 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent
Feb 03, 2026While large language model (LLM) multi-agent systems achieve superior reasoning performance through iterative debate, practical deployment is limited by their high computational cost and error propagation. This paper proposes AgentArk, a novel framework to distill multi-agent dynamics into the weights of a single model, effectively transforming explicit test-time interactions into implicit model capabilities. This equips a single agent with the intelligence of multi-agent systems while remaining computationally efficient. Specifically, we investigate three hierarchical distillation strategies across various models, tasks, scaling, and scenarios: reasoning-enhanced fine-tuning; trajectory-based augmentation; and process-aware distillation. By shifting the burden of computation from inference to training, the distilled models preserve the efficiency of one agent while exhibiting strong reasoning and self-correction performance of multiple agents. They further demonstrate enhanced robustness and generalization across diverse reasoning tasks. We hope this work can shed light on future research on efficient and robust multi-agent development. Our code is at https://github.com/AIFrontierLab/AgentArk.
CALM-IT: Generating Realistic Long-Form Motivational Interviewing Dialogues with Dual-Actor Conversational Dynamics Tracking
Jan 15, 2026Large Language Models (LLMs) are increasingly used in mental health-related settings, yet they struggle to sustain realistic, goal-directed dialogue over extended interactions. While LLMs generate fluent responses, they optimize locally for the next turn rather than maintaining a coherent model of therapeutic progress, leading to brittleness and long-horizon drift. We introduce CALM-IT, a framework for generating and evaluating long-form Motivational Interviewing (MI) dialogues that explicitly models dual-actor conversational dynamics. CALM-IT represents therapist-client interaction as a bidirectional state-space process, in which both agents continuously update inferred alignment, mental states, and short-term goals to guide strategy selection and utterance generation. Across large-scale evaluations, CALM-IT consistently outperforms strong baselines in Effectiveness and Goal Alignment and remains substantially more stable as conversation length increases. Although CALM-IT initiates fewer therapist redirections, it achieves the highest client acceptance rate (64.3%), indicating more precise and therapeutically aligned intervention timing. Overall, CALM-IT provides evidence for modeling evolving conversational state being essential for generating high-quality long-form synthetic conversations.
SlideAgent: Hierarchical Agentic Framework for Multi-Page Visual Document Understanding
Oct 30, 2025
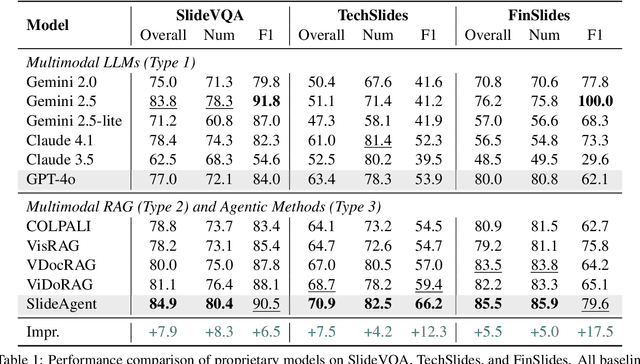


Multi-page visual documents such as manuals, brochures, presentations, and posters convey key information through layout, colors, icons, and cross-slide references. While large language models (LLMs) offer opportunities in document understanding, current systems struggle with complex, multi-page visual documents, particularly in fine-grained reasoning over elements and pages. We introduce SlideAgent, a versatile agentic framework for understanding multi-modal, multi-page, and multi-layout documents, especially slide decks. SlideAgent employs specialized agents and decomposes reasoning into three specialized levels-global, page, and element-to construct a structured, query-agnostic representation that captures both overarching themes and detailed visual or textual cues. During inference, SlideAgent selectively activates specialized agents for multi-level reasoning and integrates their outputs into coherent, context-aware answers. Extensive experiments show that SlideAgent achieves significant improvement over both proprietary (+7.9 overall) and open-source models (+9.8 overall).
The Influence of Text Variation on User Engagement in Cross-Platform Content Sharing
Apr 26, 2025In today's cross-platform social media landscape, understanding factors that drive engagement for multimodal content, especially text paired with visuals, remains complex. This study investigates how rewriting Reddit post titles adapted from YouTube video titles affects user engagement. First, we build and analyze a large dataset of Reddit posts sharing YouTube videos, revealing that 21% of post titles are minimally modified. Statistical analysis demonstrates that title rewrites measurably improve engagement. Second, we design a controlled, multi-phase experiment to rigorously isolate the effects of textual variations by neutralizing confounding factors like video popularity, timing, and community norms. Comprehensive statistical tests reveal that effective title rewrites tend to feature emotional resonance, lexical richness, and alignment with community-specific norms. Lastly, pairwise ranking prediction experiments using a fine-tuned BERT classifier achieves 74% accuracy, significantly outperforming near-random baselines, including GPT-4o. These results validate that our controlled dataset effectively minimizes confounding effects, allowing advanced models to both learn and demonstrate the impact of textual features on engagement. By bridging quantitative rigor with qualitative insights, this study uncovers engagement dynamics and offers a robust framework for future cross-platform, multimodal content strategies.
A Framework for Situating Innovations, Opportunities, and Challenges in Advancing Vertical Systems with Large AI Models
Apr 03, 2025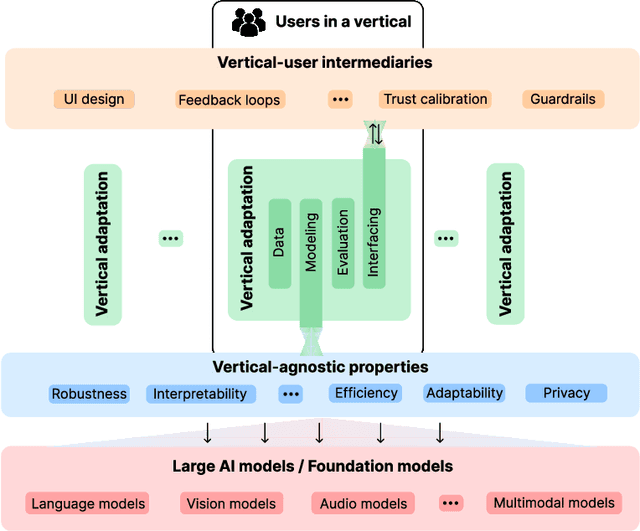
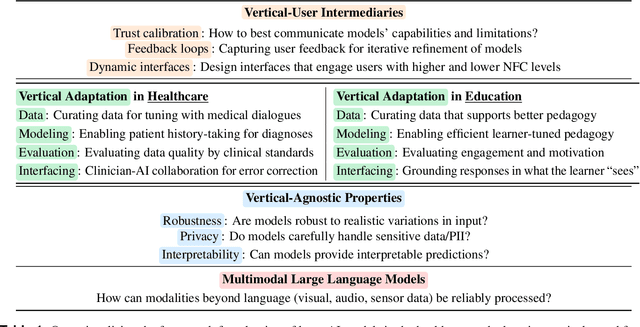
Large artificial intelligence (AI) models have garnered significant attention for their remarkable, often "superhuman", performance on standardized benchmarks. However, when these models are deployed in high-stakes verticals such as healthcare, education, and law, they often reveal notable limitations. For instance, they exhibit brittleness to minor variations in input data, present contextually uninformed decisions in critical settings, and undermine user trust by confidently producing or reproducing inaccuracies. These challenges in applying large models necessitate cross-disciplinary innovations to align the models' capabilities with the needs of real-world applications. We introduce a framework that addresses this gap through a layer-wise abstraction of innovations aimed at meeting users' requirements with large models. Through multiple case studies, we illustrate how researchers and practitioners across various fields can operationalize this framework. Beyond modularizing the pipeline of transforming large models into useful "vertical systems", we also highlight the dynamism that exists within different layers of the framework. Finally, we discuss how our framework can guide researchers and practitioners to (i) optimally situate their innovations (e.g., when vertical-specific insights can empower broadly impactful vertical-agnostic innovations), (ii) uncover overlooked opportunities (e.g., spotting recurring problems across verticals to develop practically useful foundation models instead of chasing benchmarks), and (iii) facilitate cross-disciplinary communication of critical challenges (e.g., enabling a shared vocabulary for AI developers, domain experts, and human-computer interaction scholars).
A Thousand Words or An Image: Studying the Influence of Persona Modality in Multimodal LLMs
Feb 27, 2025Large language models (LLMs) have recently demonstrated remarkable advancements in embodying diverse personas, enhancing their effectiveness as conversational agents and virtual assistants. Consequently, LLMs have made significant strides in processing and integrating multimodal information. However, even though human personas can be expressed in both text and image, the extent to which the modality of a persona impacts the embodiment by the LLM remains largely unexplored. In this paper, we investigate how do different modalities influence the expressiveness of personas in multimodal LLMs. To this end, we create a novel modality-parallel dataset of 40 diverse personas varying in age, gender, occupation, and location. This consists of four modalities to equivalently represent a persona: image-only, text-only, a combination of image and small text, and typographical images, where text is visually stylized to convey persona-related attributes. We then create a systematic evaluation framework with 60 questions and corresponding metrics to assess how well LLMs embody each persona across its attributes and scenarios. Comprehensive experiments on $5$ multimodal LLMs show that personas represented by detailed text show more linguistic habits, while typographical images often show more consistency with the persona. Our results reveal that LLMs often overlook persona-specific details conveyed through images, highlighting underlying limitations and paving the way for future research to bridge this gap. We release the data and code at https://github.com/claws-lab/persona-modality .
Personalized Layer Selection for Graph Neural Networks
Jan 24, 2025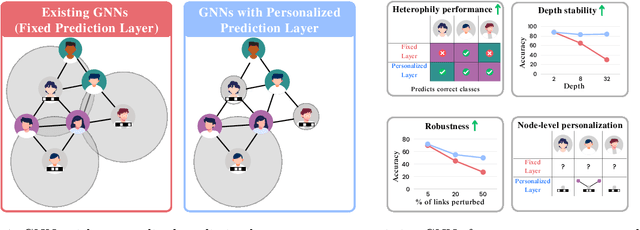
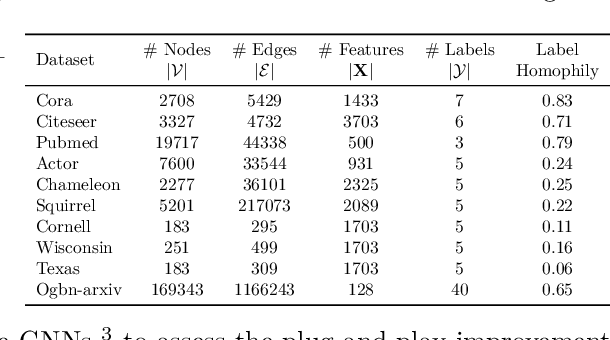
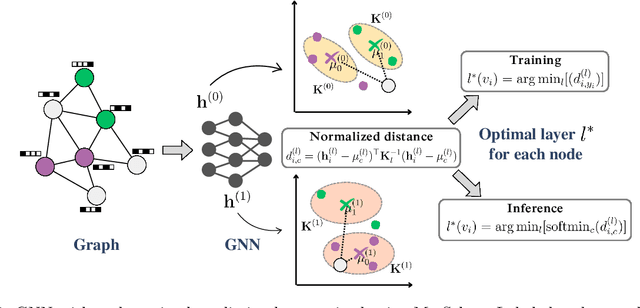
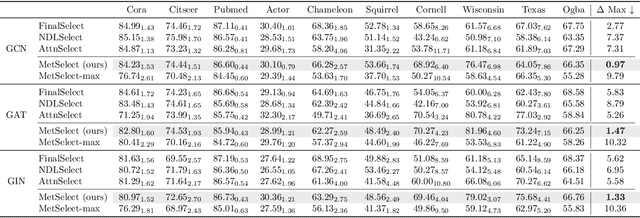
Graph Neural Networks (GNNs) combine node attributes over a fixed granularity of the local graph structure around a node to predict its label. However, different nodes may relate to a node-level property with a different granularity of its local neighborhood, and using the same level of smoothing for all nodes can be detrimental to their classification. In this work, we challenge the common fact that a single GNN layer can classify all nodes of a graph by training GNNs with a distinct personalized layer for each node. Inspired by metric learning, we propose a novel algorithm, MetSelect1, to select the optimal representation layer to classify each node. In particular, we identify a prototype representation of each class in a transformed GNN layer and then, classify using the layer where the distance is smallest to a class prototype after normalizing with that layer's variance. Results on 10 datasets and 3 different GNNs show that we significantly improve the node classification accuracy of GNNs in a plug-and-play manner. We also find that using variable layers for prediction enables GNNs to be deeper and more robust to poisoning attacks. We hope this work can inspire future works to learn more adaptive and personalized graph representations.
UniGuard: Towards Universal Safety Guardrails for Jailbreak Attacks on Multimodal Large Language Models
Nov 03, 2024



Multimodal large language models (MLLMs) have revolutionized vision-language understanding but are vulnerable to multimodal jailbreak attacks, where adversaries meticulously craft inputs to elicit harmful or inappropriate responses. We propose UniGuard, a novel multimodal safety guardrail that jointly considers the unimodal and cross-modal harmful signals. UniGuard is trained such that the likelihood of generating harmful responses in a toxic corpus is minimized, and can be seamlessly applied to any input prompt during inference with minimal computational costs. Extensive experiments demonstrate the generalizability of UniGuard across multiple modalities and attack strategies. It demonstrates impressive generalizability across multiple state-of-the-art MLLMs, including LLaVA, Gemini Pro, GPT-4, MiniGPT-4, and InstructBLIP, thereby broadening the scope of our solution.
Do Large Language Models Align with Core Mental Health Counseling Competencies?
Oct 29, 2024



The rapid evolution of Large Language Models (LLMs) offers promising potential to alleviate the global scarcity of mental health professionals. However, LLMs' alignment with essential mental health counseling competencies remains understudied. We introduce CounselingBench, a novel NCMHCE-based benchmark evaluating LLMs across five key mental health counseling competencies. Testing 22 general-purpose and medical-finetuned LLMs, we find frontier models exceed minimum thresholds but fall short of expert-level performance, with significant variations: they excel in Intake, Assessment & Diagnosis yet struggle with Core Counseling Attributes and Professional Practice & Ethics. Medical LLMs surprisingly underperform generalist models accuracy-wise, while at the same time producing slightly higher-quality justifications but making more context-related errors. Our findings highlight the complexities of developing AI systems for mental health counseling, particularly for competencies requiring empathy and contextual understanding. We found that frontier LLMs perform at a level exceeding the minimal required level of aptitude for all key mental health counseling competencies, but fall short of expert-level performance, and that current medical LLMs do not significantly improve upon generalist models in mental health counseling competencies. This underscores the critical need for specialized, mental health counseling-specific fine-tuned LLMs that rigorously aligns with core competencies combined with appropriate human supervision before any responsible real-world deployment can be considered.
MedHalu: Hallucinations in Responses to Healthcare Queries by Large Language Models
Sep 29, 2024The remarkable capabilities of large language models (LLMs) in language understanding and generation have not rendered them immune to hallucinations. LLMs can still generate plausible-sounding but factually incorrect or fabricated information. As LLM-empowered chatbots become popular, laypeople may frequently ask health-related queries and risk falling victim to these LLM hallucinations, resulting in various societal and healthcare implications. In this work, we conduct a pioneering study of hallucinations in LLM-generated responses to real-world healthcare queries from patients. We propose MedHalu, a carefully crafted first-of-its-kind medical hallucination dataset with a diverse range of health-related topics and the corresponding hallucinated responses from LLMs with labeled hallucination types and hallucinated text spans. We also introduce MedHaluDetect framework to evaluate capabilities of various LLMs in detecting hallucinations. We also employ three groups of evaluators -- medical experts, LLMs, and laypeople -- to study who are more vulnerable to these medical hallucinations. We find that LLMs are much worse than the experts. They also perform no better than laypeople and even worse in few cases in detecting hallucinations. To fill this gap, we propose expert-in-the-loop approach to improve hallucination detection through LLMs by infusing expert reasoning. We observe significant performance gains for all the LLMs with an average macro-F1 improvement of 6.3 percentage points for GPT-4.