 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDM-Bench: A Comprehensive Benchmark for Evaluating Large Language Models in Additive Manufacturing Tasks
Dec 13, 2024

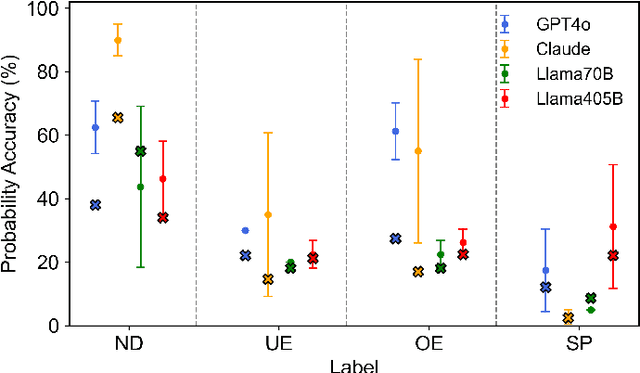
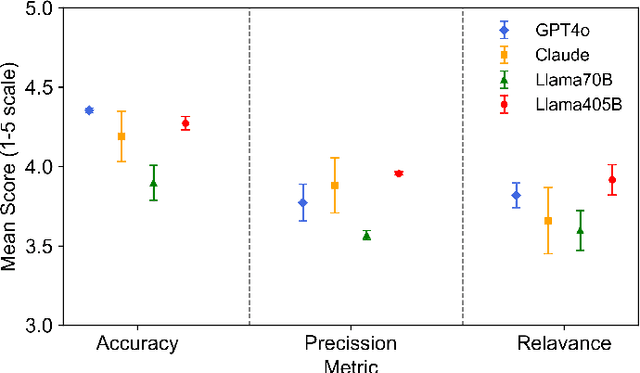
Fused Deposition Modeling (FDM) is a widely used additive manufacturing (AM) technique valued for its flexibility and cost-efficiency, with applications in a variety of industries including healthcare and aerospace. Recent developments have made affordable FDM machines accessible and encouraged adoption among diverse users. However, the design, planning, and production process in FDM require specialized interdisciplinary knowledge. Managing the complex parameters and resolving print defects in FDM remain challenging. These technical complexities form the most critical barrier preventing individuals without technical backgrounds and even professional engineers without training in other domains from participating in AM design and manufacturing. Large Language Models (LLMs), with their advanced capabilities in text and code processing, offer the potential for addressing these challenges in FDM. However, existing research on LLM applications in this field is limited, typically focusing on specific use cases without providing comprehensive evaluations across multiple models and tasks. To this end, we introduce FDM-Bench, a benchmark dataset designed to evaluate LLMs on FDM-specific tasks. FDM-Bench enables a thorough assessment by including user queries across various experience levels and G-code samples that represent a range of anomalies. We evaluate two closed-source models (GPT-4o and Claude 3.5 Sonnet) and two open-source models (Llama-3.1-70B and Llama-3.1-405B) on FDM-Bench. A panel of FDM experts assess the models' responses to user queries in detail. Results indicate that closed-source models generally outperform open-source models in G-code anomaly detection, whereas Llama-3.1-405B demonstrates a slight advantage over other models in responding to user queries. These findings underscore FDM-Bench's potential as a foundational tool for advancing research on LLM capabilities in FDM.