 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCineDance: Towards Next-Generation Multi-Shot Long-Form Cinematic Audio-Video Generation
Jun 08, 2026The fidelity and structural diversity of training datasets fundamentally determine the capabilities of video generation models. While commercial systems showremarkableabilitytogeneratecinematicnarratives, the progress of open-source models remains limited by the scarcity of high-quality training data. To bridge this gap, we introduce CineDance-1M, a large-scale, open research Text-to-Audio-Video (T2AV) dataset designed specifically for multi-shot, long-form joint audio-video generation. Averaging 92.8 seconds and 24.2 continuous shots per video, it provides configurable, structured annotations for both audio and video modalities. This exceptional quality is achieved through a rigorous three-stage curation pipeline: i) diverse sourcing and comprehensive cleansing, ii) film-theory-inspired narrative parsing, and iii) hierarchical dual-modal captioning. For a comprehensive assessment, we propose CineBench, featuring a diverse prompt suite and a six-dimensional, human-aligned metric system tailored for complex narrative audio-video evaluation. Furthermore, we adapt LTX-2.3 into CineDance, which demonstrates exceptional single-modality quality alongside precise audio-video alignment and robust subject and environment consistency, effectively validating our curation strategy and the high quality of CineDance-1M. We anticipate that this work will serve as a solid foundation for accelerating future research in multi-shot, long-form joint audio-video generation. Our project page is available at https://aliothchen.github.io/projects/CineDance/.
Watch, Remember, Reason: Human-View Video Understanding with MLLMs
Jun 05, 2026Video understanding is being rapidly transformed by multimodal large language models (MLLMs), as research moves from short clips to long, multimodal, and knowledge-intensive video scenarios. These scenarios require models to handle sparse evidence, long-range dependencies, multimodal alignment, and reliable inference under limited computational budgets. This work presents a human-view perspective on LLM-based video understanding, organized around three functional abilities: watching, remembering, and reasoning. Rather than treating video tasks as isolated benchmarks, this view provides a unified structure for analyzing how video MLLMs acquire evidence, preserve context, and produce grounded outputs. We introduce a formulation that characterizes video understanding systems by their perceptual representations, memory states, reasoning traces, and final predictions. Based on this formulation, we identify challenges in spatio-temporal perception, efficient long-video processing, memory modeling, streaming understanding, and faithful reasoning. Representative methods are organized by their roles in video MLLM systems. Watching covers fine-grained, comprehensive, audio-visual, and efficient perception. Remembering includes offline and streaming memory, while reasoning covers text-only reasoning and thinking with videos. We further examine application domains such as egocentric, sports, instructional, medical, and narrative videos, and cover training datasets and evaluation benchmarks across task types, supervision formats, modalities, and capability dimensions. Finally, we outline open problems and future directions for scalable, memory-aware, and evidence-grounded video intelligence. Related works will be continuously traced at https://github.com/marinero4972/Awesome-HumanView-VideoUnderstanding.
Mamba Learns in Context: Structure-Aware Domain Generalization for Multi-Task Point Cloud Understanding
Mar 21, 2026While recent Transformer and Mamba architectures have advanced point cloud representation learning, they are typically developed for single-task or single-domain settings. Directly applying them to multi-task domain generalization (DG) leads to degraded performance. Transformers effectively model global dependencies but suffer from quadratic attention cost and lack explicit structural ordering, whereas Mamba offers linear-time recurrence yet often depends on coordinate-driven serialization, which is sensitive to viewpoint changes and missing regions, causing structural drift and unstable sequential modeling. In this paper, we propose Structure-Aware Domain Generalization (SADG), a Mamba-based In-Context Learning framework that preserves structural hierarchy across domains and tasks. We design structure-aware serialization (SAS) that generates transformation-invariant sequences using centroid-based topology and geodesic curvature continuity. We further devise hierarchical domain-aware modeling (HDM) that stabilizes cross-domain reasoning by consolidating intra-domain structure and fusing inter-domain relations. At test time, we introduce a lightweight spectral graph alignment (SGA) that shifts target features toward source prototypes in the spectral domain without updating model parameters, ensuring structure-preserving test-time feature shifting. In addition, we introduce MP3DObject, a real-scan object dataset for multi-task DG evaluation. Comprehensive experiments demonstrate that the proposed approach improves structural fidelity and consistently outperforms state-of-the-art methods across multiple tasks including reconstruction, denoising, and registration.
Efficiency-Aware Computational Intelligence for Resource-Constrained Manufacturing Toward Edge-Ready Deployment
Dec 10, 2025



Industrial cyber physical systems operate under heterogeneous sensing, stochastic dynamics, and shifting process conditions, producing data that are often incomplete, unlabeled, imbalanced, and domain shifted. High-fidelity datasets remain costly, confidential, and slow to obtain, while edge devices face strict limits on latency, bandwidth, and energy. These factors restrict the practicality of centralized deep learning, hinder the development of reliable digital twins, and increase the risk of error escape in safety-critical applications. Motivated by these challenges, this dissertation develops an efficiency grounded computational framework that enables data lean, physics-aware, and deployment ready intelligence for modern manufacturing environments. The research advances methods that collectively address core bottlenecks across multimodal and multiscale industrial scenarios. Generative strategies mitigate data scarcity and imbalance, while semi-supervised learning integrates unlabeled information to reduce annotation and simulation demands. Physics-informed representation learning strengthens interpretability and improves condition monitoring under small-data regimes. Spatially aware graph-based surrogate modeling provides efficient approximation of complex processes, and an edge cloud collaborative compression scheme supports real-time signal analytics under resource constraints. The dissertation also extends visual understanding through zero-shot vision language reasoning augmented by domain specific retrieval, enabling generalizable assessment in previously unseen scenarios. Together, these developments establish a unified paradigm of data efficient and resource aware intelligence that bridges laboratory learning with industrial deployment, supporting reliable decision-making across diverse manufacturing systems.
Seeing the Unseen: Towards Zero-Shot Inspection for Wind Turbine Blades using Knowledge-Augmented Vision Language Models
Oct 26, 2025Wind turbine blades operate in harsh environments, making timely damage detection essential for preventing failures and optimizing maintenance. Drone-based inspection and deep learning are promising, but typically depend on large, labeled datasets, which limit their ability to detect rare or evolving damage types. To address this, we propose a zero-shot-oriented inspection framework that integrates Retrieval-Augmented Generation (RAG) with Vision-Language Models (VLM). A multimodal knowledge base is constructed, comprising technical documentation, representative reference images, and domain-specific guidelines. A hybrid text-image retriever with keyword-aware reranking assembles the most relevant context to condition the VLM at inference, injecting domain knowledge without task-specific training. We evaluate the framework on 30 labeled blade images covering diverse damage categories. Although the dataset is small due to the difficulty of acquiring verified blade imagery, it covers multiple representative defect types. On this test set, the RAG-grounded VLM correctly classified all samples, whereas the same VLM without retrieval performed worse in both accuracy and precision. We further compare against open-vocabulary baselines and incorporate uncertainty Clopper-Pearson confidence intervals to account for the small-sample setting. Ablation studies indicate that the key advantage of the framework lies in explainability and generalizability: retrieved references ground the reasoning process and enable the detection of previously unseen defects by leveraging domain knowledge rather than relying solely on visual cues. This research contributes a data-efficient solution for industrial inspection that reduces dependence on extensive labeled datasets.
PointDGRWKV: Generalizing RWKV-like Architecture to Unseen Domains for Point Cloud Classification
Aug 29, 2025



Domain Generalization (DG) has been recently explored to enhance the generalizability of Point Cloud Classification (PCC) models toward unseen domains. Prior works are based on convolutional networks, Transformer or Mamba architectures, either suffering from limited receptive fields or high computational cost, or insufficient long-range dependency modeling. RWKV, as an emerging architecture, possesses superior linear complexity, global receptive fields, and long-range dependency. In this paper, we present the first work that studies the generalizability of RWKV models in DG PCC. We find that directly applying RWKV to DG PCC encounters two significant challenges: RWKV's fixed direction token shift methods, like Q-Shift, introduce spatial distortions when applied to unstructured point clouds, weakening local geometric modeling and reducing robustness. In addition, the Bi-WKV attention in RWKV amplifies slight cross-domain differences in key distributions through exponential weighting, leading to attention shifts and degraded generalization. To this end, we propose PointDGRWKV, the first RWKV-based framework tailored for DG PCC. It introduces two key modules to enhance spatial modeling and cross-domain robustness, while maintaining RWKV's linear efficiency. In particular, we present Adaptive Geometric Token Shift to model local neighborhood structures to improve geometric context awareness. In addition, Cross-Domain key feature Distribution Alignment is designed to mitigate attention drift by aligning key feature distributions across domains. Extensive experiments on multiple benchmarks demonstrate that PointDGRWKV achieves state-of-the-art performance on DG PCC.
DiffDecompose: Layer-Wise Decomposition of Alpha-Composited Images via Diffusion Transformers
May 30, 2025Diffusion models have recently motivated great success in many generation tasks like object removal. Nevertheless, existing image decomposition methods struggle to disentangle semi-transparent or transparent layer occlusions due to mask prior dependencies, static object assumptions, and the lack of datasets. In this paper, we delve into a novel task: Layer-Wise Decomposition of Alpha-Composited Images, aiming to recover constituent layers from single overlapped images under the condition of semi-transparent/transparent alpha layer non-linear occlusion. To address challenges in layer ambiguity, generalization, and data scarcity, we first introduce AlphaBlend, the first large-scale and high-quality dataset for transparent and semi-transparent layer decomposition, supporting six real-world subtasks (e.g., translucent flare removal, semi-transparent cell decomposition, glassware decomposition). Building on this dataset, we present DiffDecompose, a diffusion Transformer-based framework that learns the posterior over possible layer decompositions conditioned on the input image, semantic prompts, and blending type. Rather than regressing alpha mattes directly, DiffDecompose performs In-Context Decomposition, enabling the model to predict one or multiple layers without per-layer supervision, and introduces Layer Position Encoding Cloning to maintain pixel-level correspondence across layers. Extensive experiments on the proposed AlphaBlend dataset and public LOGO dataset verify the effectiveness of DiffDecompose. The code and dataset will be available upon paper acceptance. Our code will be available at: https://github.com/Wangzt1121/DiffDecompose.
Conditional Panoramic Image Generation via Masked Autoregressive Modeling
May 22, 2025
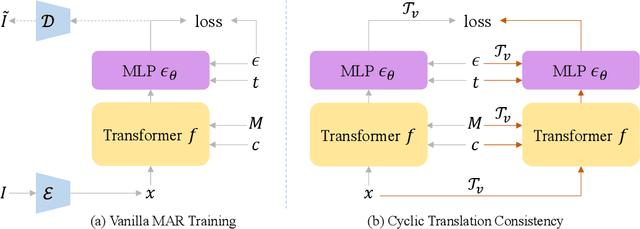
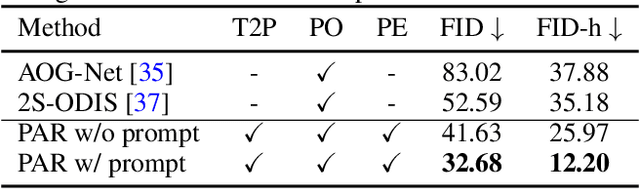

Recent progress in panoramic image generation has underscored two critical limitations in existing approaches. First, most methods are built upon diffusion models, which are inherently ill-suited for equirectangular projection (ERP) panoramas due to the violation of the identically and independently distributed (i.i.d.) Gaussian noise assumption caused by their spherical mapping. Second, these methods often treat text-conditioned generation (text-to-panorama) and image-conditioned generation (panorama outpainting) as separate tasks, relying on distinct architectures and task-specific data. In this work, we propose a unified framework, Panoramic AutoRegressive model (PAR), which leverages masked autoregressive modeling to address these challenges. PAR avoids the i.i.d. assumption constraint and integrates text and image conditioning into a cohesive architecture, enabling seamless generation across tasks. To address the inherent discontinuity in existing generative models, we introduce circular padding to enhance spatial coherence and propose a consistency alignment strategy to improve generation quality. Extensive experiments demonstrate competitive performance in text-to-image generation and panorama outpainting tasks while showcasing promising scalability and generalization capabilities.
ScanBot: Towards Intelligent Surface Scanning in Embodied Robotic Systems
May 22, 2025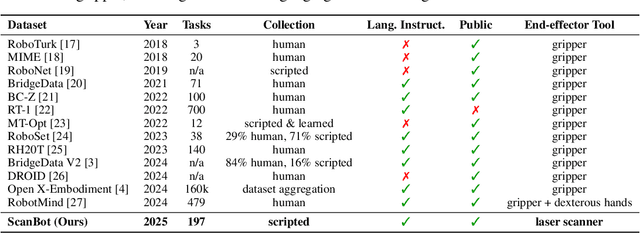



We introduce ScanBot, a novel dataset designed for instruction-conditioned, high-precision surface scanning in robotic systems. In contrast to existing robot learning datasets that focus on coarse tasks such as grasping, navigation, or dialogue, ScanBot targets the high-precision demands of industrial laser scanning, where sub-millimeter path continuity and parameter stability are critical. The dataset covers laser scanning trajectories executed by a robot across 12 diverse objects and 6 task types, including full-surface scans, geometry-focused regions, spatially referenced parts, functionally relevant structures, defect inspection, and comparative analysis. Each scan is guided by natural language instructions and paired with synchronized RGB, depth, and laser profiles, as well as robot pose and joint states. Despite recent progress, existing vision-language action (VLA) models still fail to generate stable scanning trajectories under fine-grained instructions and real-world precision demands. To investigate this limitation, we benchmark a range of multimodal large language models (MLLMs) across the full perception-planning-execution loop, revealing persistent challenges in instruction-following under realistic constraints.
Domain Generalization via Discrete Codebook Learning
Apr 09, 2025Domain generalization (DG) strives to address distribution shifts across diverse environments to enhance model's generalizability. Current DG approaches are confined to acquiring robust representations with continuous features, specifically training at the pixel level. However, this DG paradigm may struggle to mitigate distribution gaps in dealing with a large space of continuous features, rendering it susceptible to pixel details that exhibit spurious correlations or noise. In this paper, we first theoretically demonstrate that the domain gaps in continuous representation learning can be reduced by the discretization process. Based on this inspiring finding, we introduce a novel learning paradigm for DG, termed Discrete Domain Generalization (DDG). DDG proposes to use a codebook to quantize the feature map into discrete codewords, aligning semantic-equivalent information in a shared discrete representation space that prioritizes semantic-level information over pixel-level intricacies. By learning at the semantic level, DDG diminishes the number of latent features, optimizing the utilization of the representation space and alleviating the risks associated with the wide-ranging space of continuous features. Extensive experiments across widely employed benchmarks in DG demonstrate DDG's superior performance compared to state-of-the-art approaches, underscoring its potential to reduce the distribution gaps and enhance the model's generalizability.