 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Generative Transformer Is What You Need for Image Editing
May 11, 2026Diffusion models dominate image editing, yet their global denoising mechanism entangles edited regions with surrounding context, causing modifications to propagate into areas that should remain intact. We propose a fundamentally different approach by leveraging Masked Generative Transformers (MGTs), whose localized token-prediction paradigm naturally confines changes to intended regions. We present EditMGT, an MGT-based editing framework that is the first of its kind. Our approach employs multi-layer attention consolidation to aggregate cross-attention maps into precise edit localization signals, and region-hold sampling to explicitly prevent token flipping in non-target areas. To support training, we construct CrispEdit-2M, a 2M-sample high-resolution (>1024) editing dataset spanning seven categories. With only 960M parameters, EditMGT achieves state-of-the-art image similarity on multiple benchmarks while delivering 6x faster editing, demonstrating that MGTs offer a compelling alternative to diffusion-based editing.
Neighbor-aware Instance Refining with Noisy Labels for Cross-Modal Retrieval
Dec 30, 2025In recent years, Cross-Modal Retrieval (CMR) has made significant progress in the field of multi-modal analysis. However, since it is time-consuming and labor-intensive to collect large-scale and well-annotated data, the annotation of multi-modal data inevitably contains some noise. This will degrade the retrieval performance of the model. To tackle the problem, numerous robust CMR methods have been developed, including robust learning paradigms, label calibration strategies, and instance selection mechanisms. Unfortunately, they often fail to simultaneously satisfy model performance ceilings, calibration reliability, and data utilization rate. To overcome the limitations, we propose a novel robust cross-modal learning framework, namely Neighbor-aware Instance Refining with Noisy Labels (NIRNL). Specifically, we first propose Cross-modal Margin Preserving (CMP) to adjust the relative distance between positive and negative pairs, thereby enhancing the discrimination between sample pairs. Then, we propose Neighbor-aware Instance Refining (NIR) to identify pure subset, hard subset, and noisy subset through cross-modal neighborhood consensus. Afterward, we construct different tailored optimization strategies for this fine-grained partitioning, thereby maximizing the utilization of all available data while mitigating error propagation. Extensive experiments on three benchmark datasets demonstrate that NIRNL achieves state-of-the-art performance, exhibiting remarkable robustness, especially under high noise rates.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025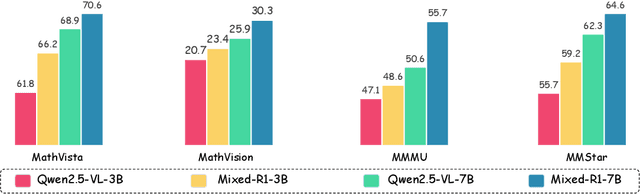
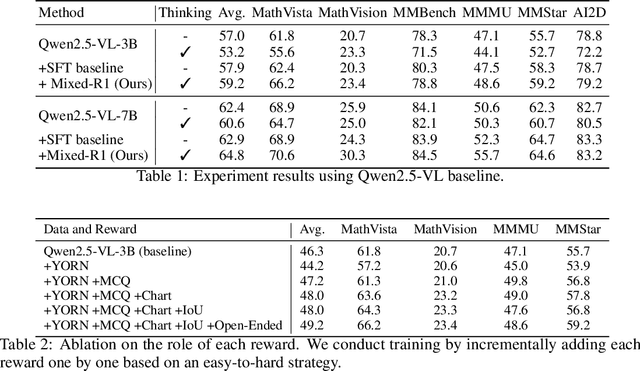
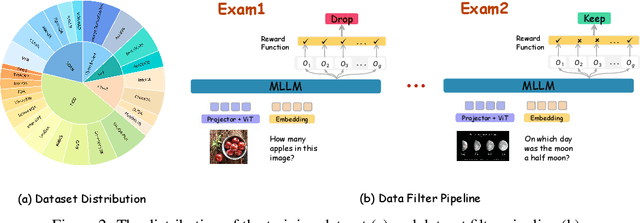

Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.
On Path to Multimodal Generalist: General-Level and General-Bench
May 07, 2025The Multimodal Large Language Model (MLLM) is currently experiencing rapid growth, driven by the advanced capabilities of LLMs. Unlike earlier specialists, existing MLLMs are evolving towards a Multimodal Generalist paradigm. Initially limited to understanding multiple modalities, these models have advanced to not only comprehend but also generate across modalities. Their capabilities have expanded from coarse-grained to fine-grained multimodal understanding and from supporting limited modalities to arbitrary ones. While many benchmarks exist to assess MLLMs, a critical question arises: Can we simply assume that higher performance across tasks indicates a stronger MLLM capability, bringing us closer to human-level AI? We argue that the answer is not as straightforward as it seems. This project introduces General-Level, an evaluation framework that defines 5-scale levels of MLLM performance and generality, offering a methodology to compare MLLMs and gauge the progress of existing systems towards more robust multimodal generalists and, ultimately, towards AGI. At the core of the framework is the concept of Synergy, which measures whether models maintain consistent capabilities across comprehension and generation, and across multiple modalities. To support this evaluation, we present General-Bench, which encompasses a broader spectrum of skills, modalities, formats, and capabilities, including over 700 tasks and 325,800 instances. The evaluation results that involve over 100 existing state-of-the-art MLLMs uncover the capability rankings of generalists, highlighting the challenges in reaching genuine AI. We expect this project to pave the way for future research on next-generation multimodal foundation models, providing a robust infrastructure to accelerate the realization of AGI. Project page: https://generalist.top/
An Empirical Study of GPT-4o Image Generation Capabilities
Apr 08, 2025



The landscape of image generation has rapidly evolved, from early GAN-based approaches to diffusion models and, most recently, to unified generative architectures that seek to bridge understanding and generation tasks. Recent advances, especially the GPT-4o, have demonstrated the feasibility of high-fidelity multimodal generation, their architectural design remains mysterious and unpublished. This prompts the question of whether image and text generation have already been successfully integrated into a unified framework for those methods. In this work, we conduct an empirical study of GPT-4o's image generation capabilities, benchmarking it against leading open-source and commercial models. Our evaluation covers four main categories, including text-to-image, image-to-image, image-to-3D, and image-to-X generation, with more than 20 tasks. Our analysis highlights the strengths and limitations of GPT-4o under various settings, and situates it within the broader evolution of generative modeling. Through this investigation, we identify promising directions for future unified generative models, emphasizing the role of architectural design and data scaling.
4th PVUW MeViS 3rd Place Report: Sa2VA
Apr 01, 2025Referring video object segmentation (RVOS) is a challenging task that requires the model to segment the object in a video given the language description. MeViS is a recently proposed dataset that contains motion expressions of the target objects, leading to a challenging benchmark, compared with existing RVOS benchmarks. On the other hand, for referring expression tasks, a new trend is to adopt multi-modal large language model (MLLM) to achieve better image and text alignment. In this report, we show that with a simple modification to the test time inference method on stronger MLLMs, we can lead to stronger results on MeVIS. In particular, we adopt the recent method Sa2VA, a unified model for dense grounded understanding of both images and videos. By enlarging the scope of key frames, without any further training, we can achieve the 3rd place in the 4th PVUW workshop.
Are They the Same? Exploring Visual Correspondence Shortcomings of Multimodal LLMs
Jan 08, 2025
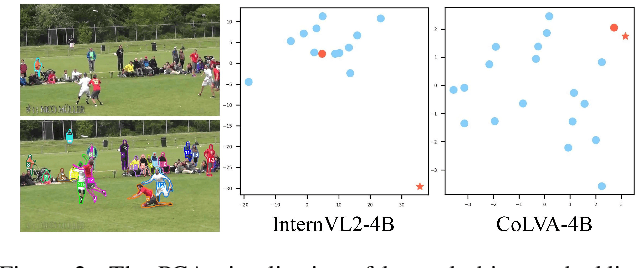


Recent advancements in multimodal models have shown a strong ability in visual perception, reasoning abilities, and vision-language understanding. However, studies on visual matching ability are missing, where finding the visual correspondence of objects is essential in vision research. Our research reveals that the matching capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings, even with current strong MLLMs models, GPT-4o. In particular, we construct a Multimodal Visual Matching (MMVM) benchmark to fairly benchmark over 30 different MLLMs. The MMVM benchmark is built from 15 open-source datasets and Internet videos with manual annotation. We categorize the data samples of MMVM benchmark into eight aspects based on the required cues and capabilities to more comprehensively evaluate and analyze current MLLMs. In addition, we have designed an automatic annotation pipeline to generate the MMVM SFT dataset, including 220K visual matching data with reasoning annotation. Finally, we present CoLVA, a novel contrastive MLLM with two novel technical designs: fine-grained vision expert with object-level contrastive learning and instruction augmentation strategy. CoLVA achieves 51.06\% overall accuracy (OA) on the MMVM benchmark, surpassing GPT-4o and baseline by 8.41\% and 23.58\% OA, respectively. The results show the effectiveness of our MMVM SFT dataset and our novel technical designs. Code, benchmark, dataset, and models are available at https://github.com/zhouyiks/CoLVA.
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Jan 07, 2025



This work presents Sa2VA, the first unified model for dense grounded understanding of both images and videos. Unlike existing multi-modal large language models, which are often limited to specific modalities and tasks, Sa2VA supports a wide range of image and video tasks, including referring segmentation and conversation, with minimal one-shot instruction tuning. Sa2VA combines SAM-2, a foundation video segmentation model, with LLaVA, an advanced vision-language model, and unifies text, image, and video into a shared LLM token space. Using the LLM, Sa2VA generates instruction tokens that guide SAM-2 in producing precise masks, enabling a grounded, multi-modal understanding of both static and dynamic visual content. Additionally, we introduce Ref-SAV, an auto-labeled dataset containing over 72k object expressions in complex video scenes, designed to boost model performance. We also manually validate 2k video objects in the Ref-SAV datasets to benchmark referring video object segmentation in complex environments. Experiments show that Sa2VA achieves state-of-the-art across multiple tasks, particularly in referring video object segmentation, highlighting its potential for complex real-world applications.
RLRF4Rec: Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking
Oct 08, 2024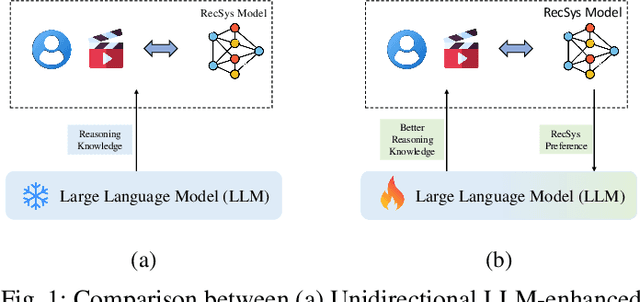



Large Language Models (LLMs) have demonstrated remarkable performance across diverse domains, prompting researchers to explore their potential for use in recommendation systems. Initial attempts have leveraged the exceptional capabilities of LLMs, such as rich knowledge and strong generalization through In-context Learning, which involves phrasing the recommendation task as prompts. Nevertheless, the performance of LLMs in recommendation tasks remains suboptimal due to a substantial disparity between the training tasks for LLMs and recommendation tasks and inadequate recommendation data during pre-training. This paper introduces RLRF4Rec, a novel framework integrating Reinforcement Learning from Recsys Feedback for Enhanced Recommendation Reranking(RLRF4Rec) with LLMs to address these challenges. Specifically, We first have the LLM generate inferred user preferences based on user interaction history, which is then used to augment traditional ID-based sequence recommendation models. Subsequently, we trained a reward model based on knowledge augmentation recommendation models to evaluate the quality of the reasoning knowledge from LLM. We then select the best and worst responses from the N samples to construct a dataset for LLM tuning. Finally, we design a structure alignment strategy with Direct Preference Optimization(DPO). We validate the effectiveness of RLRF4Rec through extensive experiments, demonstrating significant improvements in recommendation re-ranking metrics compared to baselines. This demonstrates that our approach significantly improves the capability of LLMs to respond to instructions within recommender systems.