 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Solutions For An Intriguing Failure of LLMs: Long Context Window Does Not Mean LLMs Can Analyze Long Sequences Flawlessly
Paper and Code
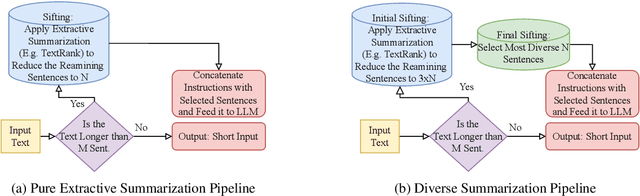
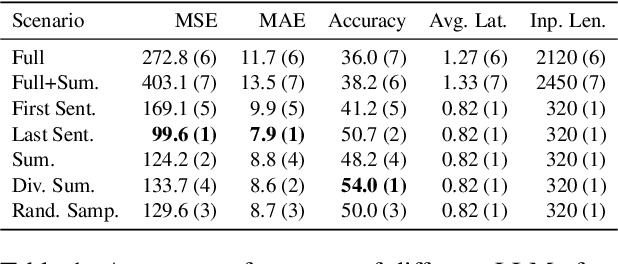
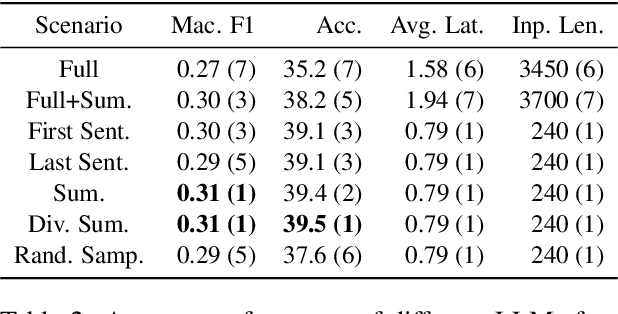
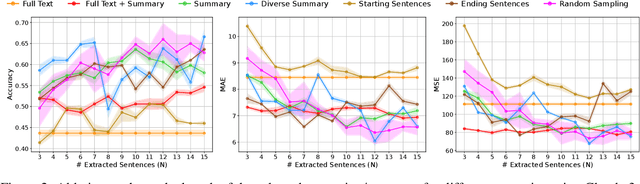
Large Language Models (LLMs) have demonstrated remarkable capabilities in comprehending and analyzing lengthy sequential inputs, owing to their extensive context windows that allow processing millions of tokens in a single forward pass. However, this paper uncovers a surprising limitation: LLMs fall short when handling long input sequences. We investigate this issue using three datasets and two tasks (sentiment analysis and news categorization) across various LLMs, including Claude 3, Gemini Pro, GPT 3.5 Turbo, Llama 3 Instruct, and Mistral Instruct models. To address this limitation, we propose and evaluate ad-hoc solutions that substantially enhance LLMs' performance on long input sequences by up to 50%, while reducing API cost and latency by up to 93% and 50%, respectively.