 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
May 21, 2026Spreadsheet systems (e.g., Microsoft Excel, Google Sheets) play a central role in modern data-centric workflows. As AI agents grow increasingly capable of automating complex tasks, such as controlling computers and generating presentations, building an AI-driven spreadsheet agent has emerged as a promising research direction. Most existing spreadsheet agents rely on specialized prompting over general-purpose LLMs; while this design has potentials on simple spreadsheet operations, it struggles to manage the complex, multi-step workflows typical of real-world applications. We introduce Spreadsheet-RL, a reinforcement learning (RL) fine-tuning framework designed to train specialized spreadsheet agents within a realistic Microsoft Excel environment. Spreadsheet-RL features an automated pipeline for scalable collection of paired start-goal spreadsheets from online forums, as well as domain-specific evaluation tasks in areas such as finance and supply chain management, which we compile into the new Domain-Spreadsheet benchmark dataset. It also includes a Spreadsheet Gym environment designed for multi-turn RL: Spreadsheet Gym exposes extensive Excel functionality through a Python sandbox, along with a refined harness that incorporates a comprehensive tool set and carefully designed tool-routing rules for spreadsheet tasks. Through comprehensive experiments, we show that Spreadsheet-RL substantially enhances AI agent's performance on both general and domain-specific spreadsheet tasks: it improves Qwen3-4B-Thinking-2507's Pass@1 on SpreadsheetBench from 12.0% to 23.4%, and raises Pass@1 from 8.4% to 17.2% on our curated Domain-Spreadsheet dataset. These results highlight Spreadsheet-RL's strong potential for generalization and real-world adoption in spreadsheet automation, and broadly, its promise for advancing LLM-based interactions with data interfaces in everyday work.
LLM-ADAM: A Generalizable LLM Agent Framework for Pre-Print Anomaly Detection in Additive Manufacturing
May 05, 2026Additive manufacturing (AM) continues to transform modern manufacturing by enabling flexible, on-demand production of complex geometries across diverse industries. Fused filament fabrication (FFF) has extended AM to laboratories, classrooms, and small production environments, but this accessibility shifts process-planning responsibility to users who may lack manufacturing expertise. A syntactically valid slicer profile can still encode thermally or geometrically harmful settings, and subtle G-code edits can alter extrusion, cooling, or adhesion before a print begins. Pre-print G-code screening catches accidental or adversarial machine-program errors before material or machine time is wasted. This paper proposes LLM-ADAM as a generalizable LLM framework for pre-print anomaly detection in AM. The framework decomposes the task into three roles: Extractor-LLM maps a G-code file to a structured process-parameter schema; Reference-LLM converts printer and material documentation into aligned operating ranges; and Judge-LLM interprets a deterministic deviation table and G-code evidence to decide whether a part is non-defective or belongs to an anomaly class. Printers, materials, and LLM backbones are interchangeable test conditions, not fixed assumptions. We evaluate the framework on an N=200 FFF G-code corpus spanning two desktop printer families, two materials, and five classes including non-defective, under-extrusion, over-extrusion, warping, and stringing. The best framework configuration reaches 87.5% accuracy, compared with 59.5% for the strongest engineered single-LLM baseline. The results show that structured decomposition, rather than backbone strength alone, is the dominant source of improvement, with defect classes identified at or near ceiling for leading configurations while residual errors concentrate on conservative false alarms for non-defective samples.
Adaptive Unknown Fault Detection and Few-Shot Continual Learning for Condition Monitoring in Ultrasonic Metal Welding
Apr 15, 2026Ultrasonic metal welding (UMW) is widely used in industrial applications but is sensitive to tool wear, surface contamination, and material variability, which can lead to unexpected process faults and unsatisfactory weld quality. Conventional monitoring systems typically rely on supervised learning models that assume all fault types are known in advance, limiting their ability to handle previously unseen process faults. To address this challenge, this paper proposes an adaptive condition monitoring approach that enables unknown fault detection and few-shot continual learning for UMW. Unknown faults are detected by analyzing hidden-layer representations of a multilayer perceptron and leveraging a statistical thresholding strategy. Once detected, the samples from unknown fault types are incorporated into the existing model through a continual learning procedure that selectively updates only the final layers of the network, which enables the model to recognize new fault types while preserving knowledge of existing classes. To accelerate the labeling process, cosine similarity transformation combined with a clustering algorithm groups similar unknown samples, thereby reducing manual labeling effort. Experimental results using a multi-sensor UMW dataset demonstrate that the proposed method achieves 96% accuracy in detecting unseen fault conditions while maintaining reliable classification of known classes. After incorporating a new fault type using only five labeled samples, the updated model achieves 98% testing classification accuracy. These results demonstrate that the proposed approach enables adaptive monitoring with minimal retraining cost and time. The proposed approach provides a scalable solution for continual learning in condition monitoring where new process conditions may constantly emerge over time and is extensible to other manufacturing processes.
QoS-QoE Translation with Large Language Model
Apr 09, 2026QoS-QoE translation is a fundamental problem in multimedia systems because it characterizes how measurable system and network conditions affect user-perceived experience. Although many prior studies have examined this relationship, their findings are often developed for specific setups and remain scattered across papers, experimental settings, and reporting formats, limiting systematic reuse, cross-scenario generalization, and large-scale analysis. To address this gap, we first introduce QoS-QoE Translation dataset, a source-grounded dataset of structured QoS-QoE relationships from the multimedia literature, with a focus on video streaming related tasks. We construct the dataset through an automated pipeline that combines paper curation, QoS-QoE relationship extraction, and iterative data evaluation. Each record preserves the extracted relationship together with parameter definitions, supporting evidence, and contextual metadata. We further evaluate the capability of large language models (LLMs) on QoS-QoE translation, both before and after supervised fine-tuning on our dataset, and show strong performance on both continuous-value and discrete-label prediction in bidirectional translation, from QoS-QoE and QoE-QoS. Our dataset provides a foundation for benchmarking LLMs in QoS-QoE translation and for supporting future LLM-based reasoning for multimedia quality prediction and optimization. The complete dataset and code are publicly available at https://yyu6969.github.io/qos-qoe-translation-page/, for full reproducibility and open access.
Viewport-based Neural 360° Image Compression
Mar 24, 2026Given the popularity of 360° images on social media platforms, 360° image compression becomes a critical technology for media storage and transmission. Conventional 360° image compression pipeline projects the spherical image into a single 2D plane, leading to issues of oversampling and distortion. In this paper, we propose a novel viewport-based neural compression pipeline for 360° images. By replacing the image projection in conventional 360° image compression pipelines with viewport extraction and efficiently compressing multiple viewports, the proposed pipeline minimizes the inherent oversampling and distortion issues. However, viewport extraction impedes information sharing between multiple viewports during compression, causing the loss of global information about the spherical image. To tackle this global information loss, we design a neural viewport codec to capture global prior information across multiple viewports and maximally compress the viewport data. The viewport codec is empowered by a transformer-based ViewPort ConText (VPCT) module that can be integrated with canonical learning-based 2D image compression structures. We compare the proposed pipeline with existing 360° image compression models and conventional 360° image compression pipelines building on learning-based 2D image codecs and standard hand-crafted codecs. Results show that our pipeline saves an average of $14.01\%$ bit consumption compared to the best-performing 360° image compression methods without compromising quality. The proposed VPCT-based codec also outperforms existing 2D image codecs in the viewport-based neural compression pipeline. Our code can be found at: https://github.com/Jingwei-Liao/VPCT.
Circuit Tracing in Vision-Language Models: Understanding the Internal Mechanisms of Multimodal Thinking
Feb 23, 2026Vision-language models (VLMs) are powerful but remain opaque black boxes. We introduce the first framework for transparent circuit tracing in VLMs to systematically analyze multimodal reasoning. By utilizing transcoders, attribution graphs, and attention-based methods, we uncover how VLMs hierarchically integrate visual and semantic concepts. We reveal that distinct visual feature circuits can handle mathematical reasoning and support cross-modal associations. Validated through feature steering and circuit patching, our framework proves these circuits are causal and controllable, laying the groundwork for more explainable and reliable VLMs.
No One-Model-Fits-All: Uncovering Spatio-Temporal Forecasting Trade-offs with Graph Neural Networks and Foundation Models
Nov 07, 2025
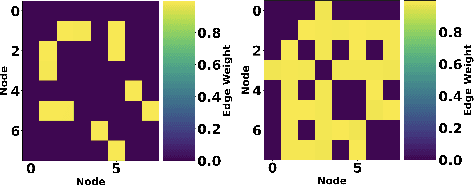
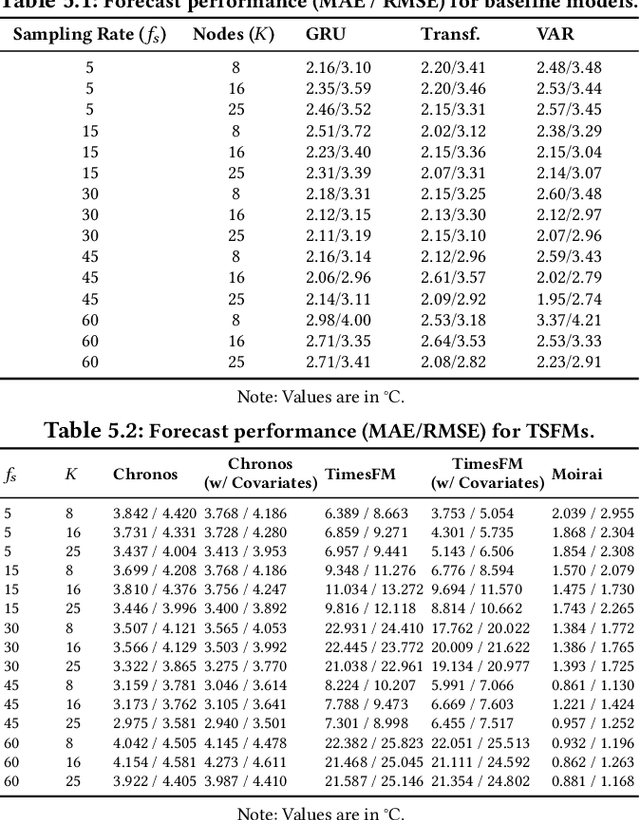
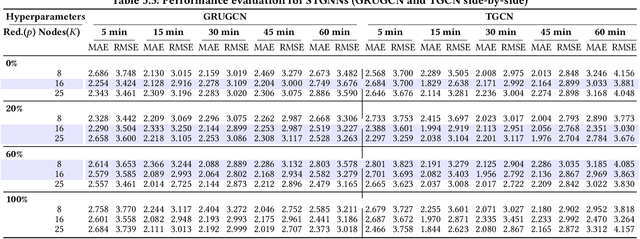
Modern IoT deployments for environmental sensing produce high volume spatiotemporal data to support downstream tasks such as forecasting, typically powered by machine learning models. While existing filtering and strategic deployment techniques optimize collected data volume at the edge, they overlook how variations in sampling frequencies and spatial coverage affect downstream model performance. In many forecasting models, incorporating data from additional sensors denoise predictions by providing broader spatial contexts. This interplay between sampling frequency, spatial coverage and different forecasting model architectures remain underexplored. This work presents a systematic study of forecasting models - classical models (VAR), neural networks (GRU, Transformer), spatio-temporal graph neural networks (STGNNs), and time series foundation models (TSFMs: Chronos Moirai, TimesFM) under varying spatial sensor nodes density and sampling intervals using real-world temperature data in a wireless sensor network. Our results show that STGNNs are effective when sensor deployments are sparse and sampling rate is moderate, leveraging spatial correlations via encoded graph structure to compensate for limited coverage. In contrast, TSFMs perform competitively at high frequencies but degrade when spatial coverage from neighboring sensors is reduced. Crucially, the multivariate TSFM Moirai outperforms all models by natively learning cross-sensor dependencies. These findings offer actionable insights for building efficient forecasting pipelines in spatio-temporal systems. All code for model configurations, training, dataset, and logs are open-sourced for reproducibility: https://github.com/UIUC-MONET-Projects/Benchmarking-Spatiotemporal-Forecast-Models
VTool-R1: VLMs Learn to Think with Images via Reinforcement Learning on Multimodal Tool Use
May 25, 2025Reinforcement Learning Finetuning (RFT) has significantly advanced the reasoning capabilities of large language models (LLMs) by enabling long chains of thought, self-correction, and effective tool use. While recent works attempt to extend RFT to vision-language models (VLMs), these efforts largely produce text-only reasoning conditioned on static image inputs, falling short of true multimodal reasoning in the response. In contrast, test-time methods like Visual Sketchpad incorporate visual steps but lack training mechanisms. We introduce VTool-R1, the first framework that trains VLMs to generate multimodal chains of thought by interleaving text and intermediate visual reasoning steps. VTool-R1 integrates Python-based visual editing tools into the RFT process, enabling VLMs to learn when and how to generate visual reasoning steps that benefit final reasoning. Trained with outcome-based rewards tied to task accuracy, our approach elicits strategic visual tool use for reasoning without relying on process-based supervision. Experiments on structured visual question answering over charts and tables show that VTool-R1 enhances reasoning performance by teaching VLMs to "think with images" and generate multimodal chain of thoughts with tools.
ACT360: An Efficient 360-Degree Action Detection and Summarization Framework for Mission-Critical Training and Debriefing
Mar 17, 2025
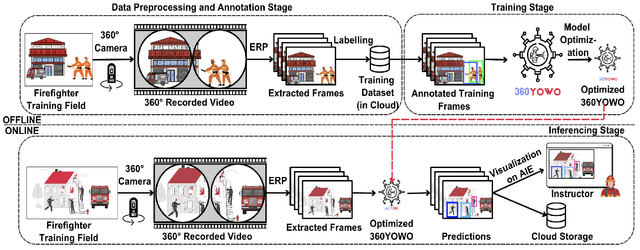
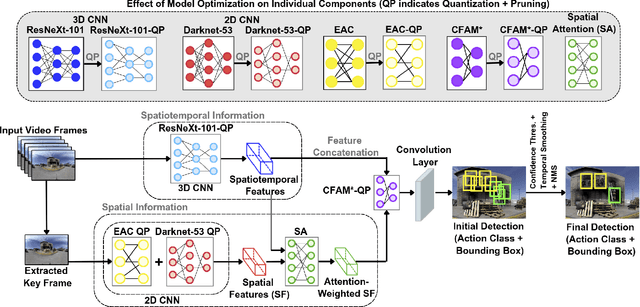
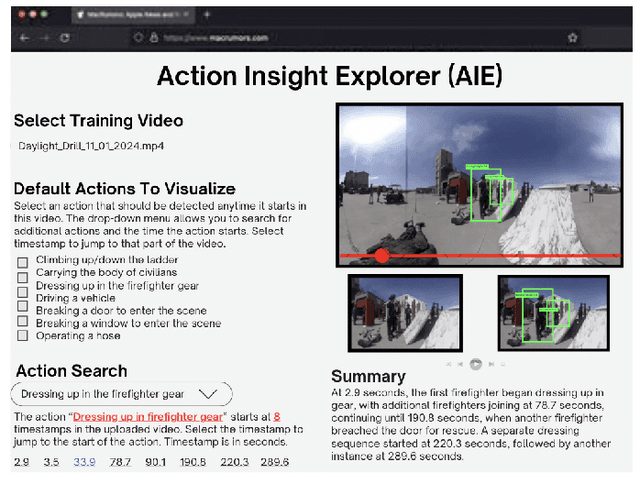
Effective training and debriefing are critical in high-stakes, mission-critical environments such as disaster response, military simulations, and industrial safety, where precision and minimizing errors are paramount. The traditional post-training analysis relies on manually reviewing 2D videos, a time-consuming process that lacks comprehensive situational awareness. To address these limitations, we introduce ACT360, a system that leverages 360-degree videos and machine learning for automated action detection and structured debriefing. ACT360 integrates 360YOWO, an enhanced You Only Watch Once (YOWO) model with spatial attention and equirectangular-aware convolution (EAC) to mitigate panoramic video distortions. To enable deployment in resource-constrained environments, we apply quantization and model pruning, reducing the model size by 74% while maintaining robust accuracy (mAP drop of only 1.5%, from 0.865 to 0.850) and improving inference speed. We validate our approach on a publicly available dataset of 55 labeled 360-degree videos covering seven key operational actions, recorded across various real-world training sessions and environmental conditions. Additionally, ACT360 integrates 360AIE (Action Insight Explorer), a web-based interface for automatic action detection, retrieval, and textual summarization using large language models (LLMs), significantly enhancing post-incident analysis efficiency. ACT360 serves as a generalized framework for mission-critical debriefing, incorporating EAC, spatial attention, summarization, and model optimization. These innovations apply to any training environment requiring lightweight action detection and structured post-exercise analysis.
Generative Active Adaptation for Drifting and Imbalanced Network Intrusion Detection
Mar 04, 2025



Machine learning has shown promise in network intrusion detection systems, yet its performance often degrades due to concept drift and imbalanced data. These challenges are compounded by the labor-intensive process of labeling network traffic, especially when dealing with evolving and rare attack types, which makes selecting the right data for adaptation difficult. To address these issues, we propose a generative active adaptation framework that minimizes labeling effort while enhancing model robustness. Our approach employs density-aware active sampling to identify the most informative samples for annotation and leverages deep generative models to synthesize diverse samples, thereby augmenting the training set and mitigating the effects of concept drift. We evaluate our end-to-end framework on both simulated IDS data and a real-world ISP dataset, demonstrating significant improvements in intrusion detection performance. Our method boosts the overall F1-score from 0.60 (without adaptation) to 0.86. Rare attacks such as Infiltration, Web Attack, and FTP-BruteForce, which originally achieve F1 scores of 0.001, 0.04, and 0.00, improve to 0.30, 0.50, and 0.71, respectively, with generative active adaptation in the CIC-IDS 2018 dataset. Our framework effectively enhances rare attack detection while reducing labeling costs, making it a scalable and adaptive solution for real-world intrusion detection.