 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLAVADI: What Matters For Multimodal Large Language Models Distillation
Paper and Code
Jul 28, 2024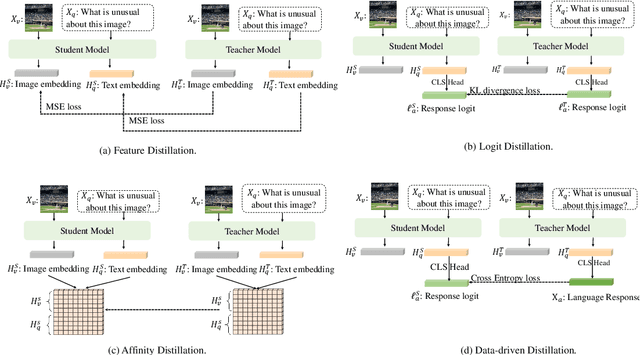



The recent surge in Multimodal Large Language Models (MLLMs) has showcased their remarkable potential for achieving generalized intelligence by integrating visual understanding into Large Language Models.Nevertheless, the sheer model size of MLLMs leads to substantial memory and computational demands that hinder their widespread deployment. In this work, we do not propose a new efficient model structure or train small-scale MLLMs from scratch. Instead, we focus on what matters for training small-scale MLLMs through knowledge distillation, which is the first step from the multimodal distillation perspective. Our extensive studies involve training strategies, model choices, and distillation algorithms in the knowledge distillation process. These results show that joint alignment for both tokens and logit alignment plays critical roles in teacher-student frameworks. In addition, we draw a series of intriguing observations from this study. By evaluating different benchmarks and proper strategy, even a 2.7B small-scale model can perform on par with larger models with 7B or 13B parameters. Our code and models will be publicly available for further research.