 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Unseen: Towards Zero-Shot Inspection for Wind Turbine Blades using Knowledge-Augmented Vision Language Models
Oct 26, 2025Wind turbine blades operate in harsh environments, making timely damage detection essential for preventing failures and optimizing maintenance. Drone-based inspection and deep learning are promising, but typically depend on large, labeled datasets, which limit their ability to detect rare or evolving damage types. To address this, we propose a zero-shot-oriented inspection framework that integrates Retrieval-Augmented Generation (RAG) with Vision-Language Models (VLM). A multimodal knowledge base is constructed, comprising technical documentation, representative reference images, and domain-specific guidelines. A hybrid text-image retriever with keyword-aware reranking assembles the most relevant context to condition the VLM at inference, injecting domain knowledge without task-specific training. We evaluate the framework on 30 labeled blade images covering diverse damage categories. Although the dataset is small due to the difficulty of acquiring verified blade imagery, it covers multiple representative defect types. On this test set, the RAG-grounded VLM correctly classified all samples, whereas the same VLM without retrieval performed worse in both accuracy and precision. We further compare against open-vocabulary baselines and incorporate uncertainty Clopper-Pearson confidence intervals to account for the small-sample setting. Ablation studies indicate that the key advantage of the framework lies in explainability and generalizability: retrieved references ground the reasoning process and enable the detection of previously unseen defects by leveraging domain knowledge rather than relying solely on visual cues. This research contributes a data-efficient solution for industrial inspection that reduces dependence on extensive labeled datasets.
Knowledge Graph Fusion with Large Language Models for Accurate, Explainable Manufacturing Process Planning
Jun 16, 2025Precision process planning in Computer Numerical Control (CNC) machining demands rapid, context-aware decisions on tool selection, feed-speed pairs, and multi-axis routing, placing immense cognitive and procedural burdens on engineers from design specification through final part inspection. Conventional rule-based computer-aided process planning and knowledge-engineering shells freeze domain know-how into static tables, which become limited when dealing with unseen topologies, novel material states, shifting cost-quality-sustainability weightings, or shop-floor constraints such as tool unavailability and energy caps. Large language models (LLMs) promise flexible, instruction-driven reasoning for tasks but they routinely hallucinate numeric values and provide no provenance. We present Augmented Retrieval Knowledge Network Enhanced Search & Synthesis (ARKNESS), the end-to-end framework that fuses zero-shot Knowledge Graph (KG) construction with retrieval-augmented generation to deliver verifiable, numerically exact answers for CNC process planning. ARKNESS (1) automatically distills heterogeneous machining documents, G-code annotations, and vendor datasheets into augmented triple, multi-relational graphs without manual labeling, and (2) couples any on-prem LLM with a retriever that injects the minimal, evidence-linked subgraph needed to answer a query. Benchmarked on 155 industry-curated questions spanning tool sizing and feed-speed optimization, a lightweight 3B-parameter Llama-3 augmented by ARKNESS matches GPT-4o accuracy while achieving a +25 percentage point gain in multiple-choice accuracy, +22.4 pp in F1, and 8.1x ROUGE-L on open-ended responses.
ScanBot: Towards Intelligent Surface Scanning in Embodied Robotic Systems
May 22, 2025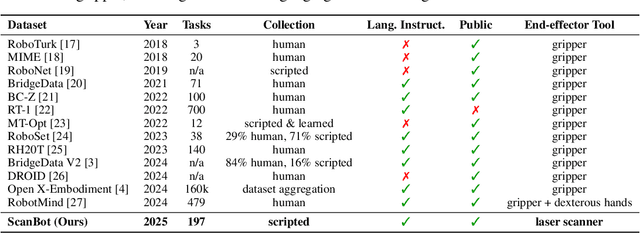



We introduce ScanBot, a novel dataset designed for instruction-conditioned, high-precision surface scanning in robotic systems. In contrast to existing robot learning datasets that focus on coarse tasks such as grasping, navigation, or dialogue, ScanBot targets the high-precision demands of industrial laser scanning, where sub-millimeter path continuity and parameter stability are critical. The dataset covers laser scanning trajectories executed by a robot across 12 diverse objects and 6 task types, including full-surface scans, geometry-focused regions, spatially referenced parts, functionally relevant structures, defect inspection, and comparative analysis. Each scan is guided by natural language instructions and paired with synchronized RGB, depth, and laser profiles, as well as robot pose and joint states. Despite recent progress, existing vision-language action (VLA) models still fail to generate stable scanning trajectories under fine-grained instructions and real-world precision demands. To investigate this limitation, we benchmark a range of multimodal large language models (MLLMs) across the full perception-planning-execution loop, revealing persistent challenges in instruction-following under realistic constraints.
Multimodal RAG-driven Anomaly Detection and Classification in Laser Powder Bed Fusion using Large Language Models
May 20, 2025Additive manufacturing enables the fabrication of complex designs while minimizing waste, but faces challenges related to defects and process anomalies. This study presents a novel multimodal Retrieval-Augmented Generation-based framework that automates anomaly detection across various Additive Manufacturing processes leveraging retrieved information from literature, including images and descriptive text, rather than training datasets. This framework integrates text and image retrieval from scientific literature and multimodal generation models to perform zero-shot anomaly identification, classification, and explanation generation in a Laser Powder Bed Fusion setting. The proposed framework is evaluated on four L-PBF manufacturing datasets from Oak Ridge National Laboratory, featuring various printer makes, models, and materials. This evaluation demonstrates the framework's adaptability and generalizability across diverse images without requiring additional training. Comparative analysis using Qwen2-VL-2B and GPT-4o-mini as MLLM within the proposed framework highlights that GPT-4o-mini outperforms Qwen2-VL-2B and proportional random baseline in manufacturing anomalies classification. Additionally, the evaluation of the RAG system confirms that incorporating retrieval mechanisms improves average accuracy by 12% by reducing the risk of hallucination and providing additional information. The proposed framework can be continuously updated by integrating emerging research, allowing seamless adaptation to the evolving landscape of AM technologies. This scalable, automated, and zero-shot-capable framework streamlines AM anomaly analysis, enhancing efficiency and accuracy.
Can Multimodal Large Language Models be Guided to Improve Industrial Anomaly Detection?
Jan 27, 2025In industrial settings, the accurate detection of anomalies is essential for maintaining product quality and ensuring operational safety. Traditional industrial anomaly detection (IAD) models often struggle with flexibility and adaptability, especially in dynamic production environments where new defect types and operational changes frequently arise. Recent advancements in Multimodal Large Language Models (MLLMs) hold promise for overcoming these limitations by combining visual and textual information processing capabilities. MLLMs excel in general visual understanding due to their training on large, diverse datasets, but they lack domain-specific knowledge, such as industry-specific defect tolerance levels, which limits their effectiveness in IAD tasks. To address these challenges, we propose Echo, a novel multi-expert framework designed to enhance MLLM performance for IAD. Echo integrates four expert modules: Reference Extractor which provides a contextual baseline by retrieving similar normal images, Knowledge Guide which supplies domain-specific insights, Reasoning Expert which enables structured, stepwise reasoning for complex queries, and Decision Maker which synthesizes information from all modules to deliver precise, context-aware responses. Evaluated on the MMAD benchmark, Echo demonstrates significant improvements in adaptability, precision, and robustness, moving closer to meeting the demands of real-world industrial anomaly detection.
Vision Language Model for Interpretable and Fine-grained Detection of Safety Compliance in Diverse Workplaces
Aug 13, 2024Workplace accidents due to personal protective equipment (PPE) non-compliance raise serious safety concerns and lead to legal liabilities, financial penalties, and reputational damage. While object detection models have shown the capability to address this issue by identifying safety items, most existing models, such as YOLO, Faster R-CNN, and SSD, are limited in verifying the fine-grained attributes of PPE across diverse workplace scenarios. Vision language models (VLMs) are gaining traction for detection tasks by leveraging the synergy between visual and textual information, offering a promising solution to traditional object detection limitations in PPE recognition. Nonetheless, VLMs face challenges in consistently verifying PPE attributes due to the complexity and variability of workplace environments, requiring them to interpret context-specific language and visual cues simultaneously. We introduce Clip2Safety, an interpretable detection framework for diverse workplace safety compliance, which comprises four main modules: scene recognition, the visual prompt, safety items detection, and fine-grained verification. The scene recognition identifies the current scenario to determine the necessary safety gear. The visual prompt formulates the specific visual prompts needed for the detection process. The safety items detection identifies whether the required safety gear is being worn according to the specified scenario. Lastly, the fine-grained verification assesses whether the worn safety equipment meets the fine-grained attribute requirements. We conduct real-world case studies across six different scenarios. The results show that Clip2Safety not only demonstrates an accuracy improvement over state-of-the-art question-answering based VLMs but also achieves inference times two hundred times faster.
Towards Intelligent Cooperative Robotics in Additive Manufacturing: Past, Present and Future
Aug 09, 2024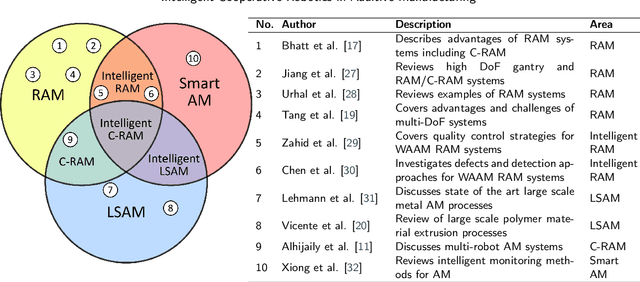
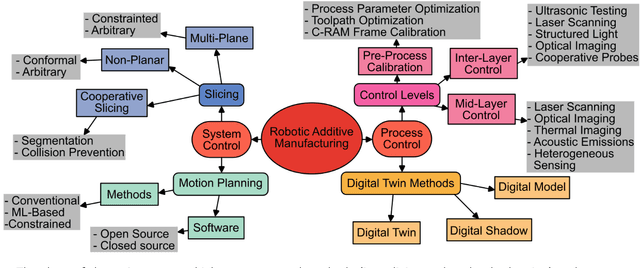
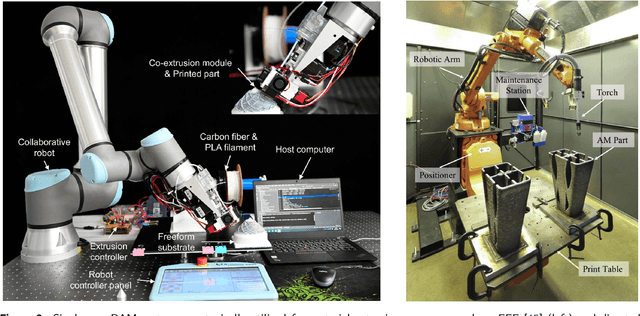
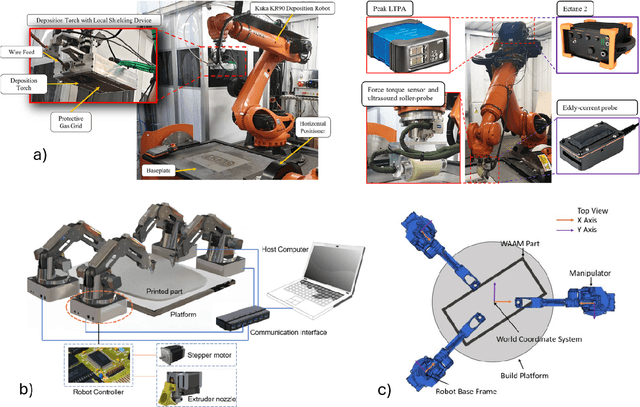
Additive manufacturing (AM) technologies have undergone significant advancements through the integration of cooperative robotics additive manufacturing (C-RAM) platforms. By deploying AM processes on the end effectors of multiple robotic arms, not only are traditional constraints such as limited build volumes circumvented, but systems also achieve accelerated fabrication speeds, cooperative sensing capabilities, and in-situ multi-material deposition. Despite advancements, challenges remain, particularly regarding defect generation including voids, cracks, and residual stress. Various factors contribute to these issues, including toolpath planning (i.e., slicing strategies), part decomposition for cooperative printing, and motion planning (i.e., path and trajectory planning). This review first examines the critical aspects of system control for C-RAM systems comprised of slicing and motion planning. The methods for the mitigation of defects through the adjustment of these aspects and the process parameters of AM methods are then described in the context of how they modify the AM process: pre-process, inter-layer (i.e., during layer pauses), and mid-layer (i.e., during material deposition). The application of advanced sensing technologies, including high-resolution cameras, laser scanners, and thermal imaging, to facilitate the capture of micro, meso, and macro-scale defects is explored. The role of digital twins is analyzed, emphasizing their capability to simulate and predict manufacturing outcomes, enabling preemptive adjustments to prevent defects. Finally, the outlook and future opportunities for developing next-generation C-RAM systems are outlined.
Explainable Hyperdimensional Computing for Balancing Privacy and Transparency in Additive Manufacturing Monitoring
Jul 10, 2024



In-situ sensing, in conjunction with learning models, presents a unique opportunity to address persistent defect issues in Additive Manufacturing (AM) processes. However, this integration introduces significant data privacy concerns, such as data leakage, sensor data compromise, and model inversion attacks, revealing critical details about part design, material composition, and machine parameters. Differential Privacy (DP) models, which inject noise into data under mathematical guarantees, offer a nuanced balance between data utility and privacy by obscuring traces of sensing data. However, the introduction of noise into learning models, often functioning as black boxes, complicates the prediction of how specific noise levels impact model accuracy. This study introduces the Differential Privacy-HyperDimensional computing (DP-HD) framework, leveraging the explainability of the vector symbolic paradigm to predict the noise impact on the accuracy of in-situ monitoring, safeguarding sensitive data while maintaining operational efficiency. Experimental results on real-world high-speed melt pool data of AM for detecting overhang anomalies demonstrate that DP-HD achieves superior operational efficiency, prediction accuracy, and robust privacy protection, outperforming state-of-the-art Machine Learning (ML) models. For example, when implementing the same level of privacy protection (with a privacy budget set at 1), our model achieved an accuracy of 94.43%, surpassing the performance of traditional models such as ResNet50 (52.30%), GoogLeNet (23.85%), AlexNet (55.78%), DenseNet201 (69.13%), and EfficientNet B2 (40.81%). Notably, DP-HD maintains high performance under substantial noise additions designed to enhance privacy, unlike current models that suffer significant accuracy declines under high privacy constraints.
Spiking Hyperdimensional Network: Neuromorphic Models Integrated with Memory-Inspired Framework
Oct 01, 2021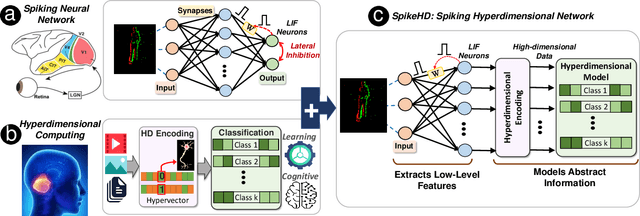
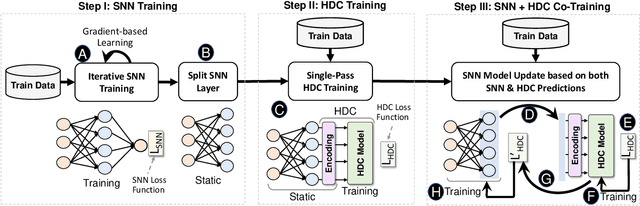
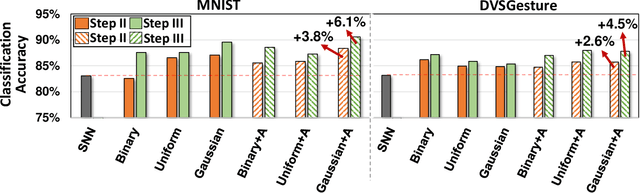
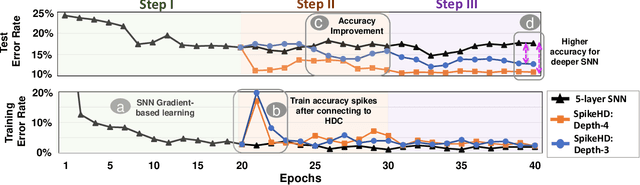
Recently, brain-inspired computing models have shown great potential to outperform today's deep learning solutions in terms of robustness and energy efficiency. Particularly, Spiking Neural Networks (SNNs) and HyperDimensional Computing (HDC) have shown promising results in enabling efficient and robust cognitive learning. Despite the success, these two brain-inspired models have different strengths. While SNN mimics the physical properties of the human brain, HDC models the brain on a more abstract and functional level. Their design philosophies demonstrate complementary patterns that motivate their combination. With the help of the classical psychological model on memory, we propose SpikeHD, the first framework that fundamentally combines Spiking neural network and hyperdimensional computing. SpikeHD generates a scalable and strong cognitive learning system that better mimics brain functionality. SpikeHD exploits spiking neural networks to extract low-level features by preserving the spatial and temporal correlation of raw event-based spike data. Then, it utilizes HDC to operate over SNN output by mapping the signal into high-dimensional space, learning the abstract information, and classifying the data. Our extensive evaluation on a set of benchmark classification problems shows that SpikeHD provides the following benefit compared to SNN architecture: (1) significantly enhance learning capability by exploiting two-stage information processing, (2) enables substantial robustness to noise and failure, and (3) reduces the network size and required parameters to learn complex information.