 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-AI Agent Framework Reveals the "Oxide Gatekeeper" in Aluminum Nanoparticle Oxidation
Dec 27, 2025Aluminum nanoparticles (ANPs) are among the most energy-dense solid fuels, yet the atomic mechanisms governing their transition from passivated particles to explosive reactants remain elusive. This stems from a fundamental computational bottleneck: ab initio methods offer quantum accuracy but are restricted to small spatiotemporal scales (< 500 atoms, picoseconds), while empirical force fields lack the reactive fidelity required for complex combustion environments. Herein, we bridge this gap by employing a "human-in-the-loop" closed-loop framework where self-auditing AI Agents validate the evolution of a machine learning potential (MLP). By acting as scientific sentinels that visualize hidden model artifacts for human decision-making, this collaborative cycle ensures quantum mechanical accuracy while exhibiting near-linear scalability to million-atom systems and accessing nanosecond timescales (energy RMSE: 1.2 meV/atom, force RMSE: 0.126 eV/Angstrom). Strikingly, our simulations reveal a temperature-regulated dual-mode oxidation mechanism: at moderate temperatures, the oxide shell acts as a dynamic "gatekeeper," regulating oxidation through a "breathing mode" of transient nanochannels; above a critical threshold, a "rupture mode" unleashes catastrophic shell failure and explosive combustion. Importantly, we resolve a decades-old controversy by demonstrating that aluminum cation outward diffusion, rather than oxygen transport, dominates mass transfer across all temperature regimes, with diffusion coefficients consistently exceeding those of oxygen by 2-3 orders of magnitude. These discoveries establish a unified atomic-scale framework for energetic nanomaterial design, enabling the precision engineering of ignition sensitivity and energy release rates through intelligent computational design.
Deconstructing the Dual Black Box:A Plug-and-Play Cognitive Framework for Human-AI Collaborative Enhancement and Its Implications for AI Governance
Dec 09, 2025Currently, there exists a fundamental divide between the "cognitive black box" (implicit intuition) of human experts and the "computational black box" (untrustworthy decision-making) of artificial intelligence (AI). This paper proposes a new paradigm of "human-AI collaborative cognitive enhancement," aiming to transform the dual black boxes into a composable, auditable, and extensible "functional white-box" system through structured "meta-interaction." The core breakthrough lies in the "plug-and-play cognitive framework"--a computable knowledge package that can be extracted from expert dialogues and loaded into the Recursive Adversarial Meta-Thinking Network (RAMTN). This enables expert thinking, such as medical diagnostic logic and teaching intuition, to be converted into reusable and scalable public assets, realizing a paradigm shift from "AI as a tool" to "AI as a thinking partner." This work not only provides the first engineering proof for "cognitive equity" but also opens up a new path for AI governance: constructing a verifiable and intervenable governance paradigm through "transparency of interaction protocols" rather than prying into the internal mechanisms of models. The framework is open-sourced to promote technology for good and cognitive inclusion. This paper is an independent exploratory research conducted by the author. All content presented, including the theoretical framework (RAMTN), methodology (meta-interaction), system implementation, and case validation, constitutes the author's individual research achievements.
Systematic Analysis of LLM Contributions to Planning: Solver, Verifier, Heuristic
Dec 12, 2024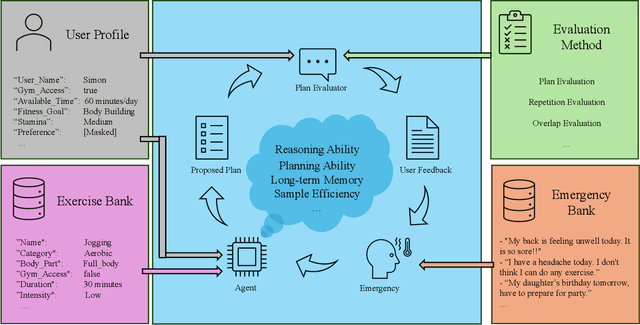
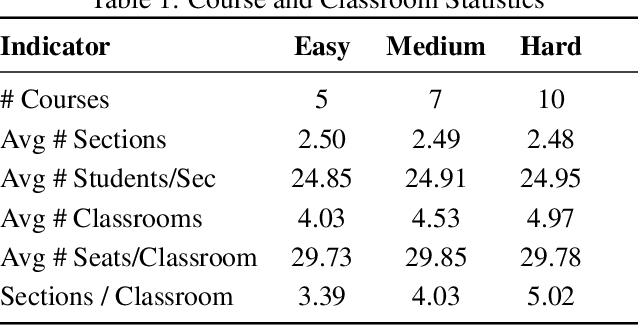
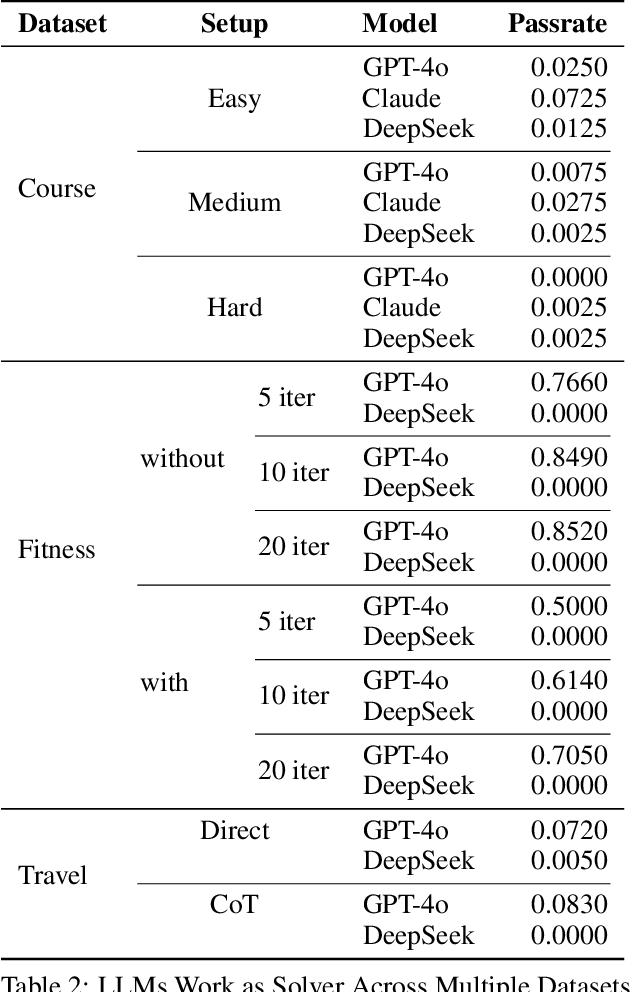
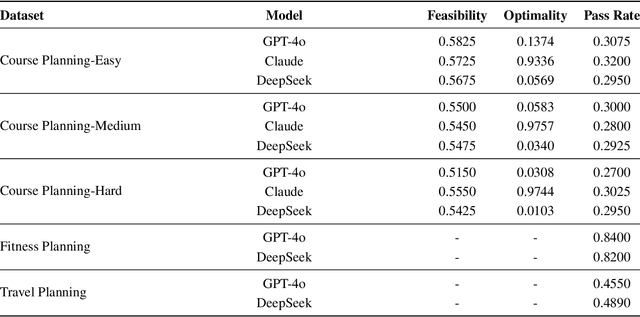
In this work, we provide a systematic analysis of how large language models (LLMs) contribute to solving planning problems. In particular, we examine how LLMs perform when they are used as problem solver, solution verifier, and heuristic guidance to improve intermediate solutions. Our analysis reveals that although it is difficult for LLMs to generate correct plans out-of-the-box, LLMs are much better at providing feedback signals to intermediate/incomplete solutions in the form of comparative heuristic functions. This evaluation framework provides insights into how future work may design better LLM-based tree-search algorithms to solve diverse planning and reasoning problems. We also propose a novel benchmark to evaluate LLM's ability to learn user preferences on the fly, which has wide applications in practical settings.
STRUX: An LLM for Decision-Making with Structured Explanations
Oct 16, 2024Countless decisions shape our daily lives, and it is paramount to understand the how and why behind these choices. In this paper, we introduce a new LLM decision-making framework called STRUX, which enhances LLM decision-making by providing structured explanations. These include favorable and adverse facts related to the decision, along with their respective strengths. STRUX begins by distilling lengthy information into a concise table of key facts. It then employs a series of self-reflection steps to determine which of these facts are pivotal, categorizing them as either favorable or adverse in relation to a specific decision. Lastly, we fine-tune an LLM to identify and prioritize these key facts to optimize decision-making. STRUX has been evaluated on the challenging task of forecasting stock investment decisions based on earnings call transcripts and demonstrated superior performance against strong baselines. It enhances decision transparency by allowing users to understand the impact of different factors, representing a meaningful step towards practical decision-making with LLMs.
DeFine: Enhancing LLM Decision-Making with Factor Profiles and Analogical Reasoning
Oct 02, 2024



LLMs are ideal for decision-making due to their ability to reason over long contexts and identify critical factors. However, challenges arise when processing transcripts of spoken speech describing complex scenarios. These transcripts often contain ungrammatical or incomplete sentences, repetitions, hedging, and vagueness. For example, during a company's earnings call, an executive might project a positive revenue outlook to reassure investors, despite significant uncertainty regarding future earnings. It is crucial for LLMs to incorporate this uncertainty systematically when making decisions. In this paper, we introduce DeFine, a new framework that constructs probabilistic factor profiles from complex scenarios. DeFine then integrates these profiles with analogical reasoning, leveraging insights from similar past experiences to guide LLMs in making critical decisions in novel situations. Our framework separates the tasks of quantifying uncertainty in complex scenarios and incorporating it into LLM decision-making. This approach is particularly useful in fields such as medical consultations, negotiations, and political debates, where making decisions under uncertainty is vital.
Rethinking Goal-conditioned Supervised Learning and Its Connection to Offline RL
Feb 14, 2022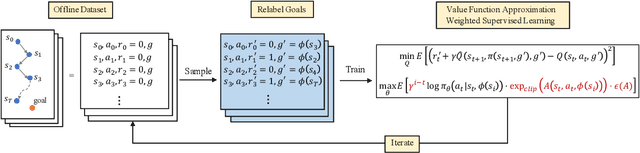

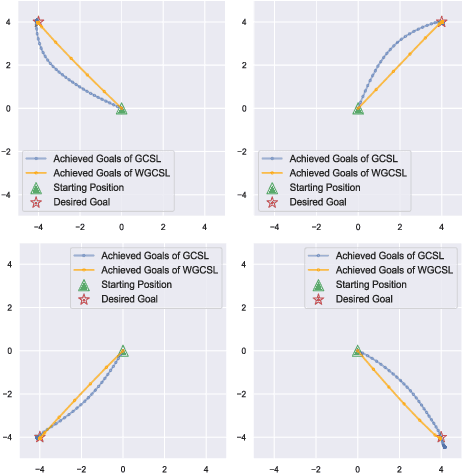
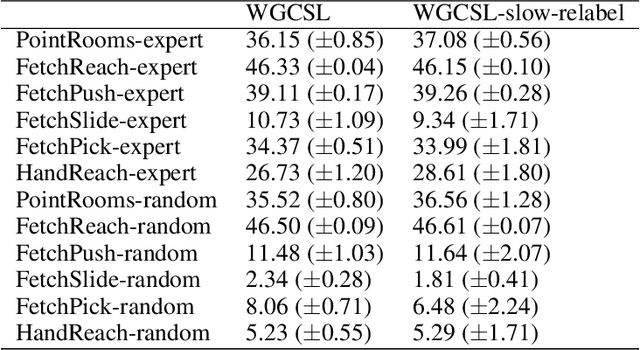
Solving goal-conditioned tasks with sparse rewards using self-supervised learning is promising because of its simplicity and stability over current reinforcement learning (RL) algorithms. A recent work, called Goal-Conditioned Supervised Learning (GCSL), provides a new learning framework by iteratively relabeling and imitating self-generated experiences. In this paper, we revisit the theoretical property of GCSL -- optimizing a lower bound of the goal reaching objective, and extend GCSL as a novel offline goal-conditioned RL algorithm. The proposed method is named Weighted GCSL (WGCSL), in which we introduce an advanced compound weight consisting of three parts (1) discounted weight for goal relabeling, (2) goal-conditioned exponential advantage weight, and (3) best-advantage weight. Theoretically, WGCSL is proved to optimize an equivalent lower bound of the goal-conditioned RL objective and generates monotonically improved policies via an iterated scheme. The monotonic property holds for any behavior policies, and therefore WGCSL can be applied to both online and offline settings. To evaluate algorithms in the offline goal-conditioned RL setting, we provide a benchmark including a range of point and simulated robot domains. Experiments in the introduced benchmark demonstrate that WGCSL can consistently outperform GCSL and existing state-of-the-art offline methods in the fully offline goal-conditioned setting.
SEIHAI: A Sample-efficient Hierarchical AI for the MineRL Competition
Nov 17, 2021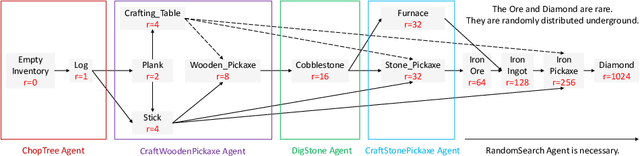
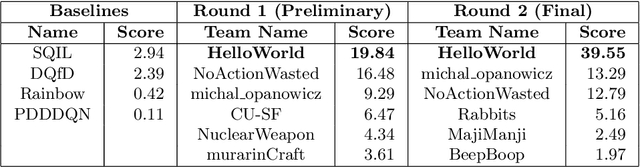

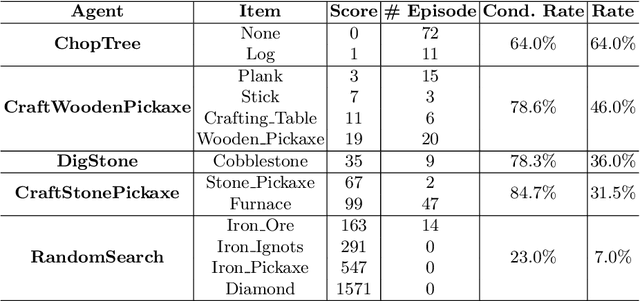
The MineRL competition is designed for the development of reinforcement learning and imitation learning algorithms that can efficiently leverage human demonstrations to drastically reduce the number of environment interactions needed to solve the complex \emph{ObtainDiamond} task with sparse rewards. To address the challenge, in this paper, we present \textbf{SEIHAI}, a \textbf{S}ample-\textbf{e}ff\textbf{i}cient \textbf{H}ierarchical \textbf{AI}, that fully takes advantage of the human demonstrations and the task structure. Specifically, we split the task into several sequentially dependent subtasks, and train a suitable agent for each subtask using reinforcement learning and imitation learning. We further design a scheduler to select different agents for different subtasks automatically. SEIHAI takes the first place in the preliminary and final of the NeurIPS-2020 MineRL competition.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021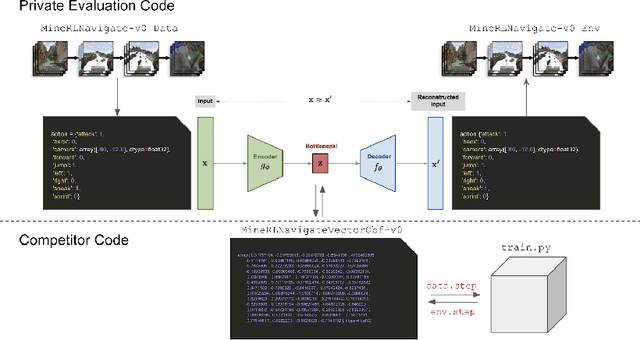

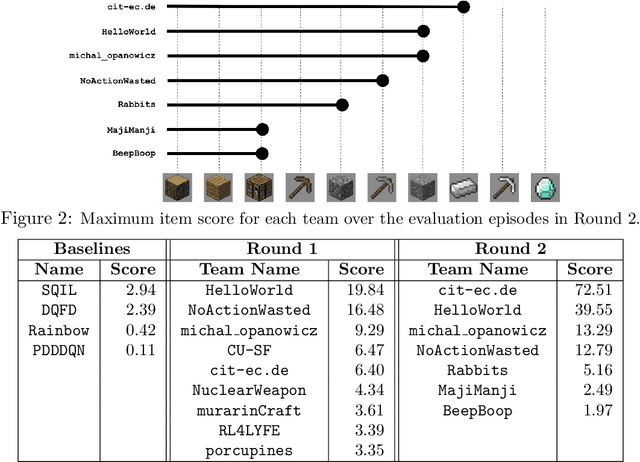
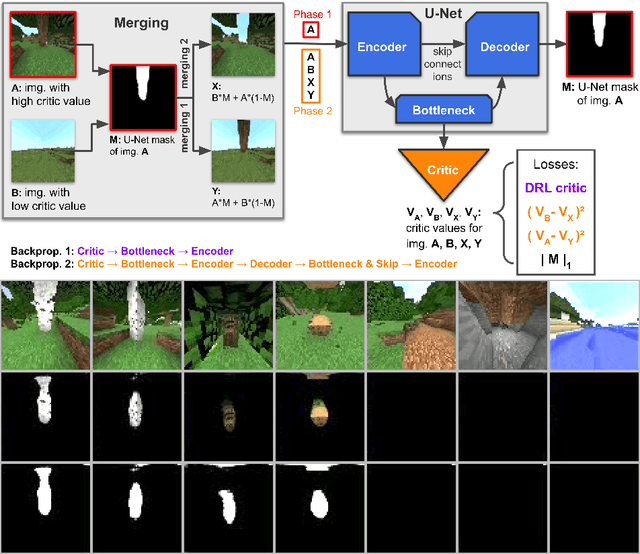
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.