 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMIC: Improving Multi-Agent Reinforcement Learning with Progressive Mutual Information Collaboration
Mar 16, 2022
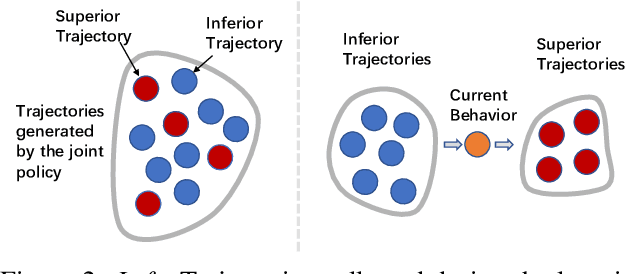
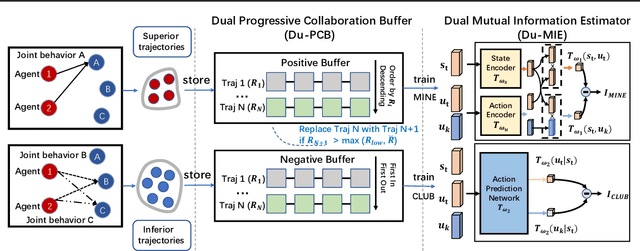
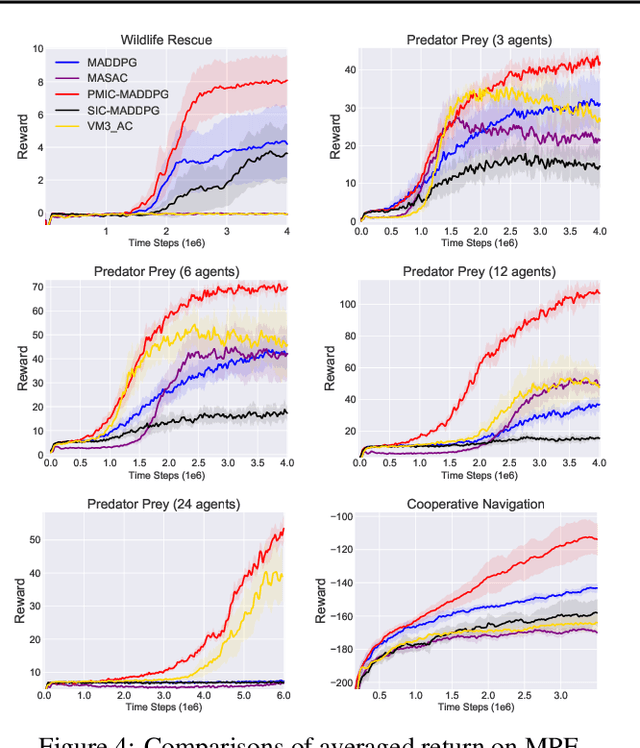
Learning to collaborate is critical in multi-agent reinforcement learning (MARL). A number of previous works promote collaboration by maximizing the correlation of agents' behaviors, which is typically characterised by mutual information (MI) in different forms. However, in this paper, we reveal that strong correlation can emerge from sub-optimal collaborative behaviors, and simply maximizing the MI can, surprisingly, hinder the learning towards better collaboration. To address this issue, we propose a novel MARL framework, called Progressive Mutual Information Collaboration (PMIC), for more effective MI-driven collaboration. In PMIC, we use a new collaboration criterion measured by the MI between global states and joint actions. Based on the criterion, the key idea of PMIC is maximizing the MI associated with superior collaborative behaviors and minimizing the MI associated with inferior ones. The two MI objectives play complementary roles by facilitating learning towards better collaborations while avoiding falling into sub-optimal ones. Specifically, PMIC stores and progressively maintains sets of superior and inferior interaction experiences, from which dual MI neural estimators are established. Experiments on a wide range of MARL benchmarks show the superior performance of PMIC compared with other algorithms.
API: Boosting Multi-Agent Reinforcement Learning via Agent-Permutation-Invariant Networks
Mar 10, 2022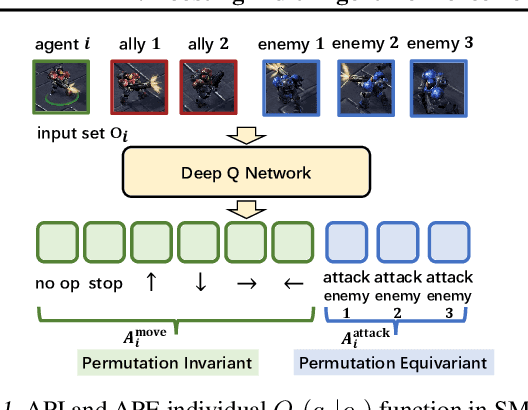
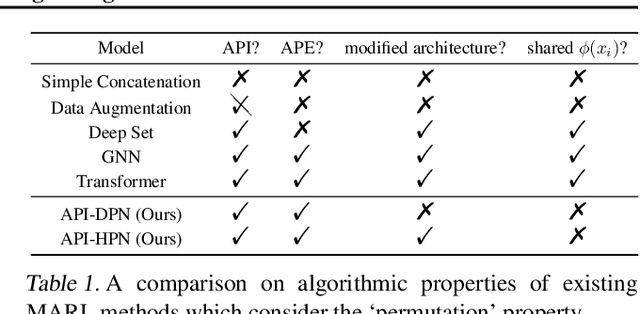
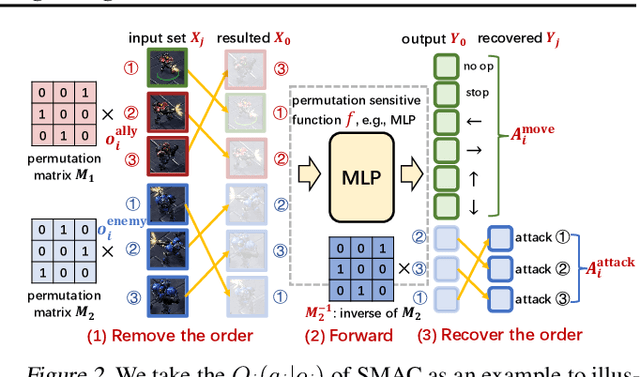
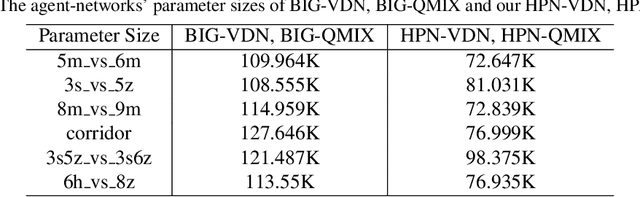
Multi-agent reinforcement learning suffers from poor sample efficiency due to the exponential growth of the state-action space. Considering a homogeneous multiagent system, a global state consisting of $m$ homogeneous components has $m!$ differently ordered representations, thus designing functions satisfying permutation invariant (PI) can reduce the state space by a factor of $\frac{1}{m!}$. However, mainstream MARL algorithms ignore this property and learn over the original state space. To achieve PI, previous works including data augmentation based methods and embedding-sharing architecture based methods, suffer from training instability and limited model capacity. In this work, we propose two novel designs to achieve PI, while avoiding the above limitations. The first design permutes the same but differently ordered inputs back to the same order and the downstream networks only need to learn function mapping over fixed-ordering inputs instead of all permutations, which is much easier to train. The second design applies a hypernetwork to generate customized embedding for each component, which has higher representational capacity than the previous embedding-sharing method. Empirical results on the SMAC benchmark show that the proposed method achieves 100% win-rates in almost all hard and super-hard scenarios (never achieved before), and superior sample-efficiency than the state-of-the-art baselines by up to 400%.
SEIHAI: A Sample-efficient Hierarchical AI for the MineRL Competition
Nov 17, 2021
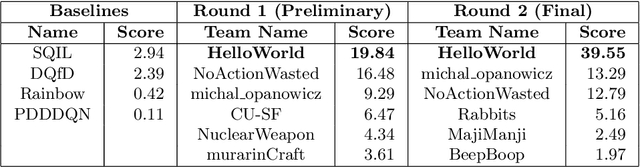

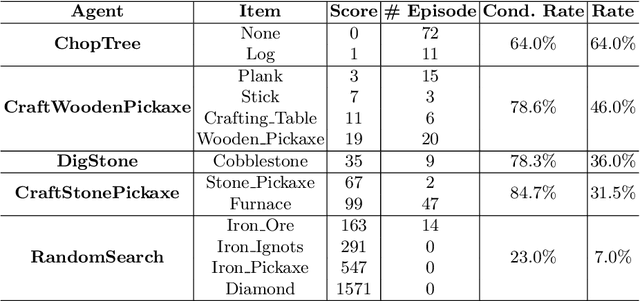
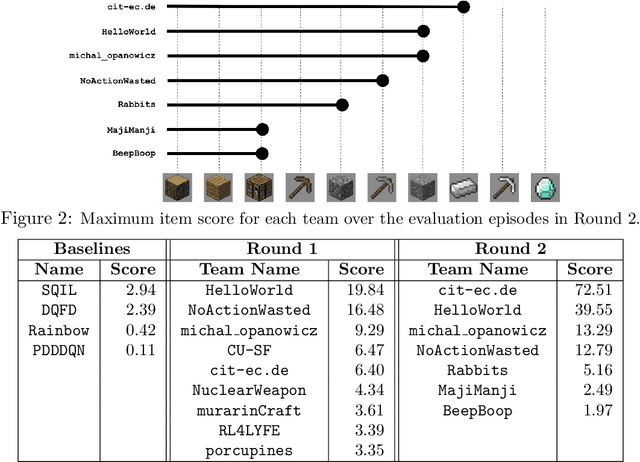
The MineRL competition is designed for the development of reinforcement learning and imitation learning algorithms that can efficiently leverage human demonstrations to drastically reduce the number of environment interactions needed to solve the complex \emph{ObtainDiamond} task with sparse rewards. To address the challenge, in this paper, we present \textbf{SEIHAI}, a \textbf{S}ample-\textbf{e}ff\textbf{i}cient \textbf{H}ierarchical \textbf{AI}, that fully takes advantage of the human demonstrations and the task structure. Specifically, we split the task into several sequentially dependent subtasks, and train a suitable agent for each subtask using reinforcement learning and imitation learning. We further design a scheduler to select different agents for different subtasks automatically. SEIHAI takes the first place in the preliminary and final of the NeurIPS-2020 MineRL competition.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021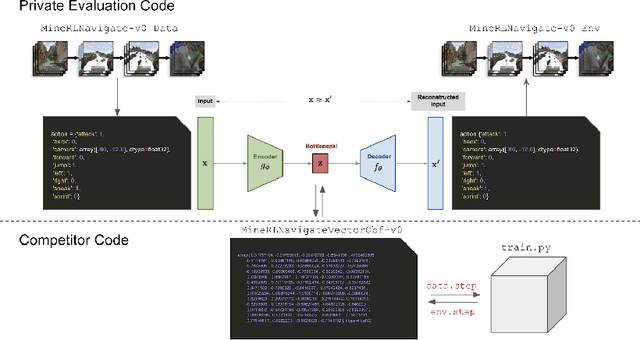

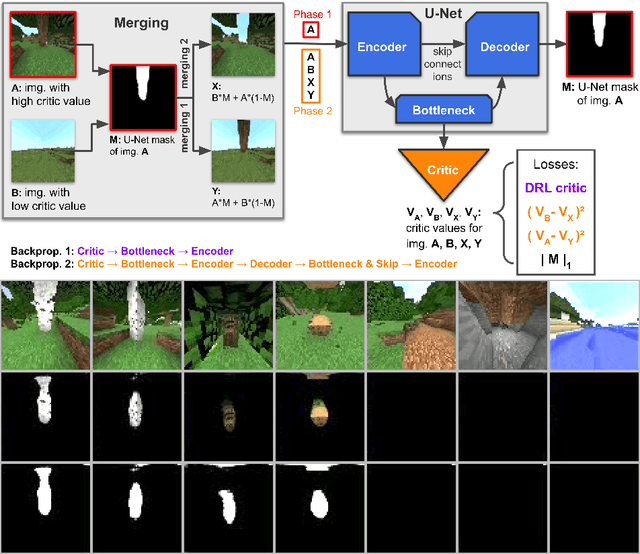
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Dynamic Knapsack Optimization Towards Efficient Multi-Channel Sequential Advertising
Jun 29, 2020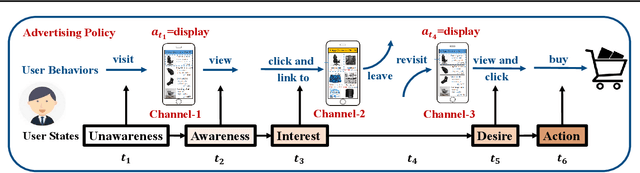
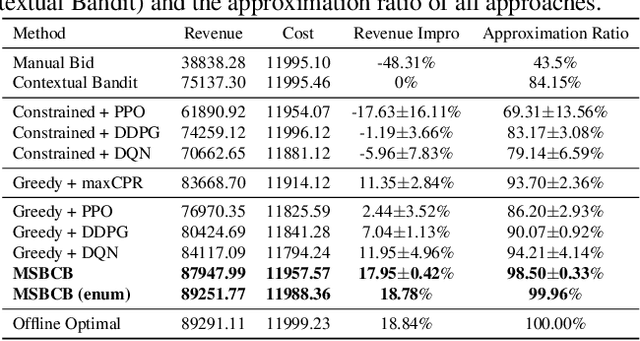
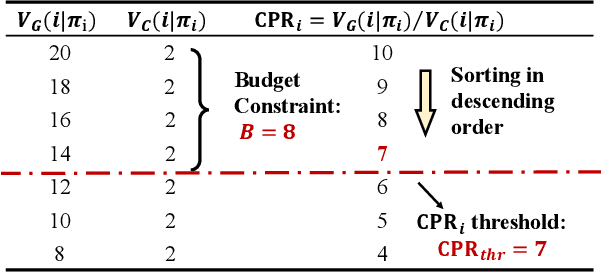
In E-commerce, advertising is essential for merchants to reach their target users. The typical objective is to maximize the advertiser's cumulative revenue over a period of time under a budget constraint. In real applications, an advertisement (ad) usually needs to be exposed to the same user multiple times until the user finally contributes revenue (e.g., places an order). However, existing advertising systems mainly focus on the immediate revenue with single ad exposures, ignoring the contribution of each exposure to the final conversion, thus usually falls into suboptimal solutions. In this paper, we formulate the sequential advertising strategy optimization as a dynamic knapsack problem. We propose a theoretically guaranteed bilevel optimization framework, which significantly reduces the solution space of the original optimization space while ensuring the solution quality. To improve the exploration efficiency of reinforcement learning, we also devise an effective action space reduction approach. Extensive offline and online experiments show the superior performance of our approaches over state-of-the-art baselines in terms of cumulative revenue.
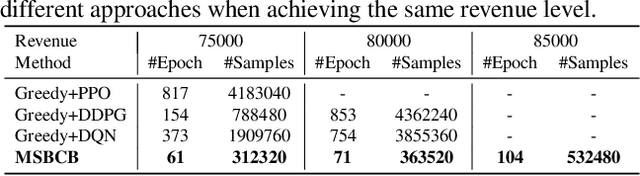
Learning to Accelerate Heuristic Searching for Large-Scale Maximum Weighted b-Matching Problems in Online Advertising
May 12, 2020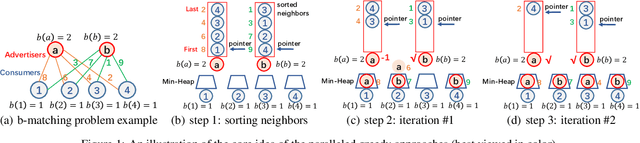
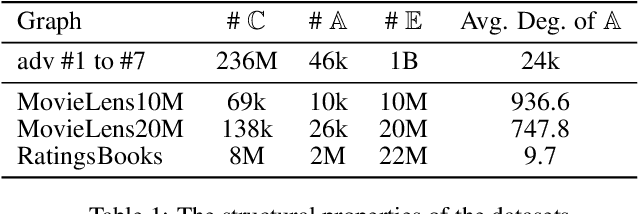
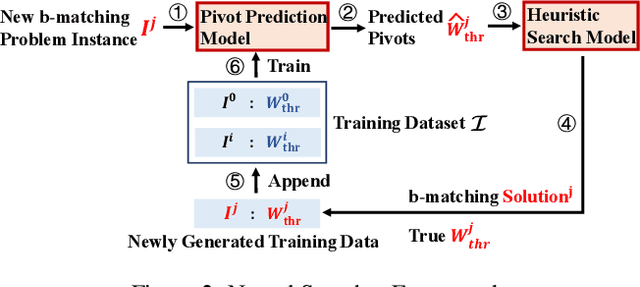

Bipartite b-matching is fundamental in algorithm design, and has been widely applied into economic markets, labor markets, etc. These practical problems usually exhibit two distinct features: large-scale and dynamic, which requires the matching algorithm to be repeatedly executed at regular intervals. However, existing exact and approximate algorithms usually fail in such settings due to either requiring intolerable running time or too much computation resource. To address this issue, we propose \texttt{NeuSearcher} which leverages the knowledge learned from previously instances to solve new problem instances. Specifically, we design a multichannel graph neural network to predict the threshold of the matched edges weights, by which the search region could be significantly reduced. We further propose a parallel heuristic search algorithm to iteratively improve the solution quality until convergence. Experiments on both open and industrial datasets demonstrate that \texttt{NeuSearcher} can speed up 2 to 3 times while achieving exactly the same matching solution compared with the state-of-the-art approximation approaches.
From Few to More: Large-scale Dynamic Multiagent Curriculum Learning
Sep 06, 2019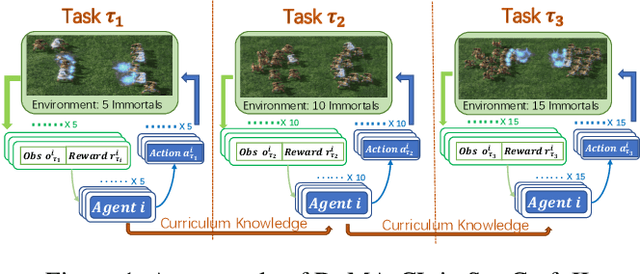
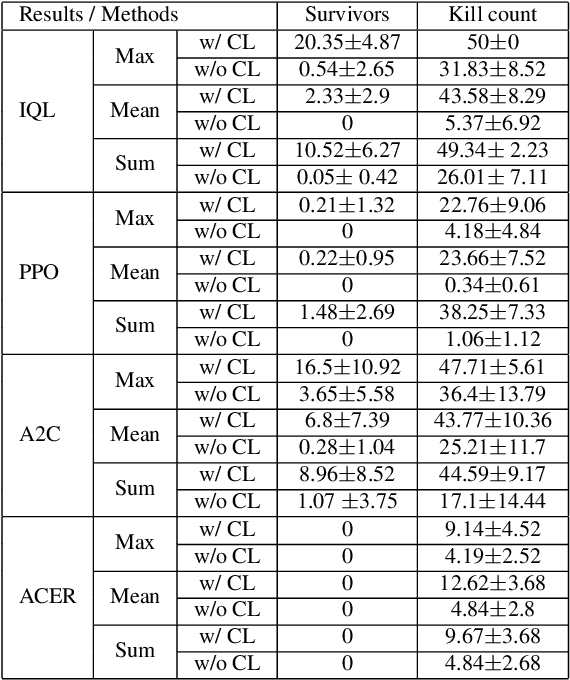
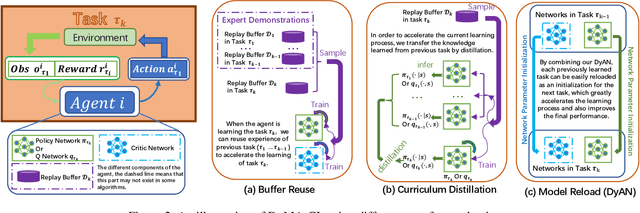

A lot of efforts have been devoted to investigating how agents can learn effectively and achieve coordination in multiagent systems. However, it is still challenging in large-scale multiagent settings due to the complex dynamics between the environment and agents and the explosion of state-action space. In this paper, we design a novel Dynamic Multiagent Curriculum Learning (DyMA-CL) to solve large-scale problems by starting from learning on a multiagent scenario with a small size and progressively increasing the number of agents. We propose three transfer mechanisms across curricula to accelerate the learning process. Moreover, due to the fact that the state dimension varies across curricula,, and existing network structures cannot be applied in such a transfer setting since their network input sizes are fixed. Therefore, we design a novel network structure called Dynamic Agent-number Network (DyAN) to handle the dynamic size of the network input. Experimental results show that DyMA-CL using DyAN greatly improves the performance of large-scale multiagent learning compared with state-of-the-art deep reinforcement learning approaches. We also investigate the influence of three transfer mechanisms across curricula through extensive simulations.
Action Semantics Network: Considering the Effects of Actions in Multiagent Systems
Jul 26, 2019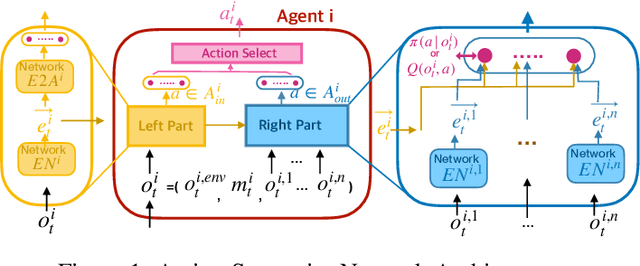
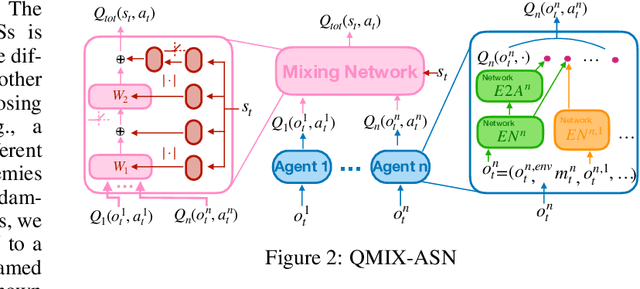

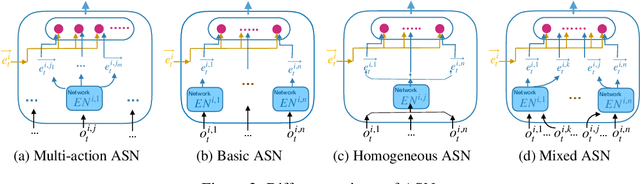
In multiagent systems (MASs), each agent makes individual decisions but all of them contribute globally to the system evolution. Learning in MASs is difficult since the selection of actions must take place in the presence of other co-learning agents. Moreover, the environmental stochasticity and uncertainties increase exponentially with the number of agents. A number of previous works borrow various multiagent coordination mechanisms into deep multiagent learning architecture to facilitate multiagent coordination. However, none of them explicitly consider action semantics between agents. In this paper, we propose a novel network architecture, named Action Semantics Network (ASN), that explicitly represents such action semantics between agents. ASN characterizes different actions' influence on other agents using neural networks based on the action semantics between agents. ASN can be easily combined with existing deep reinforcement learning (DRL) algorithms to boost their performance. Experimental results on StarCraft II and Neural MMO show ASN significantly improves the performance of state-of-the-art DRL approaches compared with a number of network architectures.