 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartVerse: Scaling Chart Reasoning via Reliable Programmatic Synthesis from Scratch
Jan 20, 2026Chart reasoning is a critical capability for Vision Language Models (VLMs). However, the development of open-source models is severely hindered by the lack of high-quality training data. Existing datasets suffer from a dual challenge: synthetic charts are often simplistic and repetitive, while the associated QA pairs are prone to hallucinations and lack the reasoning depth required for complex tasks. To bridge this gap, we propose ChartVerse, a scalable framework designed to synthesize complex charts and reliable reasoning data from scratch. (1) To address the bottleneck of simple patterns, we first introduce Rollout Posterior Entropy (RPE), a novel metric that quantifies chart complexity. Guided by RPE, we develop complexity-aware chart coder to autonomously synthesize diverse, high-complexity charts via executable programs. (2) To guarantee reasoning rigor, we develop truth-anchored inverse QA synthesis. Diverging from standard generation, we adopt an answer-first paradigm: we extract deterministic answers directly from the source code, generate questions conditional on these anchors, and enforce strict consistency verification. To further elevate difficulty and reasoning depth, we filter samples based on model fail-rate and distill high-quality Chain-of-Thought (CoT) reasoning. We curate ChartVerse-SFT-600K and ChartVerse-RL-40K using Qwen3-VL-30B-A3B-Thinking as the teacher. Experimental results demonstrate that ChartVerse-8B achieves state-of-the-art performance, notably surpassing its teacher and rivaling the stronger Qwen3-VL-32B-Thinking.
PrivGemo: Privacy-Preserving Dual-Tower Graph Retrieval for Empowering LLM Reasoning with Memory Augmentation
Jan 13, 2026Knowledge graphs (KGs) provide structured evidence that can ground large language model (LLM) reasoning for knowledge-intensive question answering. However, many practical KGs are private, and sending retrieved triples or exploration traces to closed-source LLM APIs introduces leakage risk. Existing privacy treatments focus on masking entity names, but they still face four limitations: structural leakage under semantic masking, uncontrollable remote interaction, fragile multi-hop and multi-entity reasoning, and limited experience reuse for stability and efficiency. To address these issues, we propose PrivGemo, a privacy-preserving retrieval-augmented framework for KG-grounded reasoning with memory-guided exposure control. PrivGemo uses a dual-tower design to keep raw KG knowledge local while enabling remote reasoning over an anonymized view that goes beyond name masking to limit both semantic and structural exposure. PrivGemo supports multi-hop, multi-entity reasoning by retrieving anonymized long-hop paths that connect all topic entities, while keeping grounding and verification on the local KG. A hierarchical controller and a privacy-aware experience memory further reduce unnecessary exploration and remote interactions. Comprehensive experiments on six benchmarks show that PrivGemo achieves overall state-of-the-art results, outperforming the strongest baseline by up to 17.1%. Furthermore, PrivGemo enables smaller models (e.g., Qwen3-4B) to achieve reasoning performance comparable to that of GPT-4-Turbo.
A Versatile Multimodal Agent for Multimedia Content Generation
Jan 06, 2026With the advancement of AIGC (AI-generated content) technologies, an increasing number of generative models are revolutionizing fields such as video editing, music generation, and even film production. However, due to the limitations of current AIGC models, most models can only serve as individual components within specific application scenarios and are not capable of completing tasks end-to-end in real-world applications. In real-world applications, editing experts often work with a wide variety of images and video inputs, producing multimodal outputs -- a video typically includes audio, text, and other elements. This level of integration across multiple modalities is something current models are unable to achieve effectively. However, the rise of agent-based systems has made it possible to use AI tools to tackle complex content generation tasks. To deal with the complex scenarios, in this paper, we propose a MultiMedia-Agent designed to automate complex content creation. Our agent system includes a data generation pipeline, a tool library for content creation, and a set of metrics for evaluating preference alignment. Notably, we introduce the skill acquisition theory to model the training data curation and agent training. We designed a two-stage correlation strategy for plan optimization, including self-correlation and model preference correlation. Additionally, we utilized the generated plans to train the MultiMedia-Agent via a three stage approach including base/success plan finetune and preference optimization. The comparison results demonstrate that the our approaches are effective and the MultiMedia-Agent can generate better multimedia content compared to novel models.
Beyond Homophily: Community Search on Heterophilic Graphs
Jan 05, 2026Community search aims to identify a refined set of nodes that are most relevant to a given query, supporting tasks ranging from fraud detection to recommendation. Unlike homophilic graphs, many real-world networks are heterophilic, where edges predominantly connect dissimilar nodes. Therefore, structural signals that once reflected smooth, low-frequency similarity now appear as sharp, high-frequency contrasts. However, both classical algorithms (e.g., k-core, k-truss) and recent ML-based models struggle to achieve effective community search on heterophilic graphs, where edge signs or semantics are generally unknown. Algorithm-based methods often return communities with mixed class labels, while GNNs, built on homophily, smooth away meaningful signals and blur community boundaries. Therefore, we propose Adaptive Community Search (AdaptCS), a unified framework featuring three key designs: (i) an AdaptCS Encoder that disentangles multi-hop and multi-frequency signals, enabling the model to capture both smooth (homophilic) and contrastive (heterophilic) relations; (ii) a memory-efficient low-rank optimization that removes the main computational bottleneck and ensures model scalability; and (iii) an Adaptive Community Score (ACS) that guides online search by balancing embedding similarity and topological relations. Extensive experiments on both heterophilic and homophilic benchmarks demonstrate that AdaptCS outperforms the best-performing baseline by an average of 11% in F1-score, retains robustness across heterophily levels, and achieves up to 2 orders of magnitude speedup.
GPF-Net: Gated Progressive Fusion Learning for Polyp Re-Identification
Dec 25, 2025Colonoscopic Polyp Re-Identification aims to match the same polyp from a large gallery with images from different views taken using different cameras, which plays an important role in the prevention and treatment of colorectal cancer in computer-aided diagnosis. However, the coarse resolution of high-level features of a specific polyp often leads to inferior results for small objects where detailed information is important. To address this challenge, we propose a novel architecture, named Gated Progressive Fusion network, to selectively fuse features from multiple levels using gates in a fully connected way for polyp ReID. On the basis of it, a gated progressive fusion strategy is introduced to achieve layer-wise refinement of semantic information through multi-level feature interactions. Experiments on standard benchmarks show the benefits of the multimodal setting over state-of-the-art unimodal ReID models, especially when combined with the specialized multimodal fusion strategy.
OpenDataArena: A Fair and Open Arena for Benchmarking Post-Training Dataset Value
Dec 16, 2025
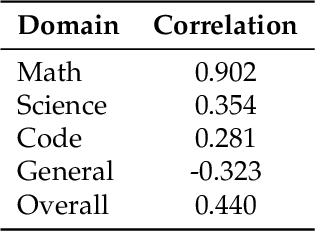
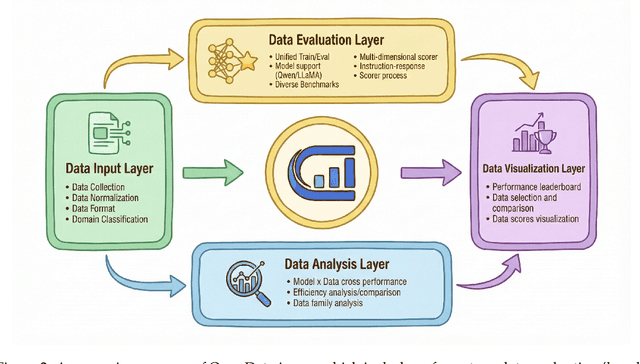

The rapid evolution of Large Language Models (LLMs) is predicated on the quality and diversity of post-training datasets. However, a critical dichotomy persists: while models are rigorously benchmarked, the data fueling them remains a black box--characterized by opaque composition, uncertain provenance, and a lack of systematic evaluation. This opacity hinders reproducibility and obscures the causal link between data characteristics and model behaviors. To bridge this gap, we introduce OpenDataArena (ODA), a holistic and open platform designed to benchmark the intrinsic value of post-training data. ODA establishes a comprehensive ecosystem comprising four key pillars: (i) a unified training-evaluation pipeline that ensures fair, open comparisons across diverse models (e.g., Llama, Qwen) and domains; (ii) a multi-dimensional scoring framework that profiles data quality along tens of distinct axes; (iii) an interactive data lineage explorer to visualize dataset genealogy and dissect component sources; and (iv) a fully open-source toolkit for training, evaluation, and scoring to foster data research. Extensive experiments on ODA--covering over 120 training datasets across multiple domains on 22 benchmarks, validated by more than 600 training runs and 40 million processed data points--reveal non-trivial insights. Our analysis uncovers the inherent trade-offs between data complexity and task performance, identifies redundancy in popular benchmarks through lineage tracing, and maps the genealogical relationships across datasets. We release all results, tools, and configurations to democratize access to high-quality data evaluation. Rather than merely expanding a leaderboard, ODA envisions a shift from trial-and-error data curation to a principled science of Data-Centric AI, paving the way for rigorous studies on data mixing laws and the strategic composition of foundation models.
Revealing the dynamic responses of Pb under shock loading based on DFT-accuracy machine learning potential
Nov 17, 2025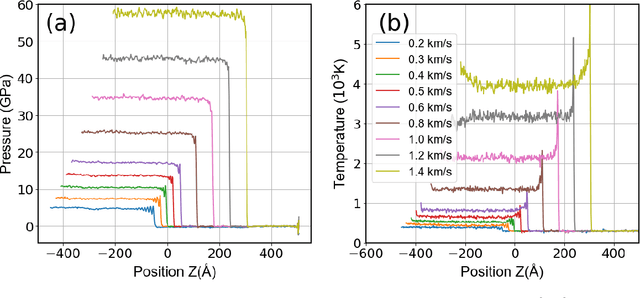
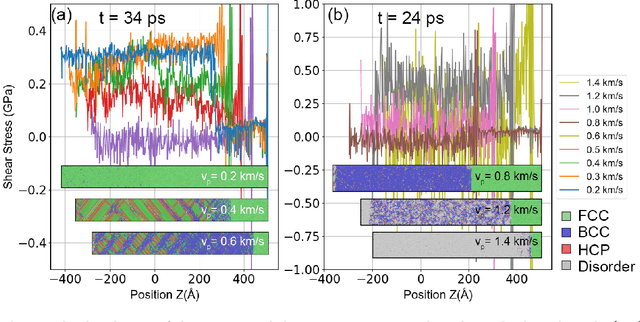
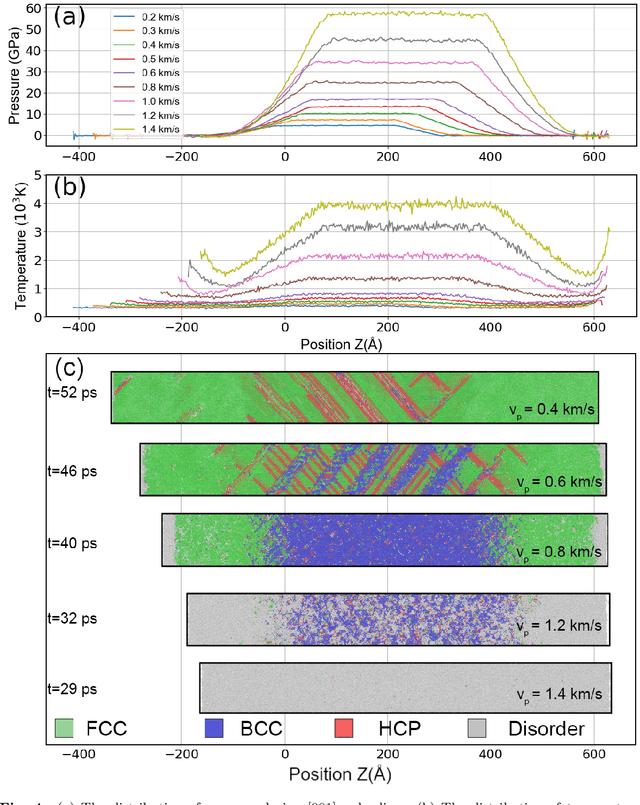
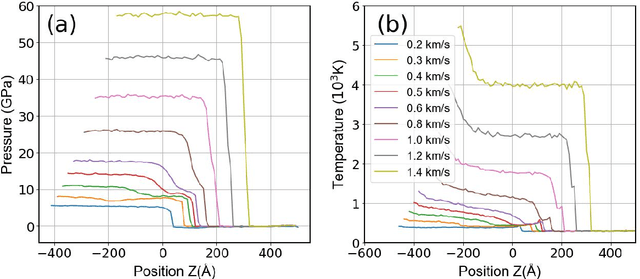
Lead (Pb) is a typical low-melting-point ductile metal and serves as an important model material in the study of dynamic responses. Under shock-wave loading, its dynamic mechanical behavior comprises two key phenomena: plastic deformation and shock induced phase transitions. The underlying mechanisms of these processes are still poorly understood. Revealing these mechanisms remains challenging for experimental approaches. Non-equilibrium molecular dynamics (NEMD) simulations are an alternative theoretical tool for studying dynamic responses, as they capture atomic-scale mechanisms such as defect evolution and deformation pathways. However, due to the limited accuracy of empirical interatomic potentials, the reliability of previous NEMD studies is questioned. Using our newly developed machine learning potential for Pb-Sn alloys, we revisited the microstructure evolution in response to shock loading under various shock orientations. The results reveal that shock loading along the [001] orientation of Pb exhibits a fast, reversible, and massive phase transition and stacking fault evolution. The behavior of Pb differs from previous studies by the absence of twinning during plastic deformation. Loading along the [011] orientation leads to slow, irreversible plastic deformation, and a localized FCC-BCC phase transition in the Pitsch orientation relationship. This study provides crucial theoretical insights into the dynamic mechanical response of Pb, offering a theoretical input for understanding the microstructure-performance relationship under extreme conditions.
PRoH: Dynamic Planning and Reasoning over Knowledge Hypergraphs for Retrieval-Augmented Generation
Oct 14, 2025Knowledge Hypergraphs (KHs) have recently emerged as a knowledge representation for retrieval-augmented generation (RAG), offering a paradigm to model multi-entity relations into a structured form. However, existing KH-based RAG methods suffer from three major limitations: static retrieval planning, non-adaptive retrieval execution, and superficial use of KH structure and semantics, which constrain their ability to perform effective multi-hop question answering. To overcome these limitations, we propose PRoH, a dynamic Planning and Reasoning over Knowledge Hypergraphs framework. PRoH incorporates three core innovations: (i) a context-aware planning module that sketches the local KH neighborhood to guide structurally grounded reasoning plan generation; (ii) a structured question decomposition process that organizes subquestions as a dynamically evolving Directed Acyclic Graph (DAG) to enable adaptive, multi-trajectory exploration; and (iii) an Entity-Weighted Overlap (EWO)-guided reasoning path retrieval algorithm that prioritizes semantically coherent hyperedge traversals. Experiments across multiple domains demonstrate that PRoH achieves state-of-the-art performance, surpassing the prior SOTA model HyperGraphRAG by an average of 19.73% in F1 and 8.41% in Generation Evaluation (G-E) score, while maintaining strong robustness in long-range multi-hop reasoning tasks.
Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
Sep 09, 2025Parallel thinking has emerged as a novel approach for enhancing the reasoning capabilities of large language models (LLMs) by exploring multiple reasoning paths concurrently. However, activating such capabilities through training remains challenging, as existing methods predominantly rely on supervised fine-tuning (SFT) over synthetic data, which encourages teacher-forced imitation rather than exploration and generalization. Different from them, we propose \textbf{Parallel-R1}, the first reinforcement learning (RL) framework that enables parallel thinking behaviors for complex real-world reasoning tasks. Our framework employs a progressive curriculum that explicitly addresses the cold-start problem in training parallel thinking with RL. We first use SFT on prompt-generated trajectories from easier tasks to instill the parallel thinking ability, then transition to RL to explore and generalize this skill on harder problems. Experiments on various math benchmarks, including MATH, AMC23, and AIME, show that Parallel-R1 successfully instills parallel thinking, leading to 8.4% accuracy improvements over the sequential thinking model trained directly on challenging tasks with RL. Further analysis reveals a clear shift in the model's thinking behavior: at an early stage, it uses parallel thinking as an exploration strategy, while in a later stage, it uses the same capability for multi-perspective verification. Most significantly, we validate parallel thinking as a \textbf{mid-training exploration scaffold}, where this temporary exploratory phase unlocks a higher performance ceiling after RL, yielding a 42.9% improvement over the baseline on AIME25. Our model, data, and code will be open-source at https://github.com/zhengkid/Parallel-R1.
Automated Clinical Problem Detection from SOAP Notes using a Collaborative Multi-Agent LLM Architecture
Aug 29, 2025



Accurate interpretation of clinical narratives is critical for patient care, but the complexity of these notes makes automation challenging. While Large Language Models (LLMs) show promise, single-model approaches can lack the robustness required for high-stakes clinical tasks. We introduce a collaborative multi-agent system (MAS) that models a clinical consultation team to address this gap. The system is tasked with identifying clinical problems by analyzing only the Subjective (S) and Objective (O) sections of SOAP notes, simulating the diagnostic reasoning process of synthesizing raw data into an assessment. A Manager agent orchestrates a dynamically assigned team of specialist agents who engage in a hierarchical, iterative debate to reach a consensus. We evaluated our MAS against a single-agent baseline on a curated dataset of 420 MIMIC-III notes. The dynamic multi-agent configuration demonstrated consistently improved performance in identifying congestive heart failure, acute kidney injury, and sepsis. Qualitative analysis of the agent debates reveals that this structure effectively surfaces and weighs conflicting evidence, though it can occasionally be susceptible to groupthink. By modeling a clinical team's reasoning process, our system offers a promising path toward more accurate, robust, and interpretable clinical decision support tools.