 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding LLM Evaluator Behavior: A Structured Multi-Evaluator Framework for Merchant Risk Assessment
Feb 04, 2026Large Language Models (LLMs) are increasingly used as evaluators of reasoning quality, yet their reliability and bias in payments-risk settings remain poorly understood. We introduce a structured multi-evaluator framework for assessing LLM reasoning in Merchant Category Code (MCC)-based merchant risk assessment, combining a five-criterion rubric with Monte-Carlo scoring to evaluate rationale quality and evaluator stability. Five frontier LLMs generate and cross-evaluate MCC risk rationales under attributed and anonymized conditions. To establish a judge-independent reference, we introduce a consensus-deviation metric that eliminates circularity by comparing each judge's score to the mean of all other judges, yielding a theoretically grounded measure of self-evaluation and cross-model deviation. Results reveal substantial heterogeneity: GPT-5.1 and Claude 4.5 Sonnet show negative self-evaluation bias (-0.33, -0.31), while Gemini-2.5 Pro and Grok 4 display positive bias (+0.77, +0.71), with bias attenuating by 25.8 percent under anonymization. Evaluation by 26 payment-industry experts shows LLM judges assign scores averaging +0.46 points above human consensus, and that the negative bias of GPT-5.1 and Claude 4.5 Sonnet reflects closer alignment with human judgment. Ground-truth validation using payment-network data shows four models exhibit statistically significant alignment (Spearman rho = 0.56 to 0.77), confirming that the framework captures genuine quality. Overall, the framework provides a replicable basis for evaluating LLM-as-a-judge systems in payment-risk workflows and highlights the need for bias-aware protocols in operational financial settings.
Meta-Black-Box Optimization with Bi-Space Landscape Analysis and Dual-Control Mechanism for SAEA
Nov 19, 2025Surrogate-Assisted Evolutionary Algorithms (SAEAs) are widely used for expensive Black-Box Optimization. However, their reliance on rigid, manually designed components such as infill criteria and evolutionary strategies during the search process limits their flexibility across tasks. To address these limitations, we propose Dual-Control Bi-Space Surrogate-Assisted Evolutionary Algorithm (DB-SAEA), a Meta-Black-Box Optimization (MetaBBO) framework tailored for multi-objective problems. DB-SAEA learns a meta-policy that jointly regulates candidate generation and infill criterion selection, enabling dual control. The bi-space Exploratory Landscape Analysis (ELA) module in DB-SAEA adopts an attention-based architecture to capture optimization states from both true and surrogate evaluation spaces, while ensuring scalability across problem dimensions, population sizes, and objectives. Additionally, we integrate TabPFN as the surrogate model for accurate and efficient prediction with uncertainty estimation. The framework is trained via reinforcement learning, leveraging parallel sampling and centralized training to enhance efficiency and transferability across tasks. Experimental results demonstrate that DB-SAEA not only outperforms state-of-the-art baselines across diverse benchmarks, but also exhibits strong zero-shot transfer to unseen tasks with higher-dimensional settings. This work introduces the first MetaBBO framework with dual-level control over SAEAs and a bi-space ELA that captures surrogate model information.
Key Decision-Makers in Multi-Agent Debates: Who Holds the Power?
Nov 14, 2025Recent studies on LLM agent scaling have highlighted the potential of Multi-Agent Debate (MAD) to enhance reasoning abilities. However, the critical aspect of role allocation strategies remains underexplored. In this study, we demonstrate that allocating roles with differing viewpoints to specific positions significantly impacts MAD's performance in reasoning tasks. Specifically, we find a novel role allocation strategy, "Truth Last", which can improve MAD performance by up to 22% in reasoning tasks. To address the issue of unknown truth in practical applications, we propose the Multi-Agent Debate Consistency (MADC) strategy, which systematically simulates and optimizes its core mechanisms. MADC incorporates path consistency to assess agreement among independent roles, simulating the role with the highest consistency score as the truth. We validated MADC across a range of LLMs (9 models), including the DeepSeek-R1 Distilled Models, on challenging reasoning tasks. MADC consistently demonstrated advanced performance, effectively overcoming MAD's performance bottlenecks and providing a crucial pathway for further improvements in LLM agent scaling.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Empowering Time Series Forecasting with LLM-Agents
Aug 06, 2025Large Language Model (LLM) powered agents have emerged as effective planners for Automated Machine Learning (AutoML) systems. While most existing AutoML approaches focus on automating feature engineering and model architecture search, recent studies in time series forecasting suggest that lightweight models can often achieve state-of-the-art performance. This observation led us to explore improving data quality, rather than model architecture, as a potentially fruitful direction for AutoML on time series data. We propose DCATS, a Data-Centric Agent for Time Series. DCATS leverages metadata accompanying time series to clean data while optimizing forecasting performance. We evaluated DCATS using four time series forecasting models on a large-scale traffic volume forecasting dataset. Results demonstrate that DCATS achieves an average 6% error reduction across all tested models and time horizons, highlighting the potential of data-centric approaches in AutoML for time series forecasting.
Squeeze the Soaked Sponge: Efficient Off-policy Reinforcement Finetuning for Large Language Model
Jul 09, 2025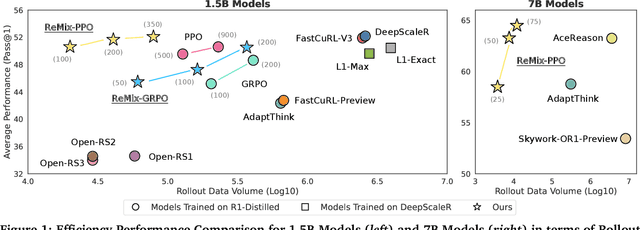
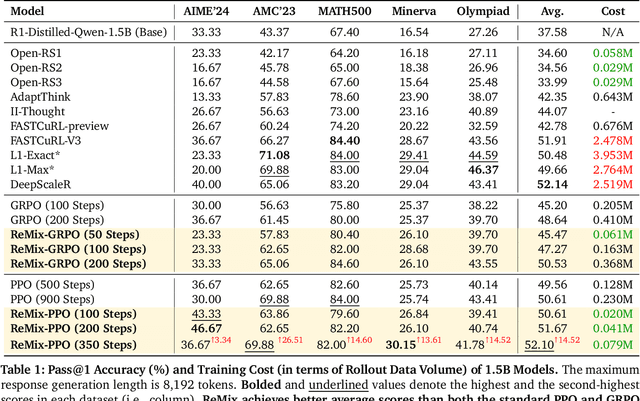
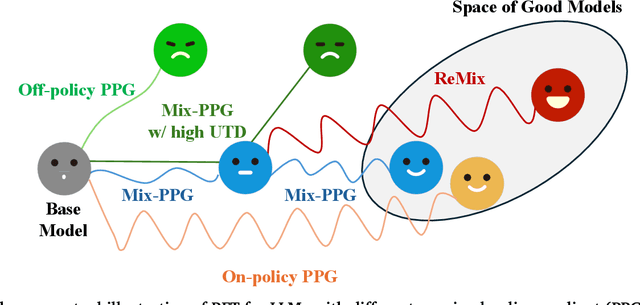
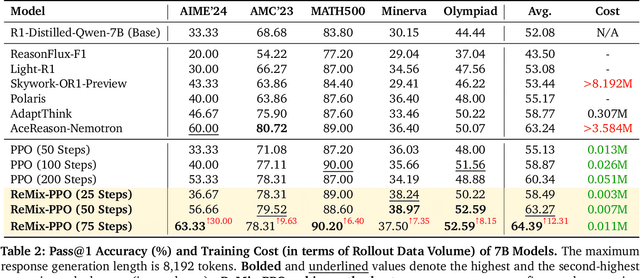
Reinforcement Learning (RL) has demonstrated its potential to improve the reasoning ability of Large Language Models (LLMs). One major limitation of most existing Reinforcement Finetuning (RFT) methods is that they are on-policy RL in nature, i.e., data generated during the past learning process is not fully utilized. This inevitably comes at a significant cost of compute and time, posing a stringent bottleneck on continuing economic and efficient scaling. To this end, we launch the renaissance of off-policy RL and propose Reincarnating Mix-policy Proximal Policy Gradient (ReMix), a general approach to enable on-policy RFT methods like PPO and GRPO to leverage off-policy data. ReMix consists of three major components: (1) Mix-policy proximal policy gradient with an increased Update-To-Data (UTD) ratio for efficient training; (2) KL-Convex policy constraint to balance the trade-off between stability and flexibility; (3) Policy reincarnation to achieve a seamless transition from efficient early-stage learning to steady asymptotic improvement. In our experiments, we train a series of ReMix models upon PPO, GRPO and 1.5B, 7B base models. ReMix shows an average Pass@1 accuracy of 52.10% (for 1.5B model) with 0.079M response rollouts, 350 training steps and achieves 63.27%/64.39% (for 7B model) with 0.007M/0.011M response rollouts, 50/75 training steps, on five math reasoning benchmarks (i.e., AIME'24, AMC'23, Minerva, OlympiadBench, and MATH500). Compared with 15 recent advanced models, ReMix shows SOTA-level performance with an over 30x to 450x reduction in training cost in terms of rollout data volume. In addition, we reveal insightful findings via multifaceted analysis, including the implicit preference for shorter responses due to the Whipping Effect of off-policy discrepancy, the collapse mode of self-reflection behavior under the presence of severe off-policyness, etc.
From Seeing to Doing: Bridging Reasoning and Decision for Robotic Manipulation
May 13, 2025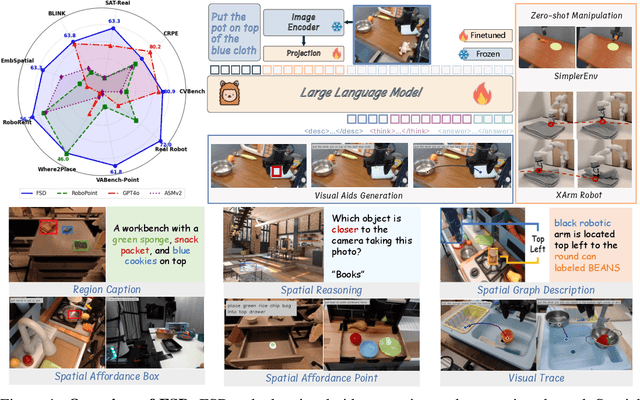

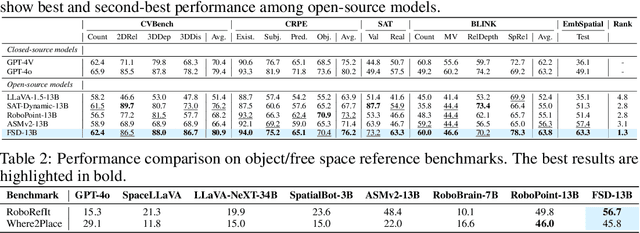
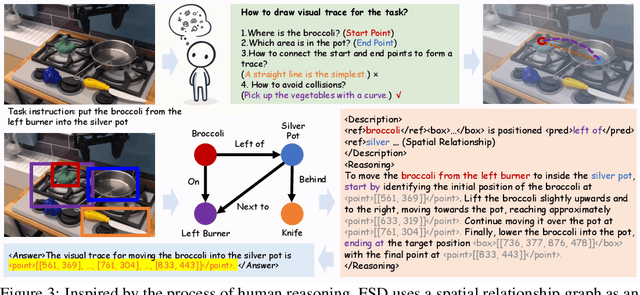
Achieving generalization in robotic manipulation remains a critical challenge, particularly for unseen scenarios and novel tasks. Current Vision-Language-Action (VLA) models, while building on top of general Vision-Language Models (VLMs), still fall short of achieving robust zero-shot performance due to the scarcity and heterogeneity prevalent in embodied datasets. To address these limitations, we propose FSD (From Seeing to Doing), a novel vision-language model that generates intermediate representations through spatial relationship reasoning, providing fine-grained guidance for robotic manipulation. Our approach combines a hierarchical data pipeline for training with a self-consistency mechanism that aligns spatial coordinates with visual signals. Through extensive experiments, we comprehensively validated FSD's capabilities in both "seeing" and "doing," achieving outstanding performance across 8 benchmarks for general spatial reasoning and embodied reference abilities, as well as on our proposed more challenging benchmark VABench. We also verified zero-shot capabilities in robot manipulation, demonstrating significant performance improvements over baseline methods in both SimplerEnv and real robot settings. Experimental results show that FSD achieves 54.1% success rate in SimplerEnv and 72% success rate across 8 real-world tasks, outperforming the strongest baseline by 30%.
Tweedie Regression for Video Recommendation System
May 09, 2025
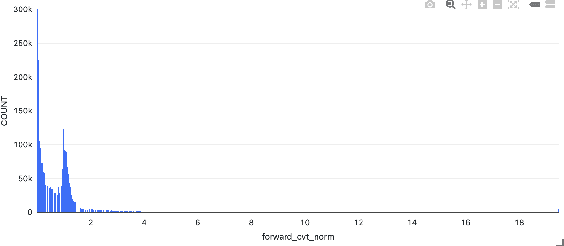
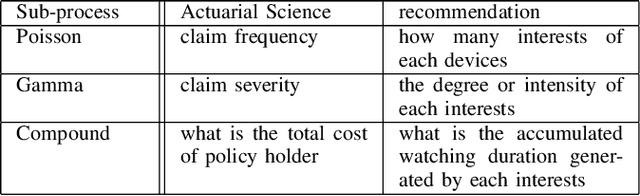
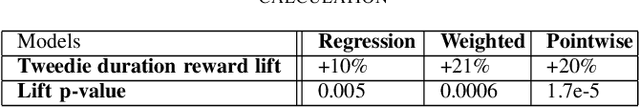
Modern recommendation systems aim to increase click-through rates (CTR) for better user experience, through commonly treating ranking as a classification task focused on predicting CTR. However, there is a gap between this method and the actual objectives of businesses across different sectors. In video recommendation services, the objective of video on demand (VOD) extends beyond merely encouraging clicks, but also guiding users to discover their true interests, leading to increased watch time. And longer users watch time will leads to more revenue through increased chances of presenting online display advertisements. This research addresses the issue by redefining the problem from classification to regression, with a focus on maximizing revenue through user viewing time. Due to the lack of positive labels on recommendation, the study introduces Tweedie Loss Function, which is better suited in this scenario than the traditional mean square error loss. The paper also provides insights on how Tweedie process capture users diverse interests. Our offline simulation and online A/B test revealed that we can substantially enhance our core business objectives: user engagement in terms of viewing time and, consequently, revenue. Additionally, we provide a theoretical comparison between the Tweedie Loss and the commonly employed viewing time weighted Logloss, highlighting why Tweedie Regression stands out as an efficient solution. We further outline a framework for designing a loss function that focuses on a singular objective.
From Chaos to Order: The Atomic Reasoner Framework for Fine-grained Reasoning in Large Language Models
Mar 20, 2025



Recent advances in large language models (LLMs) have shown remarkable progress, yet their capacity for logical ``slow-thinking'' reasoning persists as a critical research frontier. Current inference scaling paradigms suffer from two fundamental constraints: fragmented thought flows compromising logical coherence, and intensively computational complexity that escalates with search space dimensions. To overcome these limitations, we present \textbf{Atomic Reasoner} (\textbf{AR}), a cognitive inference strategy that enables fine-grained reasoning through systematic atomic-level operations. AR decomposes the reasoning process into atomic cognitive units, employing a cognitive routing mechanism to dynamically construct reasoning representations and orchestrate inference pathways. This systematic methodology implements stepwise, structured cognition, which ensures logical coherence while significantly reducing cognitive load, effectively simulating the cognitive patterns observed in human deep thinking processes. Extensive experimental results demonstrate AR's superior reasoning capabilities without the computational burden of exhaustive solution searches, particularly excelling in linguistic logic puzzles. These findings substantiate AR's effectiveness in enhancing LLMs' capacity for robust, long-sequence logical reasoning and deliberation.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025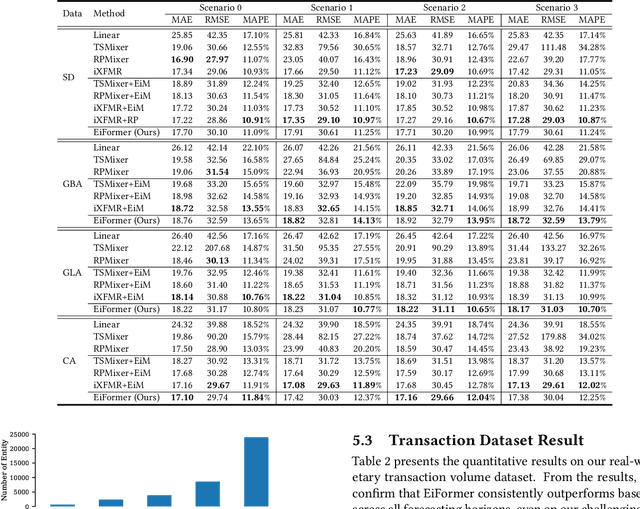
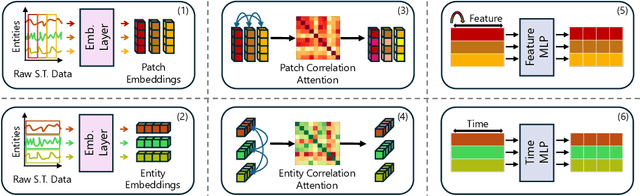
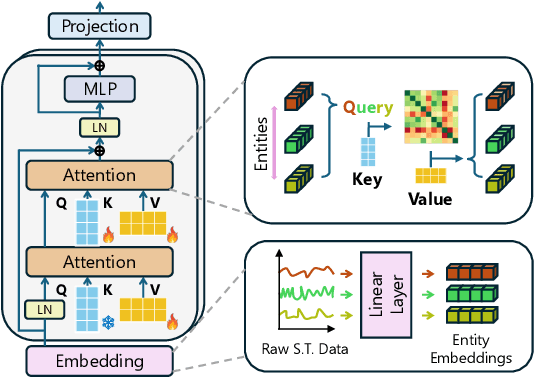
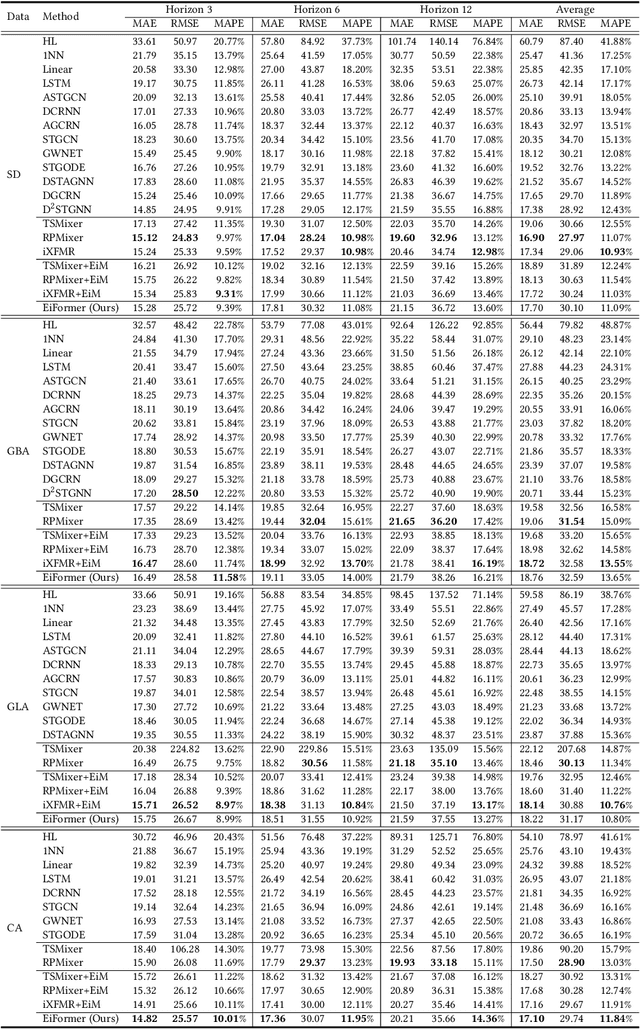
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.