuring that neighboring points in the sequence are also spatially adjacent. Consistent Traverse Serialization yields six variants by permuting the order of x, y, and z coordinates, and the synergistic use of these variants aids Mamba in comprehensively observing point cloud data. Furthermore, to assist Mamba in handling point sequences with different orders more effectively, we introduce point prompts to inform Mamba of the sequence's arrangement rules. Finally, we propose positional encoding based on spatial coordinate mapping to inject positional information into point cloud sequences better. Based on these improvements, we construct a point cloud network named Point Cloud Mamba, which combines local and global modeling. Point Cloud Mamba surpasses the SOTA point-based method PointNeXt and achieves new SOTA performance on the ScanObjectNN, ModelNet40, and ShapeNetPart datasets.