 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
Feb 03, 2026Humanoid perceptive locomotion has made significant progress and shows great promise, yet achieving robust multi-directional locomotion on complex terrains remains underexplored. To tackle this challenge, we propose RPL, a two-stage training framework that enables multi-directional locomotion on challenging terrains, and remains robust with payloads. RPL first trains terrain-specific expert policies with privileged height map observations to master decoupled locomotion and manipulation skills across different terrains, and then distills them into a transformer policy that leverages multiple depth cameras to cover a wide range of views. During distillation, we introduce two techniques to robustify multi-directional locomotion, depth feature scaling based on velocity commands and random side masking, which are critical for asymmetric depth observations and unseen widths of terrains. For scalable depth distillation, we develop an efficient multi-depth system that ray-casts against both dynamic robot meshes and static terrain meshes in massively parallel environments, achieving a 5-times speedup over the depth rendering pipelines in existing simulators while modeling realistic sensor latency, noise, and dropout. Extensive real-world experiments demonstrate robust multi-directional locomotion with payloads (2kg) across challenging terrains, including 20° slopes, staircases with different step lengths (22 cm, 25 cm, 30 cm), and 25 cm by 25 cm stepping stones separated by 60 cm gaps.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
EmbodiedMAE: A Unified 3D Multi-Modal Representation for Robot Manipulation
May 15, 2025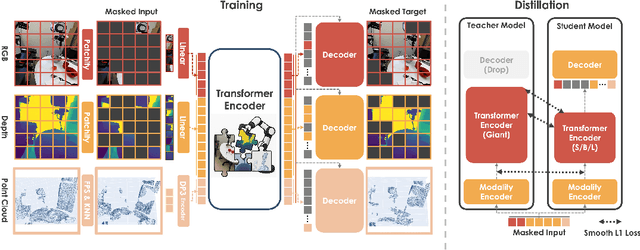


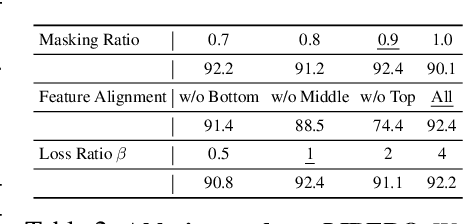
We present EmbodiedMAE, a unified 3D multi-modal representation for robot manipulation. Current approaches suffer from significant domain gaps between training datasets and robot manipulation tasks, while also lacking model architectures that can effectively incorporate 3D information. To overcome these limitations, we enhance the DROID dataset with high-quality depth maps and point clouds, constructing DROID-3D as a valuable supplement for 3D embodied vision research. Then we develop EmbodiedMAE, a multi-modal masked autoencoder that simultaneously learns representations across RGB, depth, and point cloud modalities through stochastic masking and cross-modal fusion. Trained on DROID-3D, EmbodiedMAE consistently outperforms state-of-the-art vision foundation models (VFMs) in both training efficiency and final performance across 70 simulation tasks and 20 real-world robot manipulation tasks on two robot platforms. The model exhibits strong scaling behavior with size and promotes effective policy learning from 3D inputs. Experimental results establish EmbodiedMAE as a reliable unified 3D multi-modal VFM for embodied AI systems, particularly in precise tabletop manipulation settings where spatial perception is critical.
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025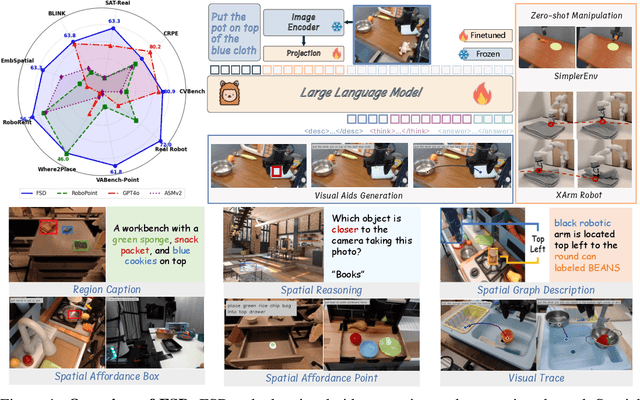

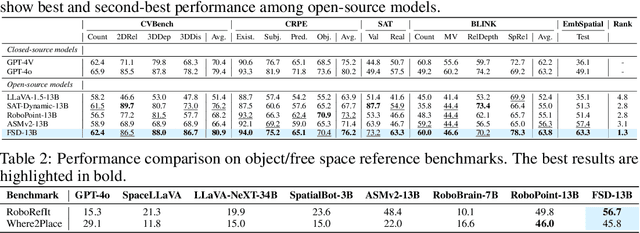
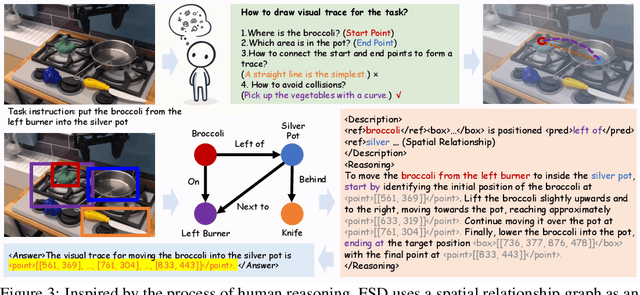
Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.
FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation
May 10, 2025Humanoid loco-manipulation holds transformative potential for daily service and industrial tasks, yet achieving precise, robust whole-body control with 3D end-effector force interaction remains a major challenge. Prior approaches are often limited to lightweight tasks or quadrupedal/wheeled platforms. To overcome these limitations, we propose FALCON, a dual-agent reinforcement-learning-based framework for robust force-adaptive humanoid loco-manipulation. FALCON decomposes whole-body control into two specialized agents: (1) a lower-body agent ensuring stable locomotion under external force disturbances, and (2) an upper-body agent precisely tracking end-effector positions with implicit adaptive force compensation. These two agents are jointly trained in simulation with a force curriculum that progressively escalates the magnitude of external force exerted on the end effector while respecting torque limits. Experiments demonstrate that, compared to the baselines, FALCON achieves 2x more accurate upper-body joint tracking, while maintaining robust locomotion under force disturbances and achieving faster training convergence. Moreover, FALCON enables policy training without embodiment-specific reward or curriculum tuning. Using the same training setup, we obtain policies that are deployed across multiple humanoids, enabling forceful loco-manipulation tasks such as transporting payloads (0-20N force), cart-pulling (0-100N), and door-opening (0-40N) in the real world.
From Chaos to Order: The Atomic Reasoner Framework for Fine-grained Reasoning in Large Language Models
Mar 20, 2025



Recent advances in large language models (LLMs) have shown remarkable progress, yet their capacity for logical ``slow-thinking'' reasoning persists as a critical research frontier. Current inference scaling paradigms suffer from two fundamental constraints: fragmented thought flows compromising logical coherence, and intensively computational complexity that escalates with search space dimensions. To overcome these limitations, we present \textbf{Atomic Reasoner} (\textbf{AR}), a cognitive inference strategy that enables fine-grained reasoning through systematic atomic-level operations. AR decomposes the reasoning process into atomic cognitive units, employing a cognitive routing mechanism to dynamically construct reasoning representations and orchestrate inference pathways. This systematic methodology implements stepwise, structured cognition, which ensures logical coherence while significantly reducing cognitive load, effectively simulating the cognitive patterns observed in human deep thinking processes. Extensive experimental results demonstrate AR's superior reasoning capabilities without the computational burden of exhaustive solution searches, particularly excelling in linguistic logic puzzles. These findings substantiate AR's effectiveness in enhancing LLMs' capacity for robust, long-sequence logical reasoning and deliberation.
AhaRobot: A Low-Cost Open-Source Bimanual Mobile Manipulator for Embodied AI
Mar 13, 2025Navigation and manipulation in open-world environments remain unsolved challenges in the Embodied AI. The high cost of commercial mobile manipulation robots significantly limits research in real-world scenes. To address this issue, we propose AhaRobot, a low-cost and fully open-source dual-arm mobile manipulation robot system with a hardware cost of only $1,000 (excluding optional computational resources), which is less than 1/15 of the cost of popular mobile robots. The AhaRobot system consists of three components: (1) a novel low-cost hardware architecture primarily composed of off-the-shelf components, (2) an optimized control solution to enhance operational precision integrating dual-motor backlash control and static friction compensation, and (3) a simple remote teleoperation method RoboPilot. We use handles to control the dual arms and pedals for whole-body movement. The teleoperation process is low-burden and easy to operate, much like piloting. RoboPilot is designed for remote data collection in embodied scenarios. Experimental results demonstrate that RoboPilot significantly enhances data collection efficiency in complex manipulation tasks, achieving a 30% increase compared to methods using 3D mouse and leader-follower systems. It also excels at completing extremely long-horizon tasks in one go. Furthermore, AhaRobot can be used to learn end-to-end policies and autonomously perform complex manipulation tasks, such as pen insertion and cleaning up the floor. We aim to build an affordable yet powerful platform to promote the development of embodied tasks on real devices, advancing more robust and reliable embodied AI. All hardware and software systems are available at https://aha-robot.github.io.
MODULI: Unlocking Preference Generalization via Diffusion Models for Offline Multi-Objective Reinforcement Learning
Aug 28, 2024



Multi-objective Reinforcement Learning (MORL) seeks to develop policies that simultaneously optimize multiple conflicting objectives, but it requires extensive online interactions. Offline MORL provides a promising solution by training on pre-collected datasets to generalize to any preference upon deployment. However, real-world offline datasets are often conservatively and narrowly distributed, failing to comprehensively cover preferences, leading to the emergence of out-of-distribution (OOD) preference areas. Existing offline MORL algorithms exhibit poor generalization to OOD preferences, resulting in policies that do not align with preferences. Leveraging the excellent expressive and generalization capabilities of diffusion models, we propose MODULI (Multi-objective Diffusion Planner with Sliding Guidance), which employs a preference-conditioned diffusion model as a planner to generate trajectories that align with various preferences and derive action for decision-making. To achieve accurate generation, MODULI introduces two return normalization methods under diverse preferences for refining guidance. To further enhance generalization to OOD preferences, MODULI proposes a novel sliding guidance mechanism, which involves training an additional slider adapter to capture the direction of preference changes. Incorporating the slider, it transitions from in-distribution (ID) preferences to generating OOD preferences, patching, and extending the incomplete Pareto front. Extensive experiments on the D4MORL benchmark demonstrate that our algorithm outperforms state-of-the-art Offline MORL baselines, exhibiting excellent generalization to OOD preferences.
CleanDiffuser: An Easy-to-use Modularized Library for Diffusion Models in Decision Making
Jun 13, 2024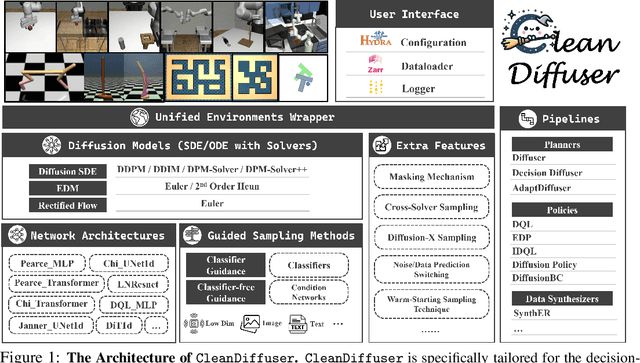
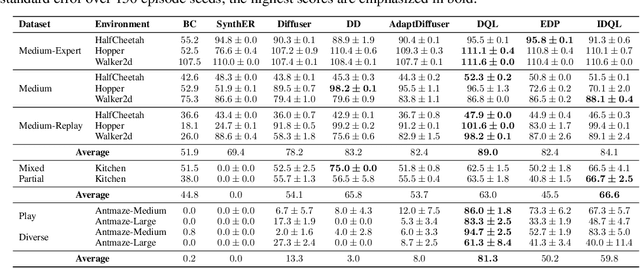
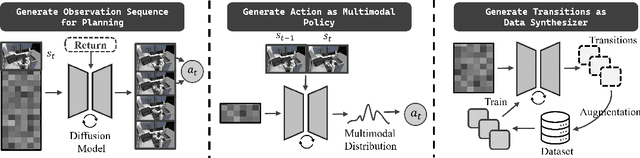
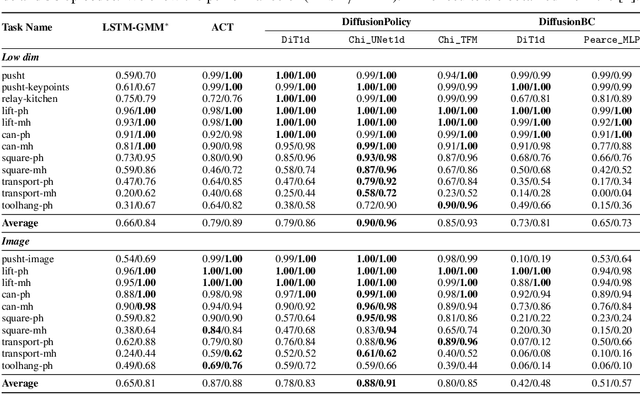
Leveraging the powerful generative capability of diffusion models (DMs) to build decision-making agents has achieved extensive success. However, there is still a demand for an easy-to-use and modularized open-source library that offers customized and efficient development for DM-based decision-making algorithms. In this work, we introduce CleanDiffuser, the first DM library specifically designed for decision-making algorithms. By revisiting the roles of DMs in the decision-making domain, we identify a set of essential sub-modules that constitute the core of CleanDiffuser, allowing for the implementation of various DM algorithms with simple and flexible building blocks. To demonstrate the reliability and flexibility of CleanDiffuser, we conduct comprehensive evaluations of various DM algorithms implemented with CleanDiffuser across an extensive range of tasks. The analytical experiments provide a wealth of valuable design choices and insights, reveal opportunities and challenges, and lay a solid groundwork for future research. CleanDiffuser will provide long-term support to the decision-making community, enhancing reproducibility and fostering the development of more robust solutions. The code and documentation of CleanDiffuser are open-sourced on the https://github.com/CleanDiffuserTeam/CleanDiffuser.
A Method on Searching Better Activation Functions
May 22, 2024



The success of artificial neural networks (ANNs) hinges greatly on the judicious selection of an activation function, introducing non-linearity into network and enabling them to model sophisticated relationships in data. However, the search of activation functions has largely relied on empirical knowledge in the past, lacking theoretical guidance, which has hindered the identification of more effective activation functions. In this work, we offer a proper solution to such issue. Firstly, we theoretically demonstrate the existence of the worst activation function with boundary conditions (WAFBC) from the perspective of information entropy. Furthermore, inspired by the Taylor expansion form of information entropy functional, we propose the Entropy-based Activation Function Optimization (EAFO) methodology. EAFO methodology presents a novel perspective for designing static activation functions in deep neural networks and the potential of dynamically optimizing activation during iterative training. Utilizing EAFO methodology, we derive a novel activation function from ReLU, known as Correction Regularized ReLU (CRReLU). Experiments conducted with vision transformer and its variants on CIFAR-10, CIFAR-100 and ImageNet-1K datasets demonstrate the superiority of CRReLU over existing corrections of ReLU. Extensive empirical studies on task of large language model (LLM) fine-tuning, CRReLU exhibits superior performance compared to GELU, suggesting its broader potential for practical applications.