 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceNet: Segment one thing efficiently
Jun 21, 2024
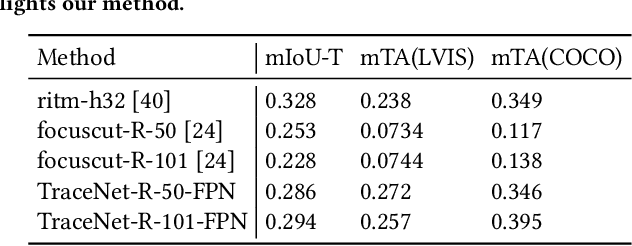
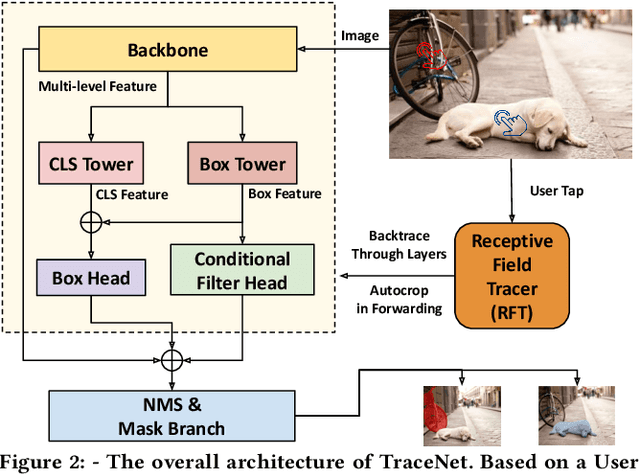

Efficient single instance segmentation is essential for unlocking features in the mobile imaging applications, such as capture or editing. Existing on-the-fly mobile imaging applications scope the segmentation task to portraits or the salient subject due to the computational constraints. Instance segmentation, despite its recent developments towards efficient networks, is still heavy due to the cost of computation on the entire image to identify all instances. To address this, we propose and formulate a one tap driven single instance segmentation task that segments a single instance selected by a user via a positive tap. This task, in contrast to the broader task of segmenting anything as suggested in the Segment Anything Model \cite{sam}, focuses on efficient segmentation of a single instance specified by the user. To solve this problem, we present TraceNet, which explicitly locates the selected instance by way of receptive field tracing. TraceNet identifies image regions that are related to the user tap and heavy computations are only performed on selected regions of the image. Therefore overall computation cost and memory consumption are reduced during inference. We evaluate the performance of TraceNet on instance IoU average over taps and the proportion of the region that a user tap can fall into for a high-quality single-instance mask. Experimental results on MS-COCO and LVIS demonstrate the effectiveness and efficiency of the proposed approach. TraceNet can jointly achieve the efficiency and interactivity, filling in the gap between needs for efficient mobile inference and recent research trend towards multimodal and interactive segmentation models.
FedCore: Straggler-Free Federated Learning with Distributed Coresets
Jan 31, 2024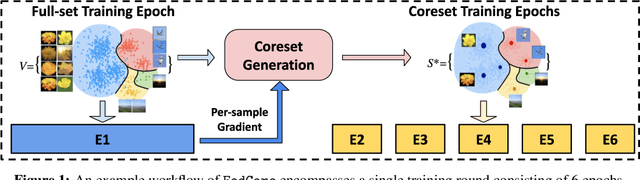

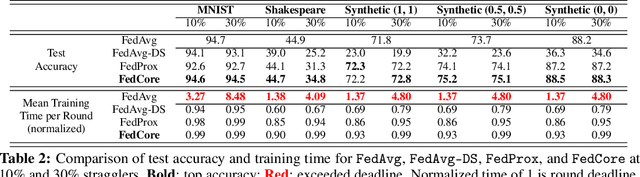
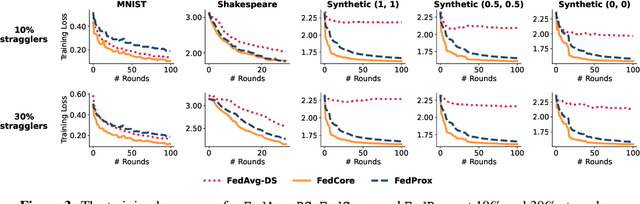
Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model while keeping their data on-premise. However, the straggler issue, due to slow clients, often hinders the efficiency and scalability of FL. This paper presents FedCore, an algorithm that innovatively tackles the straggler problem via the decentralized selection of coresets, representative subsets of a dataset. Contrary to existing centralized coreset methods, FedCore creates coresets directly on each client in a distributed manner, ensuring privacy preservation in FL. FedCore translates the coreset optimization problem into a more tractable k-medoids clustering problem and operates distributedly on each client. Theoretical analysis confirms FedCore's convergence, and practical evaluations demonstrate an 8x reduction in FL training time, without compromising model accuracy. Our extensive evaluations also show that FedCore generalizes well to existing FL frameworks.
CrossRoI: Cross-camera Region of Interest Optimization for Efficient Real Time Video Analytics at Scale
May 13, 2021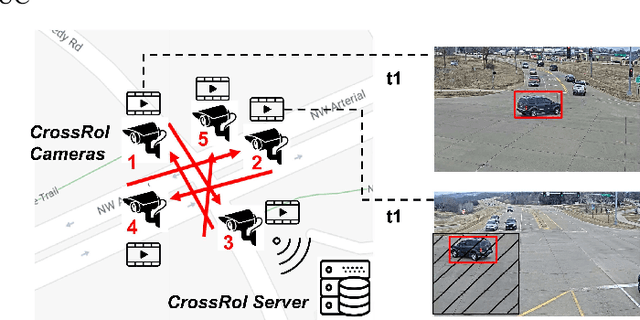
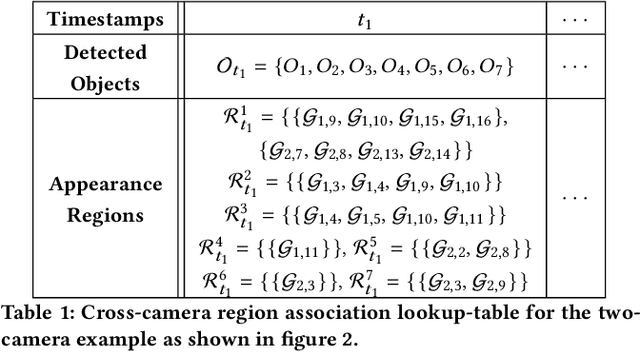
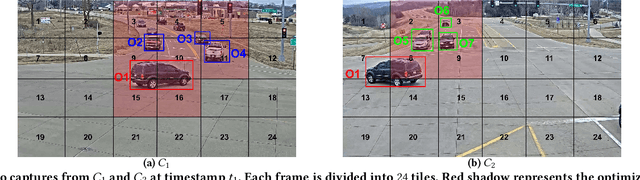
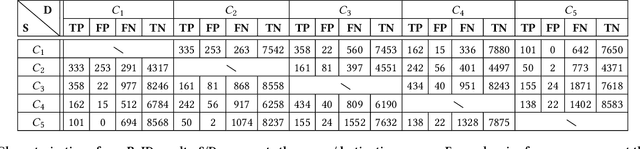
Video cameras are pervasively deployed in city scale for public good or community safety (i.e. traffic monitoring or suspected person tracking). However, analyzing large scale video feeds in real time is data intensive and poses severe challenges to network and computation systems today. We present CrossRoI, a resource-efficient system that enables real time video analytics at scale via harnessing the videos content associations and redundancy across a fleet of cameras. CrossRoI exploits the intrinsic physical correlations of cross-camera viewing fields to drastically reduce the communication and computation costs. CrossRoI removes the repentant appearances of same objects in multiple cameras without harming comprehensive coverage of the scene. CrossRoI operates in two phases - an offline phase to establish cross-camera correlations, and an efficient online phase for real time video inference. Experiments on real-world video feeds show that CrossRoI achieves 42% - 65% reduction for network overhead and 25% - 34% reduction for response delay in real time video analytics applications with more than 99% query accuracy, when compared to baseline methods. If integrated with SotA frame filtering systems, the performance gains of CrossRoI reach 50% - 80% (network overhead) and 33% - 61% (end-to-end delay).
DeepRT: A Soft Real Time Scheduler for Computer Vision Applications on the Edge
May 05, 2021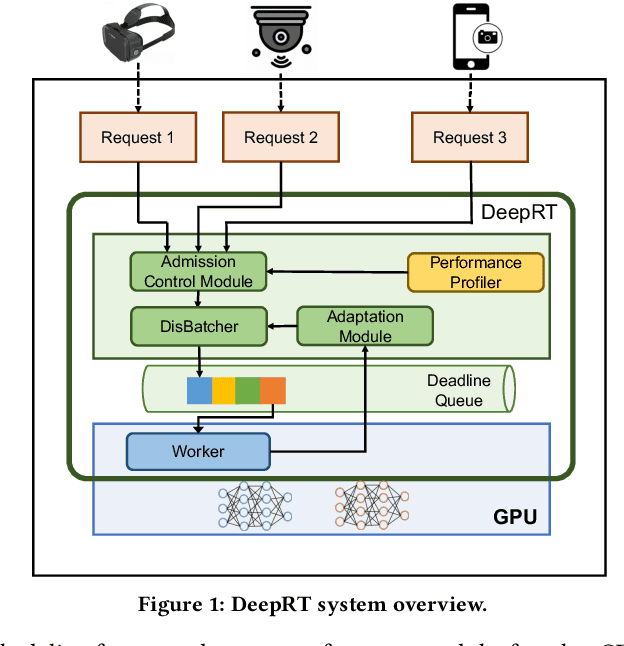
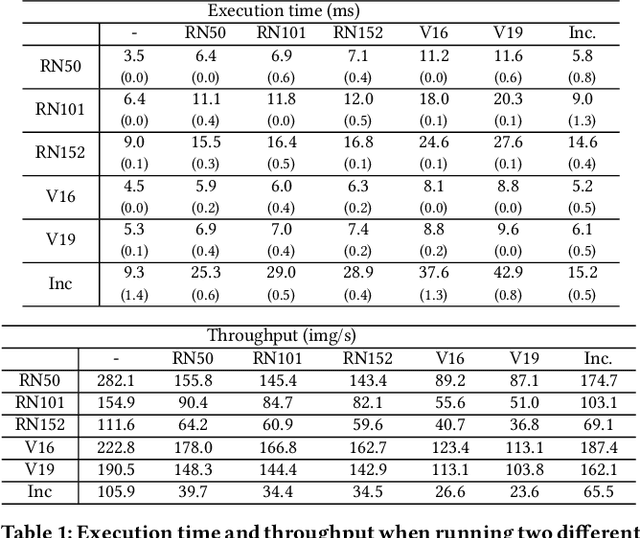
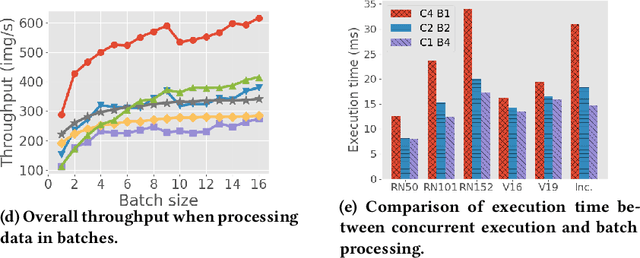
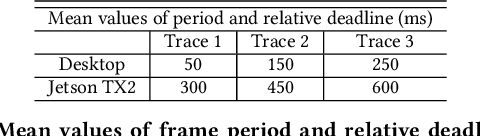
The ubiquity of smartphone cameras and IoT cameras, together with the recent boom of deep learning and deep neural networks, proliferate various computer vision driven mobile and IoT applications deployed on the edge. This paper focuses on applications which make soft real time requests to perform inference on their data - they desire prompt responses within designated deadlines, but occasional deadline misses are acceptable. Supporting soft real time applications on a multi-tenant edge server is not easy, since the requests sharing the limited GPU computing resources of an edge server interfere with each other. In order to tackle this problem, we comprehensively evaluate how latency and throughput respond to different GPU execution plans. Based on this analysis, we propose a GPU scheduler, DeepRT, which provides latency guarantee to the requests while maintaining high overall system throughput. The key component of DeepRT, DisBatcher, batches data from different requests as much as possible while it is proven to provide latency guarantee for requests admitted by an Admission Control Module. DeepRT also includes an Adaptation Module which tackles overruns. Our evaluation results show that DeepRT outperforms state-of-the-art works in terms of the number of deadline misses and throughput.