 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal RAG-driven Anomaly Detection and Classification in Laser Powder Bed Fusion using Large Language Models
May 20, 2025Additive manufacturing enables the fabrication of complex designs while minimizing waste, but faces challenges related to defects and process anomalies. This study presents a novel multimodal Retrieval-Augmented Generation-based framework that automates anomaly detection across various Additive Manufacturing processes leveraging retrieved information from literature, including images and descriptive text, rather than training datasets. This framework integrates text and image retrieval from scientific literature and multimodal generation models to perform zero-shot anomaly identification, classification, and explanation generation in a Laser Powder Bed Fusion setting. The proposed framework is evaluated on four L-PBF manufacturing datasets from Oak Ridge National Laboratory, featuring various printer makes, models, and materials. This evaluation demonstrates the framework's adaptability and generalizability across diverse images without requiring additional training. Comparative analysis using Qwen2-VL-2B and GPT-4o-mini as MLLM within the proposed framework highlights that GPT-4o-mini outperforms Qwen2-VL-2B and proportional random baseline in manufacturing anomalies classification. Additionally, the evaluation of the RAG system confirms that incorporating retrieval mechanisms improves average accuracy by 12% by reducing the risk of hallucination and providing additional information. The proposed framework can be continuously updated by integrating emerging research, allowing seamless adaptation to the evolving landscape of AM technologies. This scalable, automated, and zero-shot-capable framework streamlines AM anomaly analysis, enhancing efficiency and accuracy.
FDM-Bench: A Comprehensive Benchmark for Evaluating Large Language Models in Additive Manufacturing Tasks
Dec 13, 2024

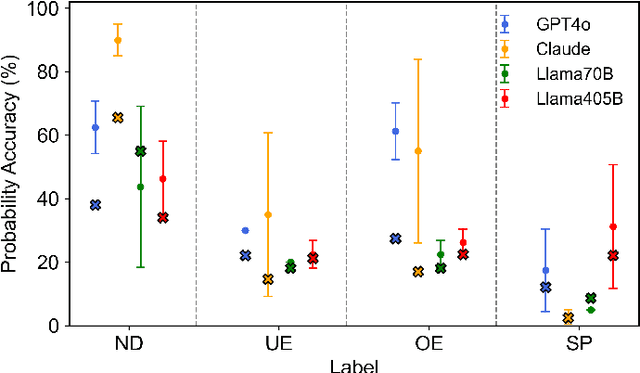
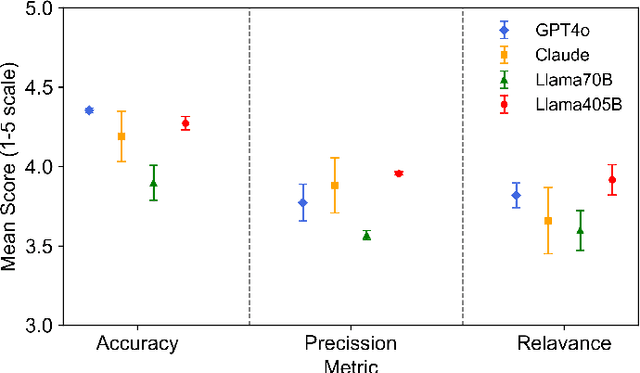
Fused Deposition Modeling (FDM) is a widely used additive manufacturing (AM) technique valued for its flexibility and cost-efficiency, with applications in a variety of industries including healthcare and aerospace. Recent developments have made affordable FDM machines accessible and encouraged adoption among diverse users. However, the design, planning, and production process in FDM require specialized interdisciplinary knowledge. Managing the complex parameters and resolving print defects in FDM remain challenging. These technical complexities form the most critical barrier preventing individuals without technical backgrounds and even professional engineers without training in other domains from participating in AM design and manufacturing. Large Language Models (LLMs), with their advanced capabilities in text and code processing, offer the potential for addressing these challenges in FDM. However, existing research on LLM applications in this field is limited, typically focusing on specific use cases without providing comprehensive evaluations across multiple models and tasks. To this end, we introduce FDM-Bench, a benchmark dataset designed to evaluate LLMs on FDM-specific tasks. FDM-Bench enables a thorough assessment by including user queries across various experience levels and G-code samples that represent a range of anomalies. We evaluate two closed-source models (GPT-4o and Claude 3.5 Sonnet) and two open-source models (Llama-3.1-70B and Llama-3.1-405B) on FDM-Bench. A panel of FDM experts assess the models' responses to user queries in detail. Results indicate that closed-source models generally outperform open-source models in G-code anomaly detection, whereas Llama-3.1-405B demonstrates a slight advantage over other models in responding to user queries. These findings underscore FDM-Bench's potential as a foundational tool for advancing research on LLM capabilities in FDM.
Accelerated and Inexpensive Machine Learning for Manufacturing Processes with Incomplete Mechanistic Knowledge
Apr 29, 2023



Machine Learning (ML) is of increasing interest for modeling parametric effects in manufacturing processes. But this approach is limited to established processes for which a deep physics-based understanding has been developed over time, since state-of-the-art approaches focus on reducing the experimental and/or computational costs of generating the training data but ignore the inherent and significant cost of developing qualitatively accurate physics-based models for new processes . This paper proposes a transfer learning based approach to address this issue, in which a ML model is trained on a large amount of computationally inexpensive data from a physics-based process model (source) and then fine-tuned on a smaller amount of costly experimental data (target). The novelty lies in pushing the boundaries of the qualitative accuracy demanded of the source model, which is assumed to be high in the literature, and is the root of the high model development cost. Our approach is evaluated for modeling the printed line width in Fused Filament Fabrication. Despite extreme functional and quantitative inaccuracies in the source our approach reduces the model development cost by years, experimental cost by 56-76%, computational cost by orders of magnitude, and prediction error by 16-24%.