 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConversation Kernels: A Flexible Mechanism to Learn Relevant Context for Online Conversation Understanding
May 26, 2025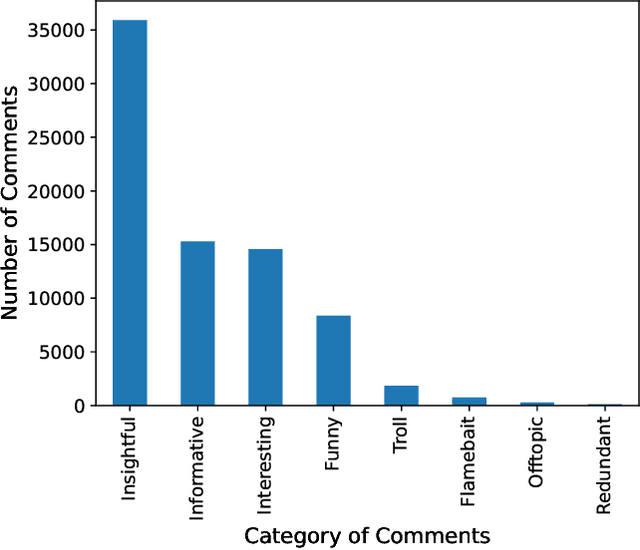
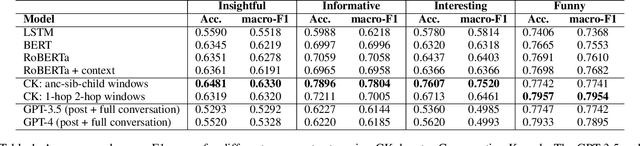
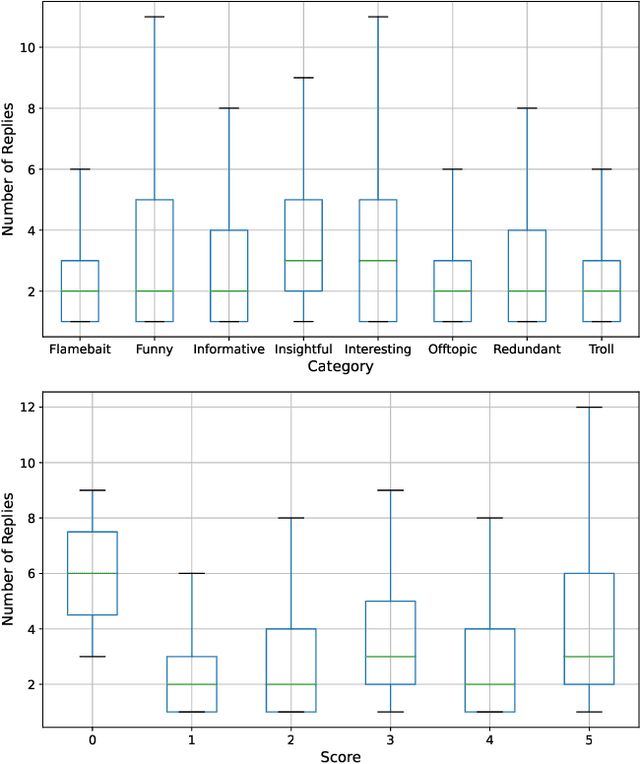

Understanding online conversations has attracted research attention with the growth of social networks and online discussion forums. Content analysis of posts and replies in online conversations is difficult because each individual utterance is usually short and may implicitly refer to other posts within the same conversation. Thus, understanding individual posts requires capturing the conversational context and dependencies between different parts of a conversation tree and then encoding the context dependencies between posts and comments/replies into the language model. To this end, we propose a general-purpose mechanism to discover appropriate conversational context for various aspects about an online post in a conversation, such as whether it is informative, insightful, interesting or funny. Specifically, we design two families of Conversation Kernels, which explore different parts of the neighborhood of a post in the tree representing the conversation and through this, build relevant conversational context that is appropriate for each task being considered. We apply our developed method to conversations crawled from slashdot.org, which allows users to apply highly different labels to posts, such as 'insightful', 'funny', etc., and therefore provides an ideal experimental platform to study whether a framework such as Conversation Kernels is general-purpose and flexible enough to be adapted to disparately different conversation understanding tasks.
MedHalu: Hallucinations in Responses to Healthcare Queries by Large Language Models
Sep 29, 2024The remarkable capabilities of large language models (LLMs) in language understanding and generation have not rendered them immune to hallucinations. LLMs can still generate plausible-sounding but factually incorrect or fabricated information. As LLM-empowered chatbots become popular, laypeople may frequently ask health-related queries and risk falling victim to these LLM hallucinations, resulting in various societal and healthcare implications. In this work, we conduct a pioneering study of hallucinations in LLM-generated responses to real-world healthcare queries from patients. We propose MedHalu, a carefully crafted first-of-its-kind medical hallucination dataset with a diverse range of health-related topics and the corresponding hallucinated responses from LLMs with labeled hallucination types and hallucinated text spans. We also introduce MedHaluDetect framework to evaluate capabilities of various LLMs in detecting hallucinations. We also employ three groups of evaluators -- medical experts, LLMs, and laypeople -- to study who are more vulnerable to these medical hallucinations. We find that LLMs are much worse than the experts. They also perform no better than laypeople and even worse in few cases in detecting hallucinations. To fill this gap, we propose expert-in-the-loop approach to improve hallucination detection through LLMs by infusing expert reasoning. We observe significant performance gains for all the LLMs with an average macro-F1 improvement of 6.3 percentage points for GPT-4.
CodeMirage: Hallucinations in Code Generated by Large Language Models
Aug 14, 2024



Large Language Models (LLMs) have shown promising potentials in program generation and no-code automation. However, LLMs are prone to generate hallucinations, i.e., they generate text which sounds plausible but is incorrect. Although there has been a recent surge in research on LLM hallucinations for text generation, similar hallucination phenomenon can happen in code generation. Sometimes the generated code can have syntactical or logical errors as well as more advanced issues like security vulnerabilities, memory leaks, etc. Given the wide adaptation of LLMs to enhance efficiency in code generation and development in general, it becomes imperative to investigate hallucinations in code generation. To the best of our knowledge, this is the first attempt at studying hallucinations in the code generated by LLMs. We start by introducing the code hallucination definition and a comprehensive taxonomy of code hallucination types. We propose the first benchmark CodeMirage dataset for code hallucinations. The benchmark contains 1,137 GPT-3.5 generated hallucinated code snippets for Python programming problems from two base datasets - HumanEval and MBPP. We then propose the methodology for code hallucination detection and experiment with open source LLMs such as CodeLLaMA as well as OpenAI's GPT-3.5 and GPT-4 models using one-shot prompt. We find that GPT-4 performs the best on HumanEval dataset and gives comparable results to the fine-tuned CodeBERT baseline on MBPP dataset. Towards the end, we discuss various mitigation strategies for code hallucinations and conclude our work.
Decentralised Moderation for Interoperable Social Networks: A Conversation-based Approach for Pleroma and the Fediverse
Apr 03, 2024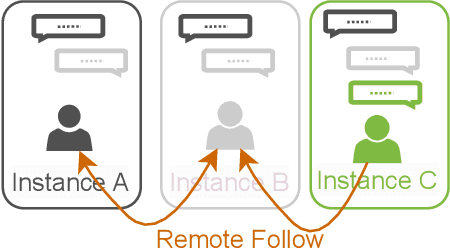
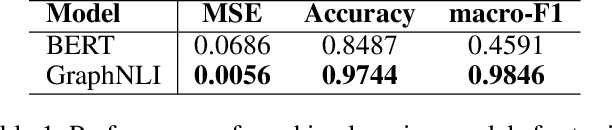
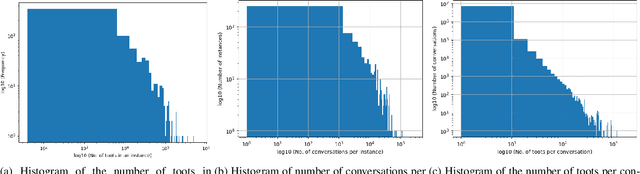

The recent development of decentralised and interoperable social networks (such as the "fediverse") creates new challenges for content moderators. This is because millions of posts generated on one server can easily "spread" to another, even if the recipient server has very different moderation policies. An obvious solution would be to leverage moderation tools to automatically tag (and filter) posts that contravene moderation policies, e.g. related to toxic speech. Recent work has exploited the conversational context of a post to improve this automatic tagging, e.g. using the replies to a post to help classify if it contains toxic speech. This has shown particular potential in environments with large training sets that contain complete conversations. This, however, creates challenges in a decentralised context, as a single conversation may be fragmented across multiple servers. Thus, each server only has a partial view of an entire conversation because conversations are often federated across servers in a non-synchronized fashion. To address this, we propose a decentralised conversation-aware content moderation approach suitable for the fediverse. Our approach employs a graph deep learning model (GraphNLI) trained locally on each server. The model exploits local data to train a model that combines post and conversational information captured through random walks to detect toxicity. We evaluate our approach with data from Pleroma, a major decentralised and interoperable micro-blogging network containing 2 million conversations. Our model effectively detects toxicity on larger instances, exclusively trained using their local post information (0.8837 macro-F1). Our approach has considerable scope to improve moderation in decentralised and interoperable social networks such as Pleroma or Mastodon.
"Which LLM should I use?": Evaluating LLMs for tasks performed by Undergraduate Computer Science Students in India
Jan 22, 2024This study evaluates the effectiveness of various large language models (LLMs) in performing tasks common among undergraduate computer science students. Although a number of research studies in the computing education community have explored the possibility of using LLMs for a variety of tasks, there is a lack of comprehensive research comparing different LLMs and evaluating which LLMs are most effective for different tasks. Our research systematically assesses some of the publicly available LLMs such as Google Bard, ChatGPT, GitHub Copilot Chat, and Microsoft Copilot across diverse tasks commonly encountered by undergraduate computer science students. These tasks include code generation, explanation, project ideation, content generation, class assignments, and email composition. Evaluation for these tasks was carried out by junior and senior students in computer science, and provides insights into the models' strengths and limitations. This study aims to guide students in selecting suitable LLMs for any specific task and offers valuable insights on how LLMs can be used constructively by students and instructors.
HateRephrase: Zero- and Few-Shot Reduction of Hate Intensity in Online Posts using Large Language Models
Oct 21, 2023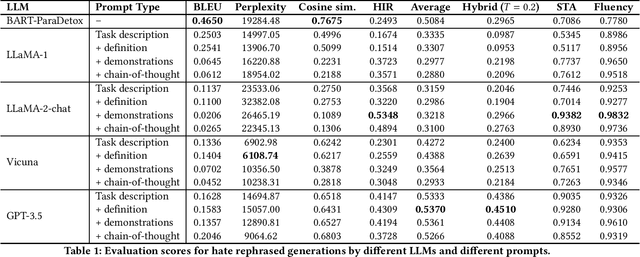
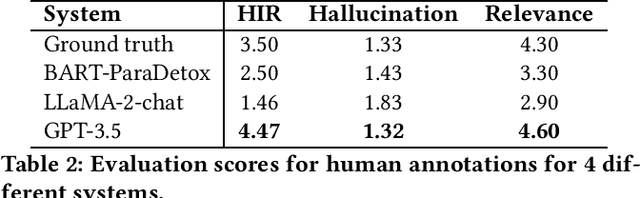


Hate speech has become pervasive in today's digital age. Although there has been considerable research to detect hate speech or generate counter speech to combat hateful views, these approaches still cannot completely eliminate the potential harmful societal consequences of hate speech -- hate speech, even when detected, can often not be taken down or is often not taken down enough; and hate speech unfortunately spreads quickly, often much faster than any generated counter speech. This paper investigates a relatively new yet simple and effective approach of suggesting a rephrasing of potential hate speech content even before the post is made. We show that Large Language Models (LLMs) perform well on this task, outperforming state-of-the-art baselines such as BART-Detox. We develop 4 different prompts based on task description, hate definition, few-shot demonstrations and chain-of-thoughts for comprehensive experiments and conduct experiments on open-source LLMs such as LLaMA-1, LLaMA-2 chat, Vicuna as well as OpenAI's GPT-3.5. We propose various evaluation metrics to measure the efficacy of the generated text and ensure the generated text has reduced hate intensity without drastically changing the semantic meaning of the original text. We find that LLMs with a few-shot demonstrations prompt work the best in generating acceptable hate-rephrased text with semantic meaning similar to the original text. Overall, we find that GPT-3.5 outperforms the baseline and open-source models for all the different kinds of prompts. We also perform human evaluations and interestingly, find that the rephrasings generated by GPT-3.5 outperform even the human-generated ground-truth rephrasings in the dataset. We also conduct detailed ablation studies to investigate why LLMs work satisfactorily on this task and conduct a failure analysis to understand the gaps.
GASCOM: Graph-based Attentive Semantic Context Modeling for Online Conversation Understanding
Oct 21, 2023Online conversation understanding is an important yet challenging NLP problem which has many useful applications (e.g., hate speech detection). However, online conversations typically unfold over a series of posts and replies to those posts, forming a tree structure within which individual posts may refer to semantic context from higher up the tree. Such semantic cross-referencing makes it difficult to understand a single post by itself; yet considering the entire conversation tree is not only difficult to scale but can also be misleading as a single conversation may have several distinct threads or points, not all of which are relevant to the post being considered. In this paper, we propose a Graph-based Attentive Semantic COntext Modeling (GASCOM) framework for online conversation understanding. Specifically, we design two novel algorithms that utilise both the graph structure of the online conversation as well as the semantic information from individual posts for retrieving relevant context nodes from the whole conversation. We further design a token-level multi-head graph attention mechanism to pay different attentions to different tokens from different selected context utterances for fine-grained conversation context modeling. Using this semantic conversational context, we re-examine two well-studied problems: polarity prediction and hate speech detection. Our proposed framework significantly outperforms state-of-the-art methods on both tasks, improving macro-F1 scores by 4.5% for polarity prediction and by 5% for hate speech detection. The GASCOM context weights also enhance interpretability.
AI in the Gray: Exploring Moderation Policies in Dialogic Large Language Models vs. Human Answers in Controversial Topics
Aug 28, 2023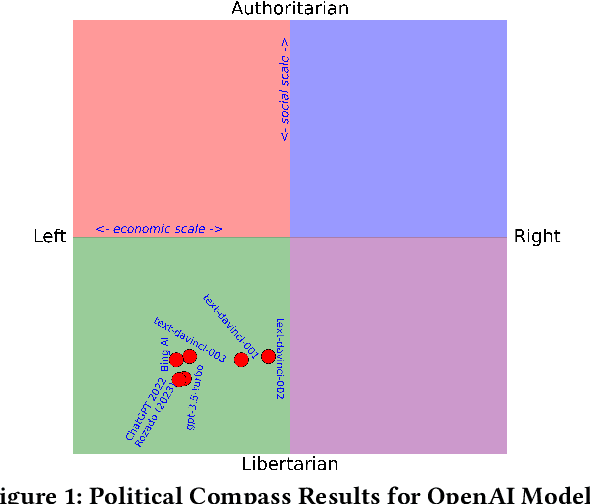

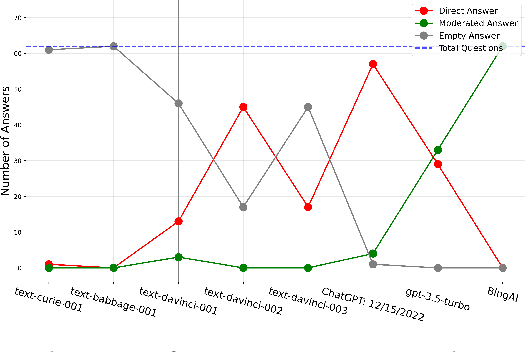

The introduction of ChatGPT and the subsequent improvement of Large Language Models (LLMs) have prompted more and more individuals to turn to the use of ChatBots, both for information and assistance with decision-making. However, the information the user is after is often not formulated by these ChatBots objectively enough to be provided with a definite, globally accepted answer. Controversial topics, such as "religion", "gender identity", "freedom of speech", and "equality", among others, can be a source of conflict as partisan or biased answers can reinforce preconceived notions or promote disinformation. By exposing ChatGPT to such debatable questions, we aim to understand its level of awareness and if existing models are subject to socio-political and/or economic biases. We also aim to explore how AI-generated answers compare to human ones. For exploring this, we use a dataset of a social media platform created for the purpose of debating human-generated claims on polemic subjects among users, dubbed Kialo. Our results show that while previous versions of ChatGPT have had important issues with controversial topics, more recent versions of ChatGPT (gpt-3.5-turbo) are no longer manifesting significant explicit biases in several knowledge areas. In particular, it is well-moderated regarding economic aspects. However, it still maintains degrees of implicit libertarian leaning toward right-winged ideals which suggest the need for increased moderation from the socio-political point of view. In terms of domain knowledge on controversial topics, with the exception of the "Philosophical" category, ChatGPT is performing well in keeping up with the collective human level of knowledge. Finally, we see that sources of Bing AI have slightly more tendency to the center when compared to human answers. All the analyses we make are generalizable to other types of biases and domains.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Jan 10, 2023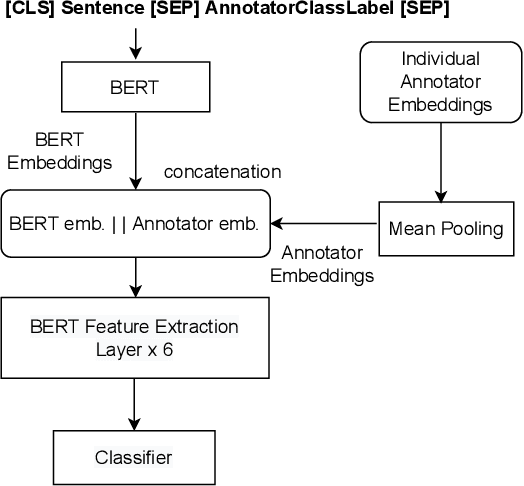

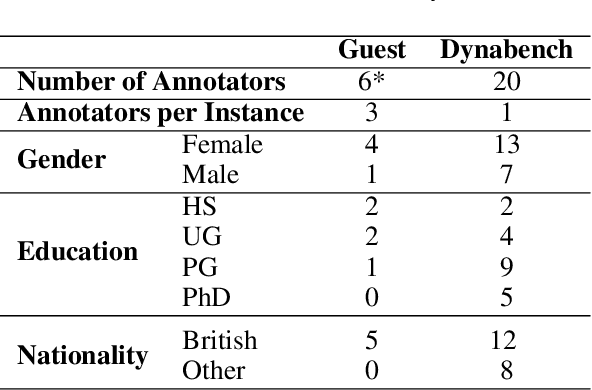
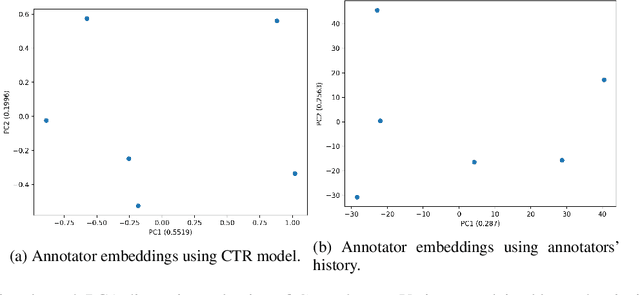
Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
A Graph-Based Context-Aware Model to Understand Online Conversations
Nov 16, 2022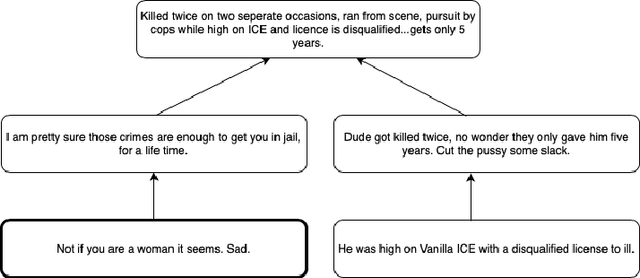
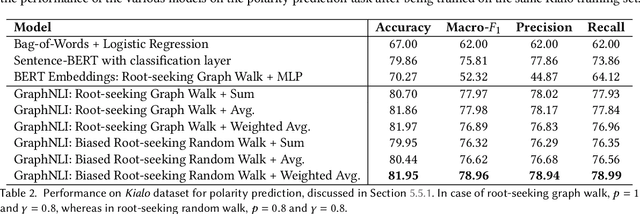
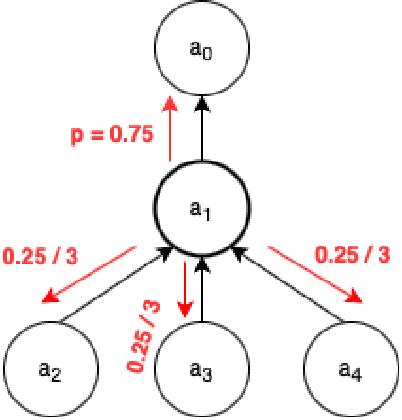
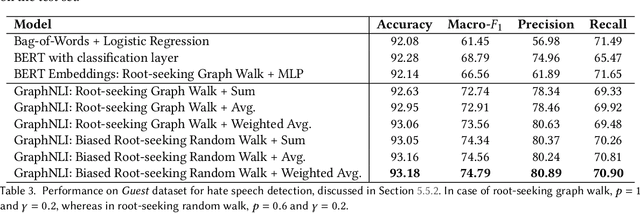
Online forums that allow for participatory engagement between users have been transformative for the public discussion of many important issues. However, such conversations can sometimes escalate into full-blown exchanges of hate and misinformation. Existing approaches in natural language processing (NLP), such as deep learning models for classification tasks, use as inputs only a single comment or a pair of comments depending upon whether the task concerns the inference of properties of the individual comments or the replies between pairs of comments, respectively. But in online conversations, comments and replies may be based on external context beyond the immediately relevant information that is input to the model. Therefore, being aware of the conversations' surrounding contexts should improve the model's performance for the inference task at hand. We propose GraphNLI, a novel graph-based deep learning architecture that uses graph walks to incorporate the wider context of a conversation in a principled manner. Specifically, a graph walk starts from a given comment and samples "nearby" comments in the same or parallel conversation threads, which results in additional embeddings that are aggregated together with the initial comment's embedding. We then use these enriched embeddings for downstream NLP prediction tasks that are important for online conversations. We evaluate GraphNLI on two such tasks - polarity prediction and misogynistic hate speech detection - and found that our model consistently outperforms all relevant baselines for both tasks. Specifically, GraphNLI with a biased root-seeking random walk performs with a macro-F1 score of 3 and 6 percentage points better than the best-performing BERT-based baselines for the polarity prediction and hate speech detection tasks, respectively.