 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied-R1.5: Evolving Physical Intelligence via Embodied Foundation Models
Jun 09, 2026We introduce Embodied-R1.5, a unified Embodied Foundation Model (EFM) that integrates comprehensive embodied reasoning capabilities, spanning embodied cognition, task planning, correction, and pointing, within a single architecture toward general physical intelligence. Leveraging three automated data construction pipelines to significantly expand the data coverage of critical capabilities, we build a large-scale data system of over 15B tokens, and design a multi-task balanced RL recipe to alleviate heterogeneous task conflicts. We further introduce a Planner-Grounder-Corrector (PGC) closed-loop framework that enables a single model to autonomously execute and self-correct over long-horizon tasks. With only 8B parameters, Embodied-R1.5 achieves SOTA on 16 out of 24 embodied VLM benchmarks, surpassing leading models like Gemini-Robotics-ER-1.5 and GPT-5.4. Benefiting from the internalized embodied capabilities, Embodied-R1.5 can be fine-tuned into a VLA with only a small amount of data, outperforming leading VLA models like $π_{0.5}$ across 4 popular manipulation benchmark suites. We further conduct extensive zero-shot real-robot experiments, validating performance in instruction following, affordance grounding, articulated object manipulation, and long-horizon complex tasks, demonstrating strong generalization to the physical world. We open-source model weights, datasets, training code, and EmbodiedEvalKit, an evaluation framework tailored for embodied tasks, to facilitate future research in EFMs.
ActionCodec: What Makes for Good Action Tokenizers
Feb 17, 2026Vision-Language-Action (VLA) models leveraging the native autoregressive paradigm of Vision-Language Models (VLMs) have demonstrated superior instruction-following and training efficiency. Central to this paradigm is action tokenization, yet its design has primarily focused on reconstruction fidelity, failing to address its direct impact on VLA optimization. Consequently, the fundamental question of \textit{what makes for good action tokenizers} remains unanswered. In this paper, we bridge this gap by establishing design principles specifically from the perspective of VLA optimization. We identify a set of best practices based on information-theoretic insights, including maximized temporal token overlap, minimized vocabulary redundancy, enhanced multimodal mutual information, and token independence. Guided by these principles, we introduce \textbf{ActionCodec}, a high-performance action tokenizer that significantly enhances both training efficiency and VLA performance across diverse simulation and real-world benchmarks. Notably, on LIBERO, a SmolVLM2-2.2B fine-tuned with ActionCodec achieves a 95.5\% success rate without any robotics pre-training. With advanced architectural enhancements, this reaches 97.4\%, representing a new SOTA for VLA models without robotics pre-training. We believe our established design principles, alongside the released model, will provide a clear roadmap for the community to develop more effective action tokenizers.
UniForce: A Unified Latent Force Model for Robot Manipulation with Diverse Tactile Sensors
Feb 01, 2026Force sensing is essential for dexterous robot manipulation, but scaling force-aware policy learning is hindered by the heterogeneity of tactile sensors. Differences in sensing principles (e.g., optical vs. magnetic), form factors, and materials typically require sensor-specific data collection, calibration, and model training, thereby limiting generalisability. We propose UniForce, a novel unified tactile representation learning framework that learns a shared latent force space across diverse tactile sensors. UniForce reduces cross-sensor domain shift by jointly modeling inverse dynamics (image-to-force) and forward dynamics (force-to-image), constrained by force equilibrium and image reconstruction losses to produce force-grounded representations. To avoid reliance on expensive external force/torque (F/T) sensors, we exploit static equilibrium and collect force-paired data via direct sensor--object--sensor interactions, enabling cross-sensor alignment with contact force. The resulting universal tactile encoder can be plugged into downstream force-aware robot manipulation tasks with zero-shot transfer, without retraining or finetuning. Extensive experiments on heterogeneous tactile sensors including GelSight, TacTip, and uSkin, demonstrate consistent improvements in force estimation over prior methods, and enable effective cross-sensor coordination in Vision-Tactile-Language-Action (VTLA) models for a robotic wiping task. Code and datasets will be released.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
EmbodiedMAE: A Unified 3D Multi-Modal Representation for Robot Manipulation
May 15, 2025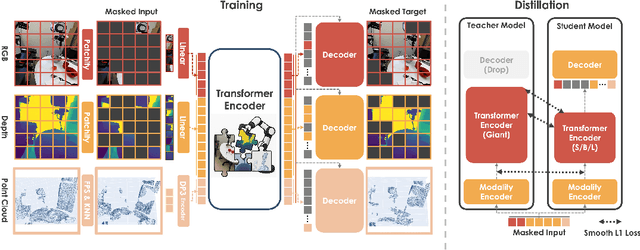


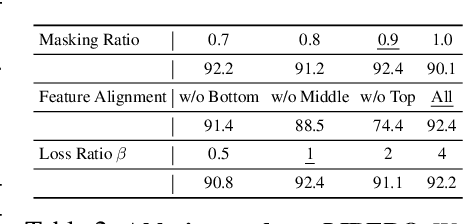
We present EmbodiedMAE, a unified 3D multi-modal representation for robot manipulation. Current approaches suffer from significant domain gaps between training datasets and robot manipulation tasks, while also lacking model architectures that can effectively incorporate 3D information. To overcome these limitations, we enhance the DROID dataset with high-quality depth maps and point clouds, constructing DROID-3D as a valuable supplement for 3D embodied vision research. Then we develop EmbodiedMAE, a multi-modal masked autoencoder that simultaneously learns representations across RGB, depth, and point cloud modalities through stochastic masking and cross-modal fusion. Trained on DROID-3D, EmbodiedMAE consistently outperforms state-of-the-art vision foundation models (VFMs) in both training efficiency and final performance across 70 simulation tasks and 20 real-world robot manipulation tasks on two robot platforms. The model exhibits strong scaling behavior with size and promotes effective policy learning from 3D inputs. Experimental results establish EmbodiedMAE as a reliable unified 3D multi-modal VFM for embodied AI systems, particularly in precise tabletop manipulation settings where spatial perception is critical.
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025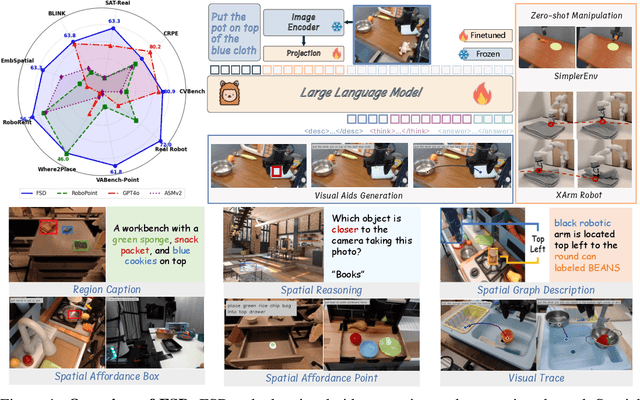

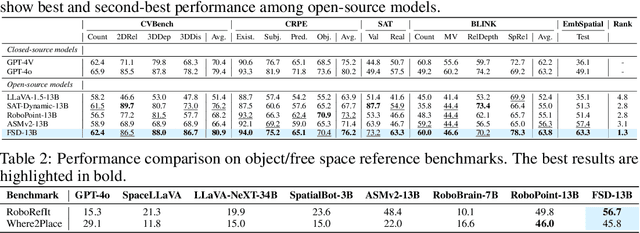
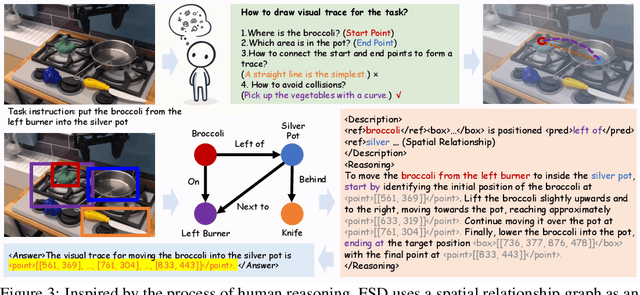
Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.
DualRAG: A Dual-Process Approach to Integrate Reasoning and Retrieval for Multi-Hop Question Answering
Apr 25, 2025



Multi-Hop Question Answering (MHQA) tasks permeate real-world applications, posing challenges in orchestrating multi-step reasoning across diverse knowledge domains. While existing approaches have been improved with iterative retrieval, they still struggle to identify and organize dynamic knowledge. To address this, we propose DualRAG, a synergistic dual-process framework that seamlessly integrates reasoning and retrieval. DualRAG operates through two tightly coupled processes: Reasoning-augmented Querying (RaQ) and progressive Knowledge Aggregation (pKA). They work in concert: as RaQ navigates the reasoning path and generates targeted queries, pKA ensures that newly acquired knowledge is systematically integrated to support coherent reasoning. This creates a virtuous cycle of knowledge enrichment and reasoning refinement. Through targeted fine-tuning, DualRAG preserves its sophisticated reasoning and retrieval capabilities even in smaller-scale models, demonstrating its versatility and core advantages across different scales. Extensive experiments demonstrate that this dual-process approach substantially improves answer accuracy and coherence, approaching, and in some cases surpassing, the performance achieved with oracle knowledge access. These results establish DualRAG as a robust and efficient solution for complex multi-hop reasoning tasks.
From Chaos to Order: The Atomic Reasoner Framework for Fine-grained Reasoning in Large Language Models
Mar 20, 2025



Recent advances in large language models (LLMs) have shown remarkable progress, yet their capacity for logical ``slow-thinking'' reasoning persists as a critical research frontier. Current inference scaling paradigms suffer from two fundamental constraints: fragmented thought flows compromising logical coherence, and intensively computational complexity that escalates with search space dimensions. To overcome these limitations, we present \textbf{Atomic Reasoner} (\textbf{AR}), a cognitive inference strategy that enables fine-grained reasoning through systematic atomic-level operations. AR decomposes the reasoning process into atomic cognitive units, employing a cognitive routing mechanism to dynamically construct reasoning representations and orchestrate inference pathways. This systematic methodology implements stepwise, structured cognition, which ensures logical coherence while significantly reducing cognitive load, effectively simulating the cognitive patterns observed in human deep thinking processes. Extensive experimental results demonstrate AR's superior reasoning capabilities without the computational burden of exhaustive solution searches, particularly excelling in linguistic logic puzzles. These findings substantiate AR's effectiveness in enhancing LLMs' capacity for robust, long-sequence logical reasoning and deliberation.
DexDiffuser: Interaction-aware Diffusion Planning for Adaptive Dexterous Manipulation
Nov 27, 2024



Dexterous manipulation with contact-rich interactions is crucial for advanced robotics. While recent diffusion-based planning approaches show promise for simpler manipulation tasks, they often produce unrealistic ghost states (e.g., the object automatically moves without hand contact) or lack adaptability when handling complex sequential interactions. In this work, we introduce DexDiffuser, an interaction-aware diffusion planning framework for adaptive dexterous manipulation. DexDiffuser models joint state-action dynamics through a dual-phase diffusion process which consists of pre-interaction contact alignment and post-contact goal-directed control, enabling goal-adaptive generalizable dexterous manipulation. Additionally, we incorporate dynamics model-based dual guidance and leverage large language models for automated guidance function generation, enhancing generalizability for physical interactions and facilitating diverse goal adaptation through language cues. Experiments on physical interaction tasks such as door opening, pen and block re-orientation, and hammer striking demonstrate DexDiffuser's effectiveness on goals outside training distributions, achieving over twice the average success rate (59.2% vs. 29.5%) compared to existing methods. Our framework achieves 70.0% success on 30-degree door opening, 40.0% and 36.7% on pen and block half-side re-orientation respectively, and 46.7% on hammer nail half drive, highlighting its robustness and flexibility in contact-rich manipulation.
CellAgent: An LLM-driven Multi-Agent Framework for Automated Single-cell Data Analysis
Jul 13, 2024Single-cell RNA sequencing (scRNA-seq) data analysis is crucial for biological research, as it enables the precise characterization of cellular heterogeneity. However, manual manipulation of various tools to achieve desired outcomes can be labor-intensive for researchers. To address this, we introduce CellAgent (http://cell.agent4science.cn/), an LLM-driven multi-agent framework, specifically designed for the automatic processing and execution of scRNA-seq data analysis tasks, providing high-quality results with no human intervention. Firstly, to adapt general LLMs to the biological field, CellAgent constructs LLM-driven biological expert roles - planner, executor, and evaluator - each with specific responsibilities. Then, CellAgent introduces a hierarchical decision-making mechanism to coordinate these biological experts, effectively driving the planning and step-by-step execution of complex data analysis tasks. Furthermore, we propose a self-iterative optimization mechanism, enabling CellAgent to autonomously evaluate and optimize solutions, thereby guaranteeing output quality. We evaluate CellAgent on a comprehensive benchmark dataset encompassing dozens of tissues and hundreds of distinct cell types. Evaluation results consistently show that CellAgent effectively identifies the most suitable tools and hyperparameters for single-cell analysis tasks, achieving optimal performance. This automated framework dramatically reduces the workload for science data analyses, bringing us into the "Agent for Science" era.