 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Personalized Layer Selection for Graph Neural Networks
Jan 24, 2025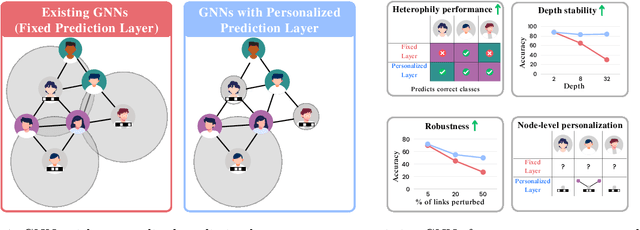
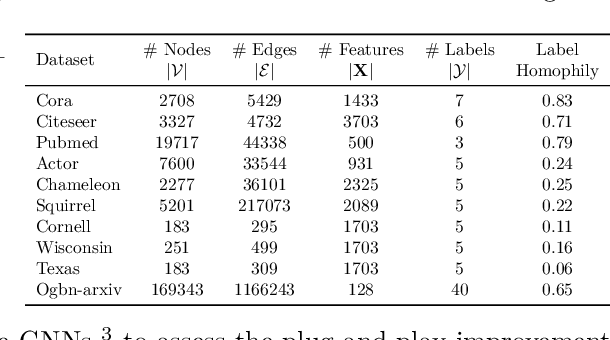
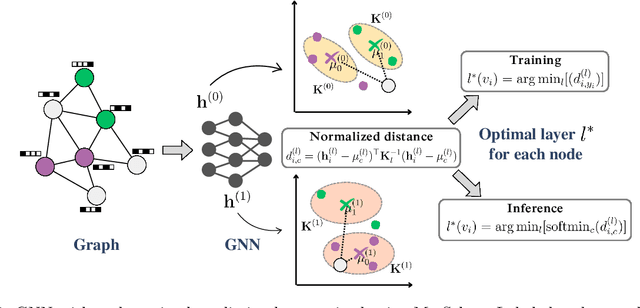
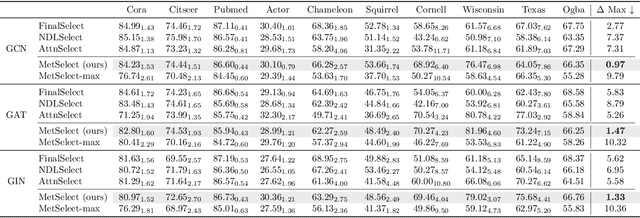
Graph Neural Networks (GNNs) combine node attributes over a fixed granularity of the local graph structure around a node to predict its label. However, different nodes may relate to a node-level property with a different granularity of its local neighborhood, and using the same level of smoothing for all nodes can be detrimental to their classification. In this work, we challenge the common fact that a single GNN layer can classify all nodes of a graph by training GNNs with a distinct personalized layer for each node. Inspired by metric learning, we propose a novel algorithm, MetSelect1, to select the optimal representation layer to classify each node. In particular, we identify a prototype representation of each class in a transformed GNN layer and then, classify using the layer where the distance is smallest to a class prototype after normalizing with that layer's variance. Results on 10 datasets and 3 different GNNs show that we significantly improve the node classification accuracy of GNNs in a plug-and-play manner. We also find that using variable layers for prediction enables GNNs to be deeper and more robust to poisoning attacks. We hope this work can inspire future works to learn more adaptive and personalized graph representations.
Preserving Individuality while Following the Crowd: Understanding the Role of User Taste and Crowd Wisdom in Online Product Rating Prediction
Sep 06, 2024



Numerous algorithms have been developed for online product rating prediction, but the specific influence of user and product information in determining the final prediction score remains largely unexplored. Existing research often relies on narrowly defined data settings, which overlooks real-world challenges such as the cold-start problem, cross-category information utilization, and scalability and deployment issues. To delve deeper into these aspects, and particularly to uncover the roles of individual user taste and collective wisdom, we propose a unique and practical approach that emphasizes historical ratings at both the user and product levels, encapsulated using a continuously updated dynamic tree representation. This representation effectively captures the temporal dynamics of users and products, leverages user information across product categories, and provides a natural solution to the cold-start problem. Furthermore, we have developed an efficient data processing strategy that makes this approach highly scalable and easily deployable. Comprehensive experiments in real industry settings demonstrate the effectiveness of our approach. Notably, our findings reveal that individual taste dominates over collective wisdom in online product rating prediction, a perspective that contrasts with the commonly observed wisdom of the crowd phenomenon in other domains. This dominance of individual user taste is consistent across various model types, including the boosting tree model, recurrent neural network (RNN), and transformer-based architectures. This observation holds true across the overall population, within individual product categories, and in cold-start scenarios. Our findings underscore the significance of individual user tastes in the context of online product rating prediction and the robustness of our approach across different model architectures.
Automating DBSCAN via Deep Reinforcement Learning
Aug 09, 2022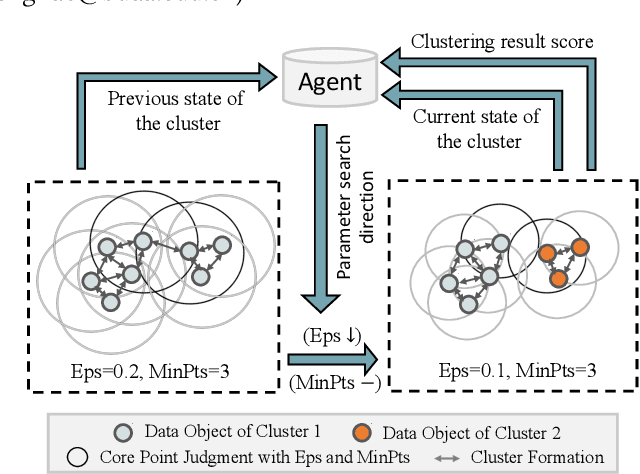
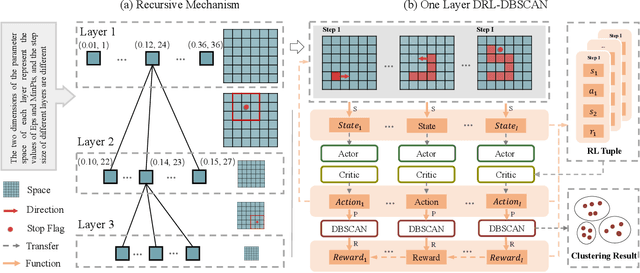

DBSCAN is widely used in many scientific and engineering fields because of its simplicity and practicality. However, due to its high sensitivity parameters, the accuracy of the clustering result depends heavily on practical experience. In this paper, we first propose a novel Deep Reinforcement Learning guided automatic DBSCAN parameters search framework, namely DRL-DBSCAN. The framework models the process of adjusting the parameter search direction by perceiving the clustering environment as a Markov decision process, which aims to find the best clustering parameters without manual assistance. DRL-DBSCAN learns the optimal clustering parameter search policy for different feature distributions via interacting with the clusters, using a weakly-supervised reward training policy network. In addition, we also present a recursive search mechanism driven by the scale of the data to efficiently and controllably process large parameter spaces. Extensive experiments are conducted on five artificial and real-world datasets based on the proposed four working modes. The results of offline and online tasks show that the DRL-DBSCAN not only consistently improves DBSCAN clustering accuracy by up to 26% and 25% respectively, but also can stably find the dominant parameters with high computational efficiency. The code is available at https://github.com/RingBDStack/DRL-DBSCAN.
Benchmarking Node Outlier Detection on Graphs
Jun 21, 2022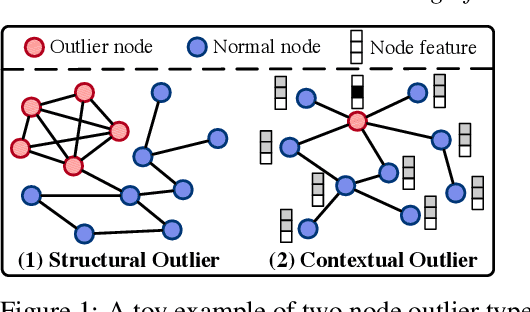
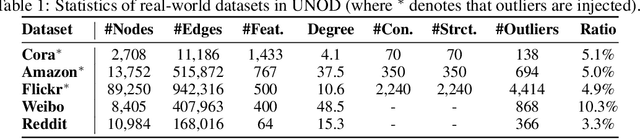

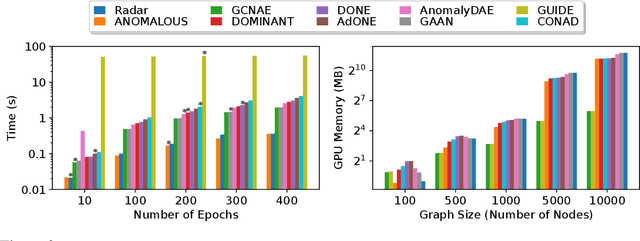
Graph outlier detection is an emerging but crucial machine learning task with numerous applications. Despite the proliferation of algorithms developed in recent years, the lack of a standard and unified setting for performance evaluation limits their advancement and usage in real-world applications. To tap the gap, we present, (to our best knowledge) the first comprehensive unsupervised node outlier detection benchmark for graphs called UNOD, with the following highlights: (1) evaluating fourteen methods with backbone spanning from classical matrix factorization to the latest graph neural networks; (2) benchmarking the method performance with different types of injected outliers and organic outliers on real-world datasets; (3) comparing the efficiency and scalability of the algorithms by runtime and GPU memory usage on synthetic graphs at different scales. Based on the analyses of extensive experimental results, we discuss the pros and cons of current UNOD methods, and point out multiple crucial and promising future research directions.
PyGOD: A Python Library for Graph Outlier Detection
Apr 26, 2022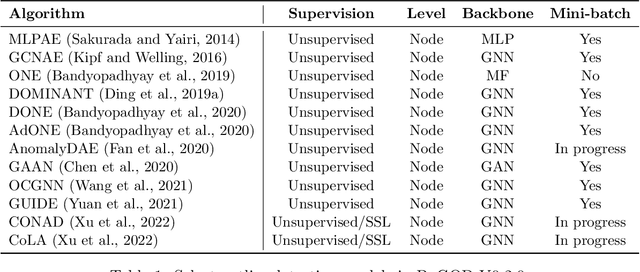
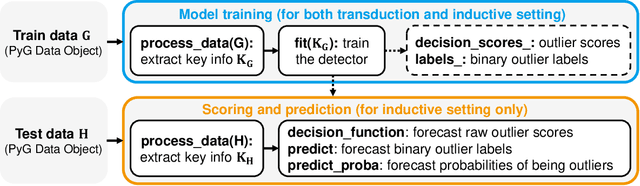
PyGOD is an open-source Python library for detecting outliers on graph data. As the first comprehensive library of its kind, PyGOD supports a wide array of leading graph-based methods for node-, edge-, subgraph-, and graph-level outlier detection, under a unified, well-documented API designed for use by both researchers and practitioners. To overcome the scalability issue in large graphs, we provide advanced functionalities for selected models, including mini-batch and sampling. PyGOD is equipped with best practices to foster code reliability and maintainability, including unit testing, continuous integration, and code coverage. To foster accessibility, PyGOD is released under a permissive BSD-license at https://github.com/pygod-team/pygod/ and the Python Package Index (PyPI).
Cross-lingual COVID-19 Fake News Detection
Oct 14, 2021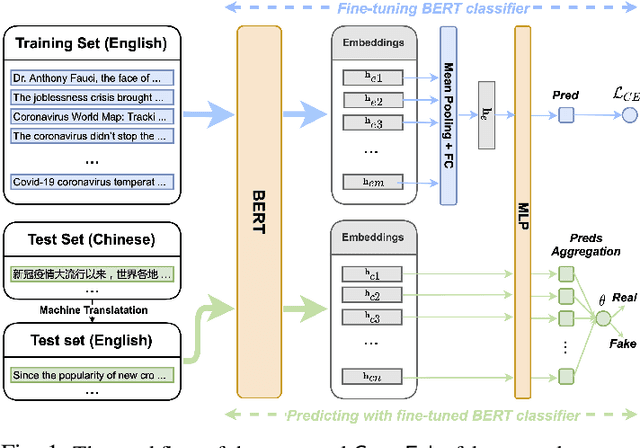

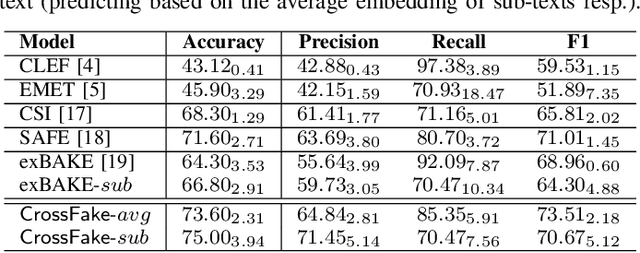
The COVID-19 pandemic poses a great threat to global public health. Meanwhile, there is massive misinformation associated with the pandemic which advocates unfounded or unscientific claims. Even major social media and news outlets have made an extra effort in debunking COVID-19 misinformation, most of the fact-checking information is in English, whereas some unmoderated COVID-19 misinformation is still circulating in other languages, threatening the health of less-informed people in immigrant communities and developing countries. In this paper, we make the first attempt to detect COVID-19 misinformation in a low-resource language (Chinese) only using the fact-checked news in a high-resource language (English). We start by curating a Chinese real&fake news dataset according to existing fact-checking information. Then, we propose a deep learning framework named CrossFake to jointly encode the cross-lingual news body texts and capture the news content as much as possible. Empirical results on our dataset demonstrate the effectiveness of CrossFake under the cross-lingual setting and it also outperforms several monolingual and cross-lingual fake news detectors. The dataset is available at https://github.com/YingtongDou/CrossFake.
Deep Fraud Detection on Non-attributed Graph
Oct 04, 2021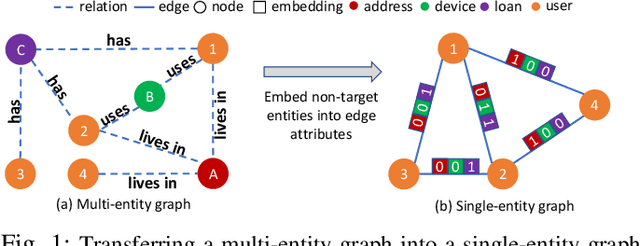
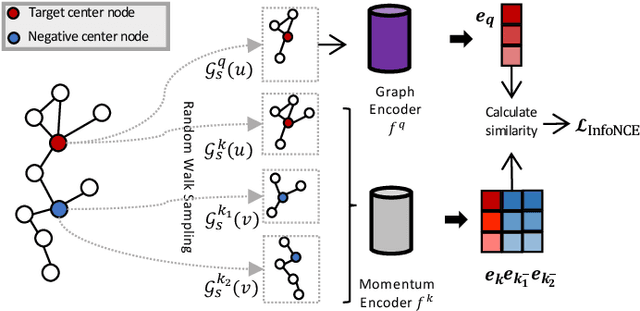

Fraud detection problems are usually formulated as a machine learning problem on a graph. Recently, Graph Neural Networks (GNNs) have shown solid performance on fraud detection. The successes of most previous methods heavily rely on rich node features and high-fidelity labels. However, labeled data is scarce in large-scale industrial problems, especially for fraud detection where new patterns emerge from time to time. Meanwhile, node features are also limited due to privacy and other constraints. In this paper, two improvements are proposed: 1) We design a graph transformation method capturing the structural information to facilitate GNNs on non-attributed fraud graphs. 2) We propose a novel graph pre-training strategy to leverage more unlabeled data via contrastive learning. Experiments on a large-scale industrial dataset demonstrate the effectiveness of the proposed framework for fraud detection.
User Preference-aware Fake News Detection
Apr 25, 2021



Disinformation and fake news have posed detrimental effects on individuals and society in recent years, attracting broad attention to fake news detection. The majority of existing fake news detection algorithms focus on mining news content and/or the surrounding exogenous context for discovering deceptive signals; while the endogenous preference of a user when he/she decides to spread a piece of fake news or not is ignored. The confirmation bias theory has indicated that a user is more likely to spread a piece of fake news when it confirms his/her existing beliefs/preferences. Users' historical, social engagements such as posts provide rich information about users' preferences toward news and have great potential to advance fake news detection. However, the work on exploring user preference for fake news detection is somewhat limited. Therefore, in this paper, we study the novel problem of exploiting user preference for fake news detection. We propose a new framework, UPFD, which simultaneously captures various signals from user preferences by joint content and graph modeling. Experimental results on real-world datasets demonstrate the effectiveness of the proposed framework. We release our code and data as a benchmark for GNN-based fake news detection: https://github.com/safe-graph/GNN-FakeNews.
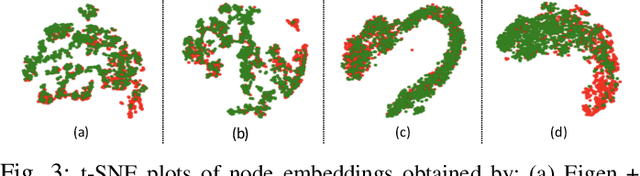
Higher-Order Attribute-Enhancing Heterogeneous Graph Neural Networks
Apr 16, 2021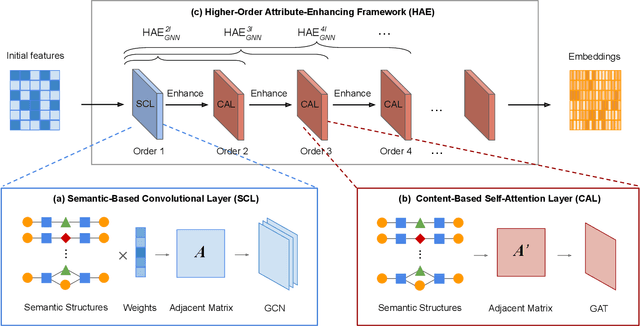
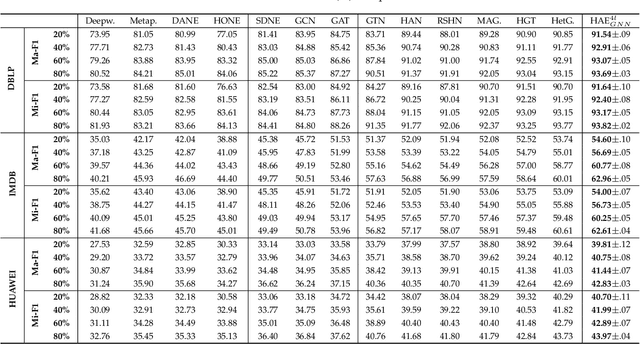


Graph neural networks (GNNs) have been widely used in deep learning on graphs. They can learn effective node representations that achieve superior performances in graph analysis tasks such as node classification and node clustering. However, most methods ignore the heterogeneity in real-world graphs. Methods designed for heterogeneous graphs, on the other hand, fail to learn complex semantic representations because they only use meta-paths instead of meta-graphs. Furthermore, they cannot fully capture the content-based correlations between nodes, as they either do not use the self-attention mechanism or only use it to consider the immediate neighbors of each node, ignoring the higher-order neighbors. We propose a novel Higher-order Attribute-Enhancing (HAE) framework that enhances node embedding in a layer-by-layer manner. Under the HAE framework, we propose a Higher-order Attribute-Enhancing Graph Neural Network (HAEGNN) for heterogeneous network representation learning. HAEGNN simultaneously incorporates meta-paths and meta-graphs for rich, heterogeneous semantics, and leverages the self-attention mechanism to explore content-based nodes interactions. The unique higher-order architecture of HAEGNN allows examining the first-order as well as higher-order neighborhoods. Moreover, HAEGNN shows good explainability as it learns the importances of different meta-paths and meta-graphs. HAEGNN is also memory-efficient, for it avoids per meta-path based matrix calculation. Experimental results not only show HAEGNN superior performance against the state-of-the-art methods in node classification, node clustering, and visualization, but also demonstrate its superiorities in terms of memory efficiency and explainability.