 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCG-TTRL: Context-Guided Test-Time Reinforcement Learning for On-Device Large Language Models
Nov 09, 2025Test-time Reinforcement Learning (TTRL) has shown promise in adapting foundation models for complex tasks at test-time, resulting in large performance improvements. TTRL leverages an elegant two-phase sampling strategy: first, multi-sampling derives a pseudo-label via majority voting, while subsequent downsampling and reward-based fine-tuning encourages the model to explore and learn diverse valid solutions, with the pseudo-label modulating the reward signal. Meanwhile, in-context learning has been widely explored at inference time and demonstrated the ability to enhance model performance without weight updates. However, TTRL's two-phase sampling strategy under-utilizes contextual guidance, which can potentially improve pseudo-label accuracy in the initial exploitation phase while regulating exploration in the second. To address this, we propose context-guided TTRL (CG-TTRL), integrating context dynamically into both sampling phases and propose a method for efficient context selection for on-device applications. Our evaluations on mathematical and scientific QA benchmarks show CG-TTRL outperforms TTRL (e.g. additional 7% relative accuracy improvement over TTRL), while boosting efficiency by obtaining strong performance after only a few steps of test-time training (e.g. 8% relative improvement rather than 1% over TTRL after 3 steps).
FairJudge: MLLM Judging for Social Attributes and Prompt Image Alignment
Oct 26, 2025Text-to-image (T2I) systems lack simple, reproducible ways to evaluate how well images match prompts and how models treat social attributes. Common proxies -- face classifiers and contrastive similarity -- reward surface cues, lack calibrated abstention, and miss attributes only weakly visible (for example, religion, culture, disability). We present FairJudge, a lightweight protocol that treats instruction-following multimodal LLMs as fair judges. It scores alignment with an explanation-oriented rubric mapped to [-1, 1]; constrains judgments to a closed label set; requires evidence grounded in the visible content; and mandates abstention when cues are insufficient. Unlike CLIP-only pipelines, FairJudge yields accountable, evidence-aware decisions; unlike mitigation that alters generators, it targets evaluation fairness. We evaluate gender, race, and age on FairFace, PaTA, and FairCoT; extend to religion, culture, and disability; and assess profession correctness and alignment on IdenProf, FairCoT-Professions, and our new DIVERSIFY-Professions. We also release DIVERSIFY, a 469-image corpus of diverse, non-iconic scenes. Across datasets, judge models outperform contrastive and face-centric baselines on demographic prediction and improve mean alignment while maintaining high profession accuracy, enabling more reliable, reproducible fairness audits.
A Computational Framework to Identify Self-Aspects in Text
Jul 17, 2025This Ph.D. proposal introduces a plan to develop a computational framework to identify Self-aspects in text. The Self is a multifaceted construct and it is reflected in language. While it is described across disciplines like cognitive science and phenomenology, it remains underexplored in natural language processing (NLP). Many of the aspects of the Self align with psychological and other well-researched phenomena (e.g., those related to mental health), highlighting the need for systematic NLP-based analysis. In line with this, we plan to introduce an ontology of Self-aspects and a gold-standard annotated dataset. Using this foundation, we will develop and evaluate conventional discriminative models, generative large language models, and embedding-based retrieval approaches against four main criteria: interpretability, ground-truth adherence, accuracy, and computational efficiency. Top-performing models will be applied in case studies in mental health and empirical phenomenology.
Improving Factuality for Dialogue Response Generation via Graph-Based Knowledge Augmentation
Jun 14, 2025Large Language Models (LLMs) succeed in many natural language processing tasks. However, their tendency to hallucinate - generate plausible but inconsistent or factually incorrect text - can cause problems in certain tasks, including response generation in dialogue. To mitigate this issue, knowledge-augmented methods have shown promise in reducing hallucinations. Here, we introduce a novel framework designed to enhance the factuality of dialogue response generation, as well as an approach to evaluate dialogue factual accuracy. Our framework combines a knowledge triple retriever, a dialogue rewrite, and knowledge-enhanced response generation to produce more accurate and grounded dialogue responses. To further evaluate generated responses, we propose a revised fact score that addresses the limitations of existing fact-score methods in dialogue settings, providing a more reliable assessment of factual consistency. We evaluate our methods using different baselines on the OpendialKG and HybriDialogue datasets. Our methods significantly improve factuality compared to other graph knowledge-augmentation baselines, including the state-of-the-art G-retriever. The code will be released on GitHub.
Breaking Language Barriers or Reinforcing Bias? A Study of Gender and Racial Disparities in Multilingual Contrastive Vision Language Models
May 20, 2025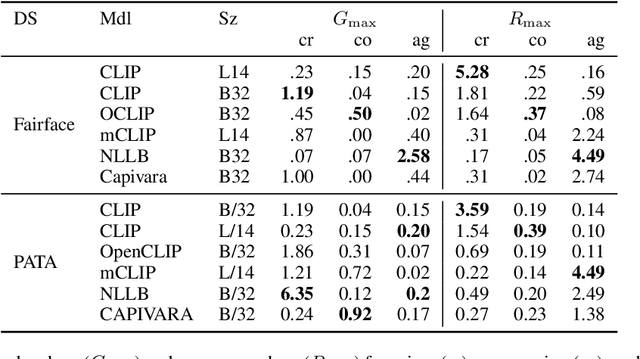
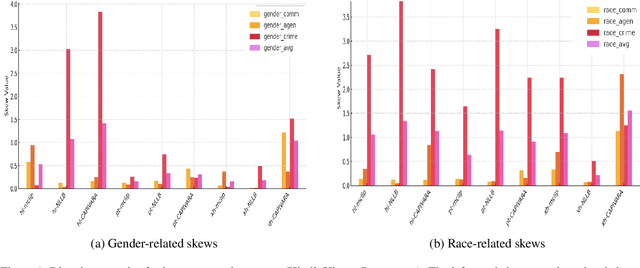
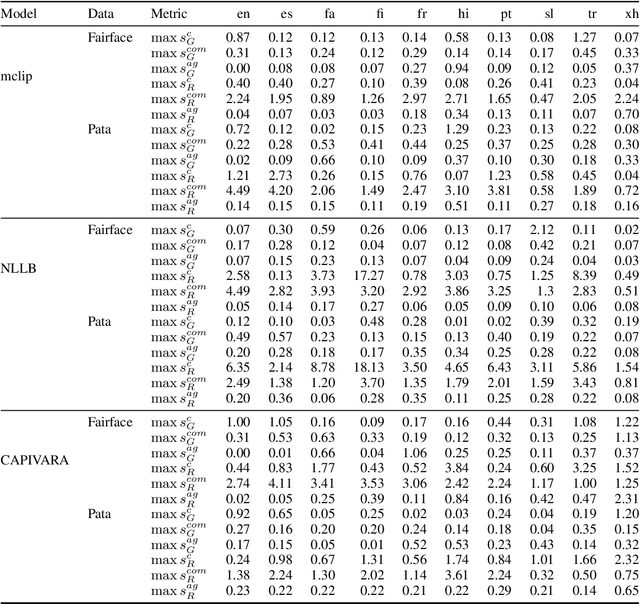
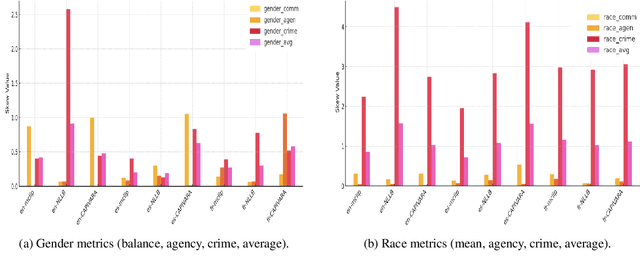
Multilingual vision-language models promise universal image-text retrieval, yet their social biases remain under-explored. We present the first systematic audit of three public multilingual CLIP checkpoints -- M-CLIP, NLLB-CLIP, and CAPIVARA-CLIP -- across ten languages that vary in resource availability and grammatical gender. Using balanced subsets of \textsc{FairFace} and the \textsc{PATA} stereotype suite in a zero-shot setting, we quantify race and gender bias and measure stereotype amplification. Contrary to the assumption that multilinguality mitigates bias, every model exhibits stronger gender bias than its English-only baseline. CAPIVARA-CLIP shows its largest biases precisely in the low-resource languages it targets, while the shared cross-lingual encoder of NLLB-CLIP transports English gender stereotypes into gender-neutral languages; loosely coupled encoders largely avoid this transfer. Highly gendered languages consistently magnify all measured bias types, but even gender-neutral languages remain vulnerable when cross-lingual weight sharing imports foreign stereotypes. Aggregated metrics conceal language-specific ``hot spots,'' underscoring the need for fine-grained, language-aware bias evaluation in future multilingual vision-language research.
Recent Trends in Linear Text Segmentation: a Survey
Nov 25, 2024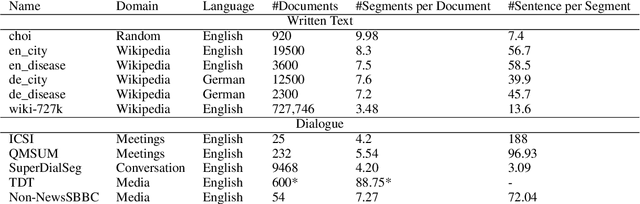
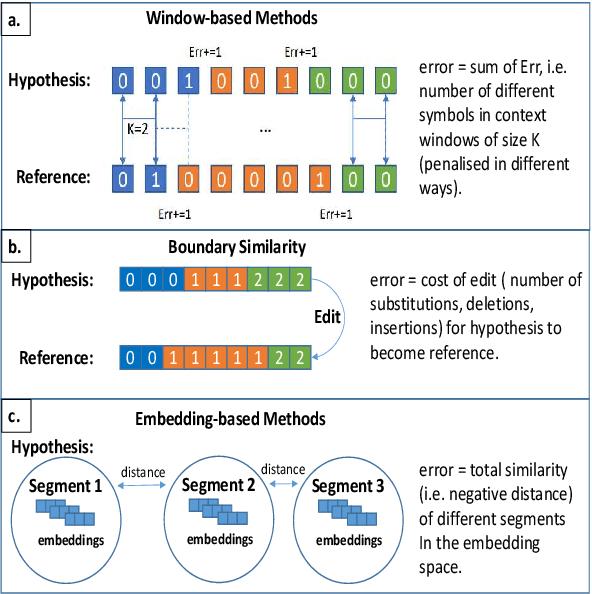
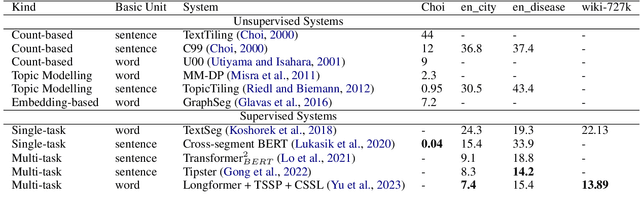
Linear Text Segmentation is the task of automatically tagging text documents with topic shifts, i.e. the places in the text where the topics change. A well-established area of research in Natural Language Processing, drawing from well-understood concepts in linguistic and computational linguistic research, the field has recently seen a lot of interest as a result of the surge of text, video, and audio available on the web, which in turn require ways of summarising and categorizing the mole of content for which linear text segmentation is a fundamental step. In this survey, we provide an extensive overview of current advances in linear text segmentation, describing the state of the art in terms of resources and approaches for the task. Finally, we highlight the limitations of available resources and of the task itself, while indicating ways forward based on the most recent literature and under-explored research directions.
Evaluating and explaining training strategies for zero-shot cross-lingual news sentiment analysis
Sep 30, 2024
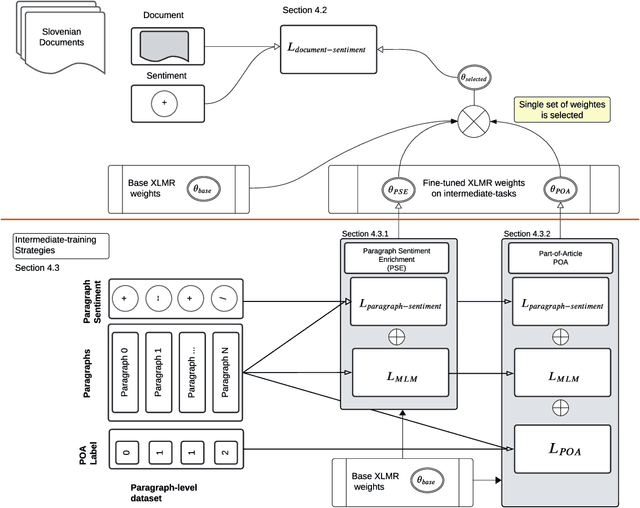
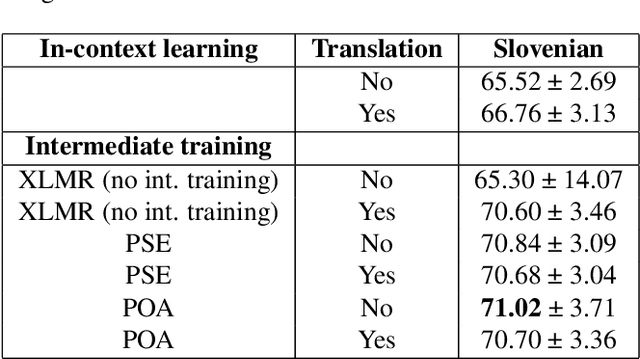
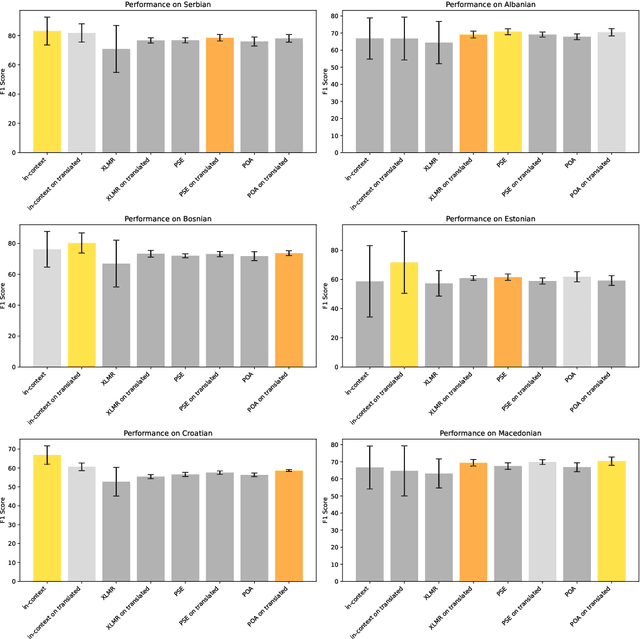
We investigate zero-shot cross-lingual news sentiment detection, aiming to develop robust sentiment classifiers that can be deployed across multiple languages without target-language training data. We introduce novel evaluation datasets in several less-resourced languages, and experiment with a range of approaches including the use of machine translation; in-context learning with large language models; and various intermediate training regimes including a novel task objective, POA, that leverages paragraph-level information. Our results demonstrate significant improvements over the state of the art, with in-context learning generally giving the best performance, but with the novel POA approach giving a competitive alternative with much lower computational overhead. We also show that language similarity is not in itself sufficient for predicting the success of cross-lingual transfer, but that similarity in semantic content and structure can be equally important.
ClarQ-LLM: A Benchmark for Models Clarifying and Requesting Information in Task-Oriented Dialog
Sep 09, 2024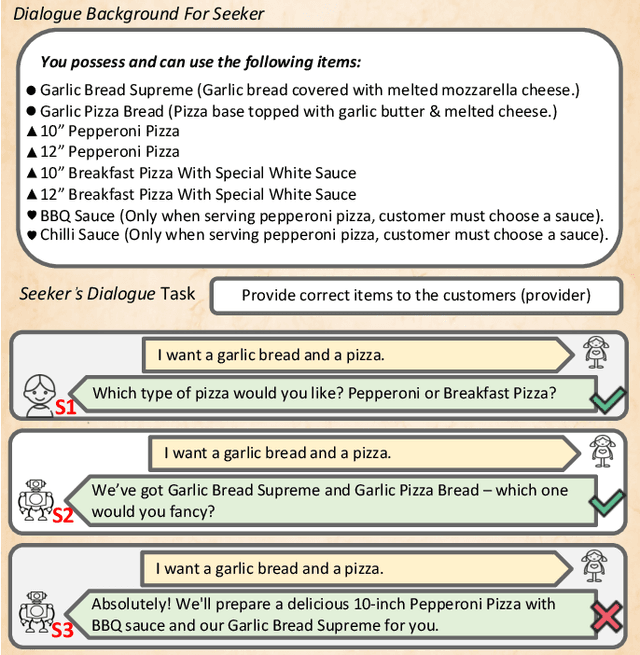



We introduce ClarQ-LLM, an evaluation framework consisting of bilingual English-Chinese conversation tasks, conversational agents and evaluation metrics, designed to serve as a strong benchmark for assessing agents' ability to ask clarification questions in task-oriented dialogues. The benchmark includes 31 different task types, each with 10 unique dialogue scenarios between information seeker and provider agents. The scenarios require the seeker to ask questions to resolve uncertainty and gather necessary information to complete tasks. Unlike traditional benchmarks that evaluate agents based on fixed dialogue content, ClarQ-LLM includes a provider conversational agent to replicate the original human provider in the benchmark. This allows both current and future seeker agents to test their ability to complete information gathering tasks through dialogue by directly interacting with our provider agent. In tests, LLAMA3.1 405B seeker agent managed a maximum success rate of only 60.05\%, showing that ClarQ-LLM presents a strong challenge for future research.
Efficient Solutions For An Intriguing Failure of LLMs: Long Context Window Does Not Mean LLMs Can Analyze Long Sequences Flawlessly
Aug 03, 2024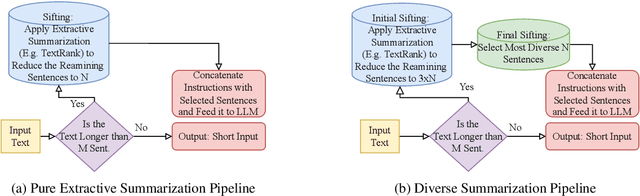
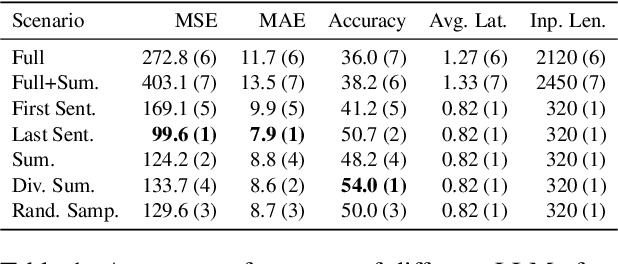
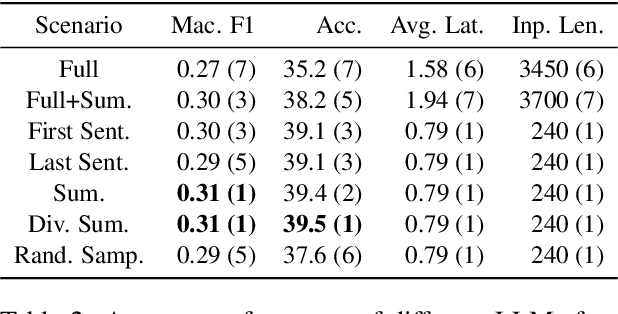
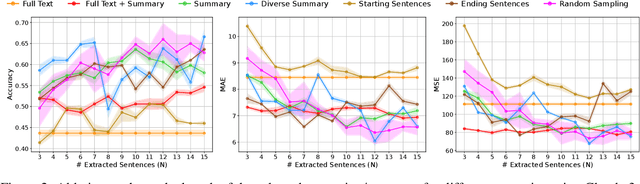
Large Language Models (LLMs) have demonstrated remarkable capabilities in comprehending and analyzing lengthy sequential inputs, owing to their extensive context windows that allow processing millions of tokens in a single forward pass. However, this paper uncovers a surprising limitation: LLMs fall short when handling long input sequences. We investigate this issue using three datasets and two tasks (sentiment analysis and news categorization) across various LLMs, including Claude 3, Gemini Pro, GPT 3.5 Turbo, Llama 3 Instruct, and Mistral Instruct models. To address this limitation, we propose and evaluate ad-hoc solutions that substantially enhance LLMs' performance on long input sequences by up to 50%, while reducing API cost and latency by up to 93% and 50%, respectively.
Multimodal Machine Learning in Mental Health: A Survey of Data, Algorithms, and Challenges
Jul 23, 2024
The application of machine learning (ML) in detecting, diagnosing, and treating mental health disorders is garnering increasing attention. Traditionally, research has focused on single modalities, such as text from clinical notes, audio from speech samples, or video of interaction patterns. Recently, multimodal ML, which combines information from multiple modalities, has demonstrated significant promise in offering novel insights into human behavior patterns and recognizing mental health symptoms and risk factors. Despite its potential, multimodal ML in mental health remains an emerging field, facing several complex challenges before practical applications can be effectively developed. This survey provides a comprehensive overview of the data availability and current state-of-the-art multimodal ML applications for mental health. It discusses key challenges that must be addressed to advance the field. The insights from this survey aim to deepen the understanding of the potential and limitations of multimodal ML in mental health, guiding future research and development in this evolving domain.