 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
Jun 09, 2026We introduce Embodied-R1.5, a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities, spanning embodied cognition, task planning, correction, and pointing, within a single architecture toward general physical intelligence. Leveraging three automated data construction pipelines to significantly expand the data coverage of critical capabilities, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe to alleviate heterogeneous task conflicts. We further introduce a Planner-Grounder-Corrector (PGC) closed-loop framework that enables a single model to autonomously execute and self-correct over long-horizon tasks. With only 8B parameters, Embodied-R1.5 achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5 and GPT-5.4. Benefiting from the internalized embodied capabilities, Embodied-R1.5 can be fine-tuned into a VLA with only a small amount of data, outperforming leading VLA models like $π_{0.5}$ across 4 popular manipulation benchmark suites. We further conduct extensive zero-shot real-robot experiments, validating performance in instruction following, affordance grounding, articulated object manipulation, and long-horizon complex tasks, demonstrating strong generalization to the physical world. We open-source model weights, datasets, training code, and EmbodiedEvalKit, an evaluation framework tailored for embodied tasks, to facilitate future research in EFMs.
Back to Basics: Revisiting Exploration in Reinforcement Learning for LLM Reasoning via Generative Probabilities
Feb 05, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as an indispensable paradigm for enhancing reasoning in Large Language Models (LLMs). However, standard policy optimization methods, such as Group Relative Policy Optimization (GRPO), often converge to low-entropy policies, leading to severe mode collapse and limited output diversity. We analyze this issue from the perspective of sampling probability dynamics, identifying that the standard objective disproportionately reinforces the highest-likelihood paths, thereby suppressing valid alternative reasoning chains. To address this, we propose a novel Advantage Re-weighting Mechanism (ARM) designed to equilibrate the confidence levels across all correct responses. By incorporating Prompt Perplexity and Answer Confidence into the advantage estimation, our method dynamically reshapes the reward signal to attenuate the gradient updates of over-confident reasoning paths, while redistributing probability mass toward under-explored correct solutions. Empirical results demonstrate that our approach significantly enhances generative diversity and response entropy while maintaining competitive accuracy, effectively achieving a superior trade-off between exploration and exploitation in reasoning tasks. Empirical results on Qwen2.5 and DeepSeek models across mathematical and coding benchmarks show that ProGRPO significantly mitigates entropy collapse. Specifically, on Qwen2.5-7B, our method outperforms GRPO by 5.7% in Pass@1 and, notably, by 13.9% in Pass@32, highlighting its superior capability in generating diverse correct reasoning paths.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models
Jun 05, 2025Large language models (LLMs) excel at reasoning, yet post-training remains critical for aligning their behavior with task goals. Existing reinforcement learning (RL) methods often depend on costly human annotations or external reward models. We propose Reinforcement Learning via Self-Confidence (RLSC), which uses the model's own confidence as reward signals-eliminating the need for labels, preference models, or reward engineering. Applied to Qwen2.5-Math-7B with only 8 samples per question and 4 training epochs, RLSC improves accuracy by +20.10% on AIME2024, +49.40% on MATH500, and +52.50% on AMC23. RLSC offers a simple, scalable post-training method for reasoning models with minimal supervision.
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025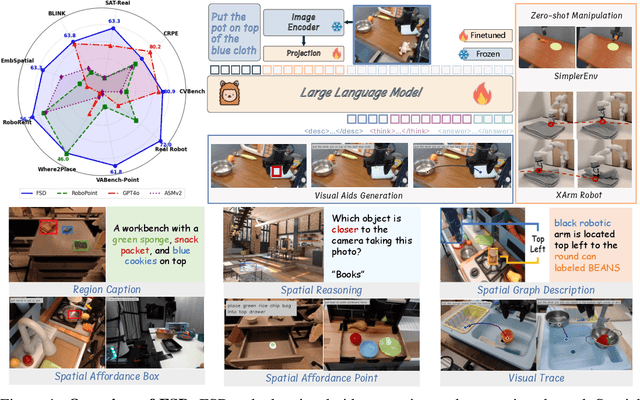

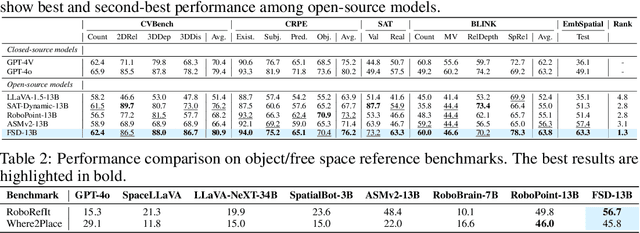
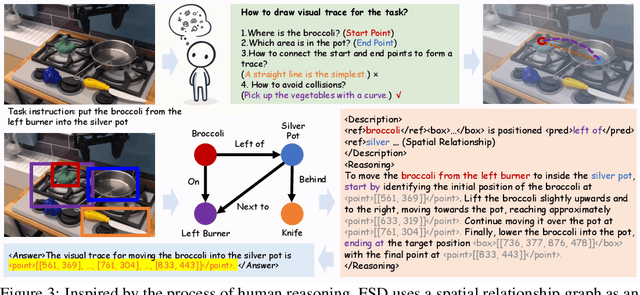
Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.
MaxInfo: A Training-Free Key-Frame Selection Method Using Maximum Volume for Enhanced Video Understanding
Feb 05, 2025Modern Video Large Language Models (VLLMs) often rely on uniform frame sampling for video understanding, but this approach frequently fails to capture critical information due to frame redundancy and variations in video content. We propose MaxInfo, a training-free method based on the maximum volume principle, which selects and retains the most representative frames from the input video. By maximizing the geometric volume formed by selected embeddings, MaxInfo ensures that the chosen frames cover the most informative regions of the embedding space, effectively reducing redundancy while preserving diversity. This method enhances the quality of input representations and improves long video comprehension performance across benchmarks. For instance, MaxInfo achieves a 3.28% improvement on LongVideoBench and a 6.4% improvement on EgoSchema for LLaVA-Video-7B. It also achieves a 3.47% improvement for LLaVA-Video-72B. The approach is simple to implement and works with existing VLLMs without the need for additional training, making it a practical and effective alternative to traditional uniform sampling methods.
CleanDiffuser: An Easy-to-use Modularized Library for Diffusion Models in Decision Making
Jun 13, 2024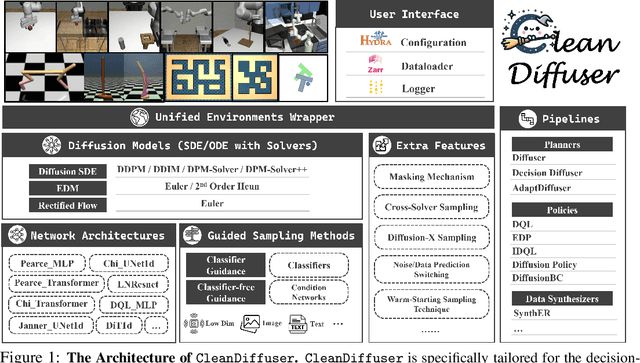
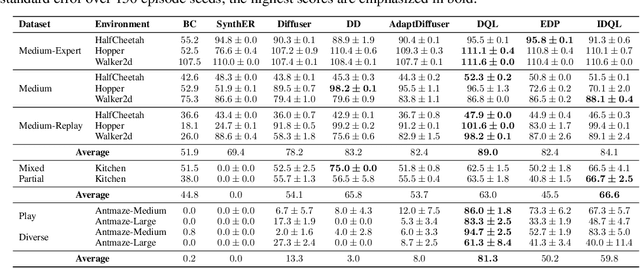
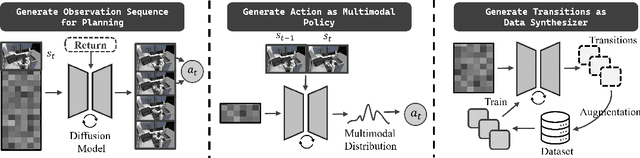
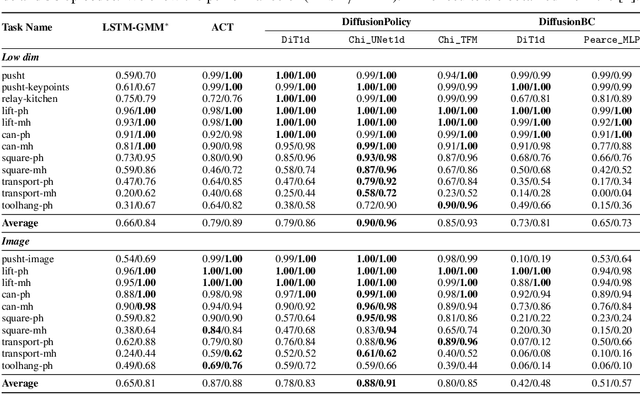
Leveraging the powerful generative capability of diffusion models (DMs) to build decision-making agents has achieved extensive success. However, there is still a demand for an easy-to-use and modularized open-source library that offers customized and efficient development for DM-based decision-making algorithms. In this work, we introduce CleanDiffuser, the first DM library specifically designed for decision-making algorithms. By revisiting the roles of DMs in the decision-making domain, we identify a set of essential sub-modules that constitute the core of CleanDiffuser, allowing for the implementation of various DM algorithms with simple and flexible building blocks. To demonstrate the reliability and flexibility of CleanDiffuser, we conduct comprehensive evaluations of various DM algorithms implemented with CleanDiffuser across an extensive range of tasks. The analytical experiments provide a wealth of valuable design choices and insights, reveal opportunities and challenges, and lay a solid groundwork for future research. CleanDiffuser will provide long-term support to the decision-making community, enhancing reproducibility and fostering the development of more robust solutions. The code and documentation of CleanDiffuser are open-sourced on the https://github.com/CleanDiffuserTeam/CleanDiffuser.
DiffuserLite: Towards Real-time Diffusion Planning
Feb 02, 2024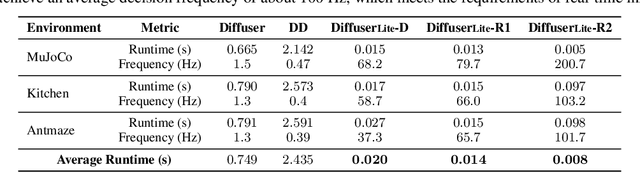
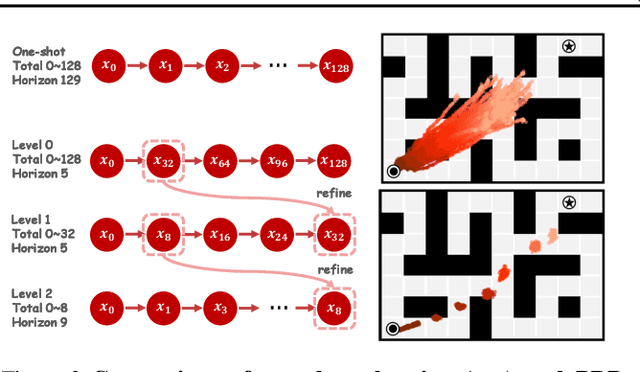
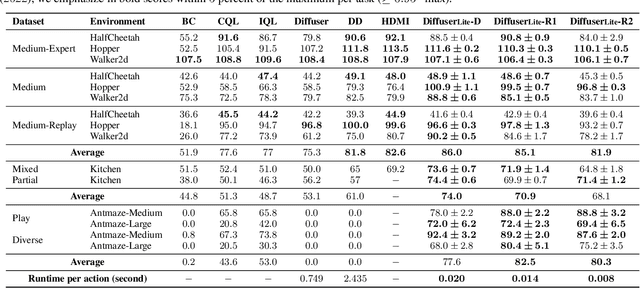
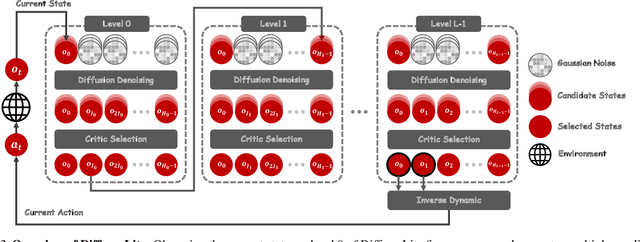
Diffusion planning has been recognized as an effective decision-making paradigm in various domains. The capability of conditionally generating high-quality long-horizon trajectories makes it a promising research direction. However, existing diffusion planning methods suffer from low decision-making frequencies due to the expensive iterative sampling cost. To address this issue, we introduce DiffuserLite, a super fast and lightweight diffusion planning framework. DiffuserLite employs a planning refinement process (PRP) to generate coarse-to-fine-grained trajectories, significantly reducing the modeling of redundant information and leading to notable increases in decision-making frequency. Our experimental results demonstrate that DiffuserLite achieves a decision-making frequency of $122$Hz ($112.7$x faster than previous mainstream frameworks) and reaches state-of-the-art performance on D4RL benchmarks. In addition, our neat DiffuserLite framework can serve as a flexible plugin to enhance decision frequency in other diffusion planning algorithms, providing a structural design reference for future works. More details and visualizations are available at https://diffuserlite.github.io/.
Bridging Evolutionary Algorithms and Reinforcement Learning: A Comprehensive Survey
Jan 22, 2024Evolutionary Reinforcement Learning (ERL), which integrates Evolutionary Algorithms (EAs) and Reinforcement Learning (RL) for optimization, has demonstrated remarkable performance advancements. By fusing the strengths of both approaches, ERL has emerged as a promising research direction. This survey offers a comprehensive overview of the diverse research branches in ERL. Specifically, we systematically summarize recent advancements in relevant algorithms and identify three primary research directions: EA-assisted optimization of RL, RL-assisted optimization of EA, and synergistic optimization of EA and RL. Following that, we conduct an in-depth analysis of each research direction, organizing multiple research branches. We elucidate the problems that each branch aims to tackle and how the integration of EA and RL addresses these challenges. In conclusion, we discuss potential challenges and prospective future research directions across various research directions.
ERL-Re$^2$: Efficient Evolutionary Reinforcement Learning with Shared State Representation and Individual Policy Representation
Oct 26, 2022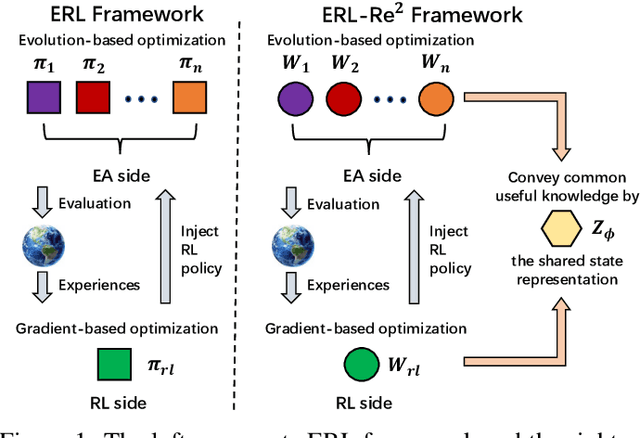
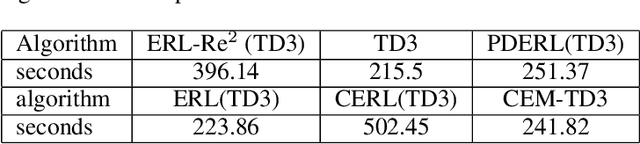
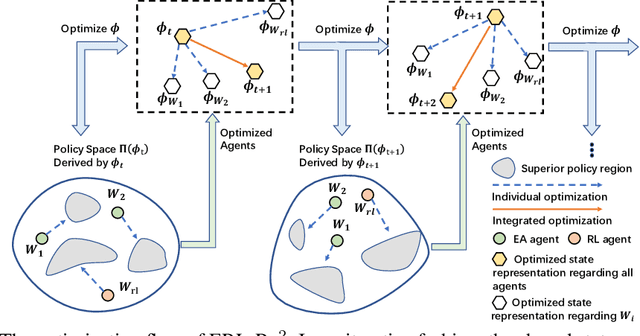
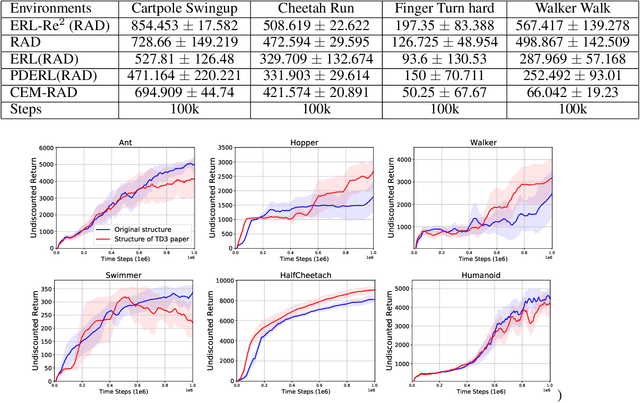
Deep Reinforcement Learning (Deep RL) and Evolutionary Algorithm (EA) are two major paradigms of policy optimization with distinct learning principles, i.e., gradient-based v.s. gradient free. An appealing research direction is integrating Deep RL and EA to devise new methods by fusing their complementary advantages. However, existing works on combining Deep RL and EA have two common drawbacks: 1) the RL agent and EA agents learn their policies individually, neglecting efficient sharing of useful common knowledge; 2) parameter-level policy optimization guarantees no semantic level of behavior evolution for the EA side. In this paper, we propose Evolutionary Reinforcement Learning with Two-scale State Representation and Policy Representation (ERL-Re2), a novel solution to the aforementioned two drawbacks. The key idea of ERL-Re2 is two-scale representation: all EA and RL policies share the same nonlinear state representation while maintaining individual linear policy representations. The state representation conveys expressive common features of the environment learned by all the agents collectively; the linear policy representation provides a favorable space for efficient policy optimization, where novel behavior-level crossover and mutation operations can be performed. Moreover, the linear policy representation allows convenient generalization of policy fitness with the help of Policy-extended Value Function Approximator (PeVFA), further improving the sample efficiency of fitness estimation. The experiments on a range of continuous control tasks show that ERL-Re2 consistently outperforms strong baselines and achieves significant improvement over both its Deep RL and EA components.