 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoMem: Towards Capable On-Device Memory Agents via Dual-Space Distillation
Jun 29, 2026Large Language Model (LLM)-based agents can solve complex procedural tasks by interacting with environments over multiple turns, but this ability typically depends on large models, long contexts, and repeated inference calls. This makes advanced memory-augmented agents difficult to deploy on resource-constrained devices. We introduce DuoMem, a dual-space distillation framework that transfers procedural problem-solving ability from a large teacher model to compact student models. DuoMem distils in two complementary spaces: (1)context-space distillation, which replaces student-generated memories with higher-quality teacher-generated procedural memories prepended to the student's input, and (2)parameter-space distillation, which fine-tunes lightweight LoRA adapters on successful teacher trajectories. Evaluated on ALFWorld, a challenging embodied decision-making benchmark, DuoMem boosts a 4B-parameter model from 4.3% to 77.9% task success rate, closing most of the gap to a 72B teacher model (87.1%), while adding fewer than 10M trainable parameters and only a few megabytes of pre-computed teacher memories. Moreover, the DuoMem-enhanced 4B model completes tasks over 3x faster than the 72B teacher in wall-clock time, making it viable for real-time edge deployment, which would be challenging for the teacher.Extensive ablations across eight models spanning 2B-72B parameters reveal that both distillation axes contribute complementary
CG-TTRL: Context-Guided Test-Time Reinforcement Learning for On-Device Large Language Models
Nov 09, 2025Test-time Reinforcement Learning (TTRL) has shown promise in adapting foundation models for complex tasks at test-time, resulting in large performance improvements. TTRL leverages an elegant two-phase sampling strategy: first, multi-sampling derives a pseudo-label via majority voting, while subsequent downsampling and reward-based fine-tuning encourages the model to explore and learn diverse valid solutions, with the pseudo-label modulating the reward signal. Meanwhile, in-context learning has been widely explored at inference time and demonstrated the ability to enhance model performance without weight updates. However, TTRL's two-phase sampling strategy under-utilizes contextual guidance, which can potentially improve pseudo-label accuracy in the initial exploitation phase while regulating exploration in the second. To address this, we propose context-guided TTRL (CG-TTRL), integrating context dynamically into both sampling phases and propose a method for efficient context selection for on-device applications. Our evaluations on mathematical and scientific QA benchmarks show CG-TTRL outperforms TTRL (e.g. additional 7% relative accuracy improvement over TTRL), while boosting efficiency by obtaining strong performance after only a few steps of test-time training (e.g. 8% relative improvement rather than 1% over TTRL after 3 steps).
Multi-MLLM Knowledge Distillation for Out-of-Context News Detection
May 28, 2025Multimodal out-of-context news is a type of misinformation in which the image is used outside of its original context. Many existing works have leveraged multimodal large language models (MLLMs) for detecting out-of-context news. However, observing the limited zero-shot performance of smaller MLLMs, they generally require label-rich fine-tuning and/or expensive API calls to GPT models to improve the performance, which is impractical in low-resource scenarios. In contrast, we aim to improve the performance of small MLLMs in a more label-efficient and cost-effective manner. To this end, we first prompt multiple teacher MLLMs to generate both label predictions and corresponding rationales, which collectively serve as the teachers' knowledge. We then introduce a two-stage knowledge distillation framework to transfer this knowledge to a student MLLM. In Stage 1, we apply LoRA fine-tuning to the student model using all training data. In Stage 2, we further fine-tune the student model using both LoRA fine-tuning and DPO on the data points where teachers' predictions conflict. This two-stage strategy reduces annotation costs and helps the student model uncover subtle patterns in more challenging cases. Experimental results demonstrate that our approach achieves state-of-the-art performance using less than 10% labeled data.
Collaborative Content Moderation in the Fediverse
Jan 10, 2025



The Fediverse, a group of interconnected servers providing a variety of interoperable services (e.g. micro-blogging in Mastodon) has gained rapid popularity. This sudden growth, partly driven by Elon Musk's acquisition of Twitter, has created challenges for administrators though. This paper focuses on one particular challenge: content moderation, e.g. the need to remove spam or hate speech. While centralized platforms like Facebook and Twitter rely on automated tools for moderation, their dependence on massive labeled datasets and specialized infrastructure renders them impractical for decentralized, low-resource settings like the Fediverse. In this work, we design and evaluate FedMod, a collaborative content moderation system based on federated learning. Our system enables servers to exchange parameters of partially trained local content moderation models with similar servers, creating a federated model shared among collaborating servers. FedMod demonstrates robust performance on three different content moderation tasks: harmful content detection, bot content detection, and content warning assignment, achieving average per-server macro-F1 scores of 0.71, 0.73, and 0.58, respectively.
Efficient Solutions For An Intriguing Failure of LLMs: Long Context Window Does Not Mean LLMs Can Analyze Long Sequences Flawlessly
Aug 03, 2024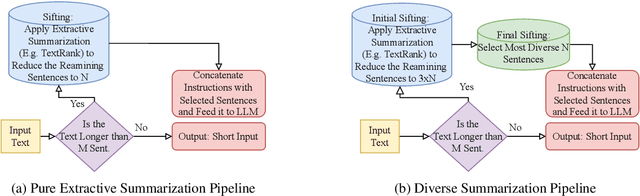
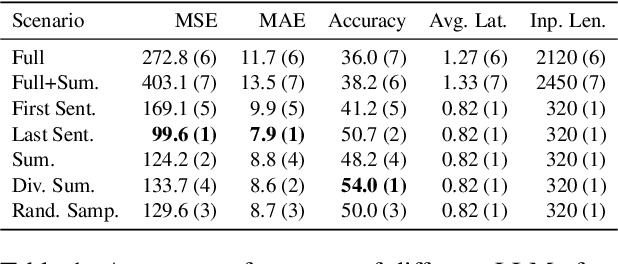
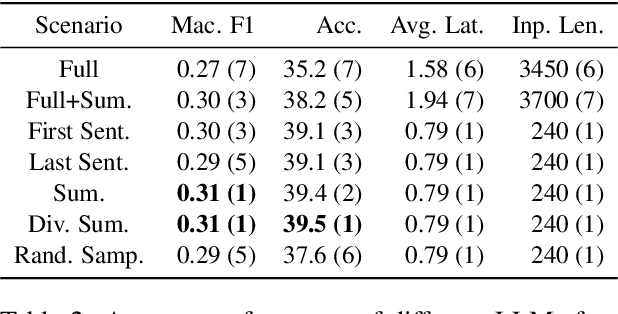
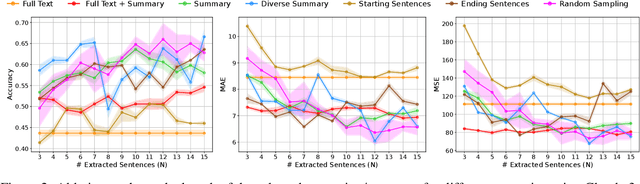
Large Language Models (LLMs) have demonstrated remarkable capabilities in comprehending and analyzing lengthy sequential inputs, owing to their extensive context windows that allow processing millions of tokens in a single forward pass. However, this paper uncovers a surprising limitation: LLMs fall short when handling long input sequences. We investigate this issue using three datasets and two tasks (sentiment analysis and news categorization) across various LLMs, including Claude 3, Gemini Pro, GPT 3.5 Turbo, Llama 3 Instruct, and Mistral Instruct models. To address this limitation, we propose and evaluate ad-hoc solutions that substantially enhance LLMs' performance on long input sequences by up to 50%, while reducing API cost and latency by up to 93% and 50%, respectively.
How Similar Are Elected Politicians and Their Constituents? Quantitative Evidence From Online Social Network
Jul 03, 2024
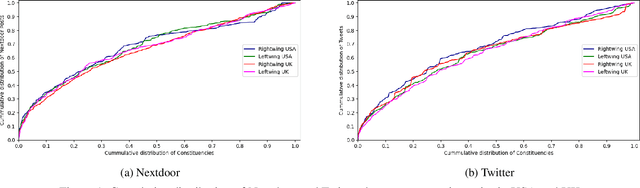
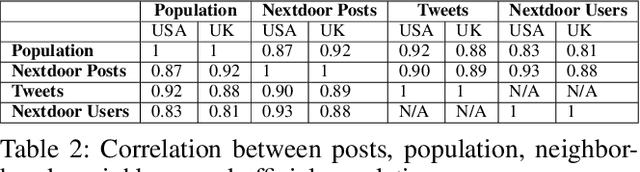
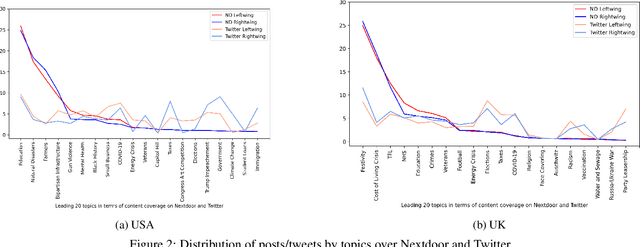
How similar are politicians to those who vote for them? This is a critical question at the heart of democratic representation and particularly relevant at times when political dissatisfaction and populism are on the rise. To answer this question we compare the online discourse of elected politicians and their constituents. We collect a two and a half years (September 2020 - February 2023) constituency-level dataset for USA and UK that includes: (i) the Twitter timelines (5.6 Million tweets) of elected political representatives (595 UK Members of Parliament and 433 USA Representatives), (ii) the Nextdoor posts (21.8 Million posts) of the constituency (98.4% USA and 91.5% UK constituencies). We find that elected politicians tend to be equally similar to their constituents in terms of content and style regardless of whether a constituency elects a right or left-wing politician. The size of the electoral victory and the level of income of a constituency shows a nuanced picture. The narrower the electoral victory, the more similar the style and the more dissimilar the content is. The lower the income of a constituency, the more similar the content is. In terms of style, poorer constituencies tend to have a more similar sentiment and more dissimilar psychological text traits (i.e. measured with LIWC categories).
Learning Domain-Invariant Features for Out-of-Context News Detection
Jun 11, 2024
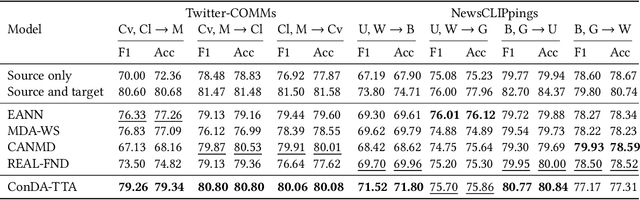
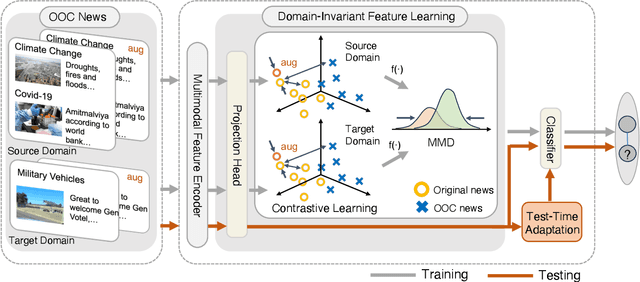
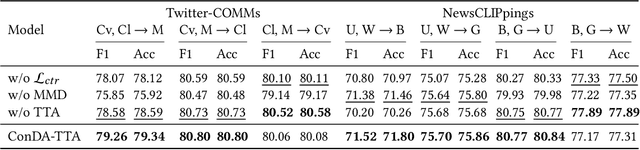
Multimodal out-of-context news is a common type of misinformation on online media platforms. This involves posting a caption, alongside an invalid out-of-context news image. Reflecting its importance, researchers have developed models to detect such misinformation. However, a common limitation of these models is that they only consider the scenario where pre-labeled data is available for each domain, failing to address the out-of-context news detection on unlabeled domains (e.g., unverified news on new topics or agencies). In this work, we therefore focus on domain adaptive out-of-context news detection. In order to effectively adapt the detection model to unlabeled news topics or agencies, we propose ConDA-TTA (Contrastive Domain Adaptation with Test-Time Adaptation) which applies contrastive learning and maximum mean discrepancy (MMD) to learn the domain-invariant feature. In addition, it leverages target domain statistics during test-time to further assist domain adaptation. Experimental results show that our approach outperforms baselines in 5 out of 7 domain adaptation settings on two public datasets, by as much as 2.93% in F1 and 2.08% in accuracy.
Decentralised Moderation for Interoperable Social Networks: A Conversation-based Approach for Pleroma and the Fediverse
Apr 03, 2024
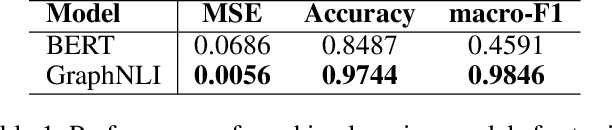

The recent development of decentralised and interoperable social networks (such as the "fediverse") creates new challenges for content moderators. This is because millions of posts generated on one server can easily "spread" to another, even if the recipient server has very different moderation policies. An obvious solution would be to leverage moderation tools to automatically tag (and filter) posts that contravene moderation policies, e.g. related to toxic speech. Recent work has exploited the conversational context of a post to improve this automatic tagging, e.g. using the replies to a post to help classify if it contains toxic speech. This has shown particular potential in environments with large training sets that contain complete conversations. This, however, creates challenges in a decentralised context, as a single conversation may be fragmented across multiple servers. Thus, each server only has a partial view of an entire conversation because conversations are often federated across servers in a non-synchronized fashion. To address this, we propose a decentralised conversation-aware content moderation approach suitable for the fediverse. Our approach employs a graph deep learning model (GraphNLI) trained locally on each server. The model exploits local data to train a model that combines post and conversational information captured through random walks to detect toxicity. We evaluate our approach with data from Pleroma, a major decentralised and interoperable micro-blogging network containing 2 million conversations. Our model effectively detects toxicity on larger instances, exclusively trained using their local post information (0.8837 macro-F1). Our approach has considerable scope to improve moderation in decentralised and interoperable social networks such as Pleroma or Mastodon.
Lady and the Tramp Nextdoor: Online Manifestations of Economic Inequalities in the Nextdoor Social Network
Apr 26, 2023


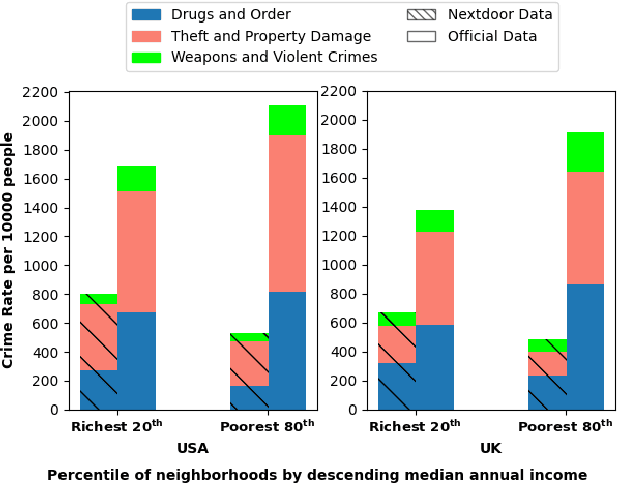
From health to education, income impacts a huge range of life choices. Earlier research has leveraged data from online social networks to study precisely this impact. In this paper, we ask the opposite question: do different levels of income result in different online behaviors? We demonstrate it does. We present the first large-scale study of Nextdoor, a popular location-based social network. We collect 2.6 Million posts from 64,283 neighborhoods in the United States and 3,325 neighborhoods in the United Kingdom, to examine whether online discourse reflects the income and income inequality of a neighborhood. We show that posts from neighborhoods with different incomes indeed differ, e.g. richer neighborhoods have a more positive sentiment and discuss crimes more, even though their actual crime rates are much lower. We then show that user-generated content can predict both income and inequality. We train multiple machine learning models and predict both income (R-squared=0.841) and inequality (R-squared=0.77).
Lon-eå at SemEval-2023 Task 11: A Comparison of\\Activation Functions for Soft and Hard Label Prediction
Mar 04, 2023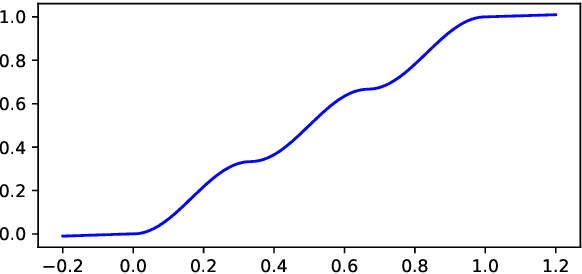



We study the influence of different activation functions in the output layer of deep neural network models for soft and hard label prediction in the learning with disagreement task. In this task, the goal is to quantify the amount of disagreement via predicting soft labels. To predict the soft labels, we use BERT-based preprocessors and encoders and vary the activation function used in the output layer, while keeping other parameters constant. The soft labels are then used for the hard label prediction. The activation functions considered are sigmoid as well as a step-function that is added to the model post-training and a sinusoidal activation function, which is introduced for the first time in this paper.