 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Encoder Depth: Pruning Whisper and LoRA Fine-Tuning in SLAM-ASR
Mar 30, 2026Automatic speech recognition (ASR) has advanced rapidly in recent years, driven by large-scale pretrained models and end-to-end architectures such as SLAM-ASR. A key component of SLAM-ASR systems is the Whisper speech encoder, which provides robust acoustic representations. While model pruning has been explored for the full Whisper encoder-decoder architecture, its impact within the SLAM-ASR setting remains under-investigated. In this work, we analyze the effects of layer pruning in the Whisper encoder when used as the acoustic backbone of SLAM-ASR. We further examine the extent to which LoRA-based fine-tuning can recover performance degradation caused by pruning. Experiments conducted across three Whisper variants (Small, Medium, Large-v2), three languages representing distinct resource levels (Danish, Dutch, English), and over 200 training runs demonstrate that pruning two encoder layers causes only 2-4% WER degradation, and that combining this pruning with LoRA adaptation consistently outperforms the unpruned baseline while reducing total parameters by 7-14%. Moreover, our error analysis reveals that LoRA primarily compensates through the language model's linguistic priors, reducing total word errors by 11-21% for Dutch and English, with substitutions and deletions showing the largest reductions. However, for low-resource Danish, the reduction is smaller (4-7%), and LoRA introduces increased insertion errors, indicating that compensation effectiveness depends on the LLM's pre-existing language proficiency and available training data.
OasisSimp: An Open-source Asian-English Sentence Simplification Dataset
Mar 14, 2026Sentence simplification aims to make complex text more accessible by reducing linguistic complexity while preserving the original meaning. However, progress in this area remains limited for mid-resource and low-resource languages due to the scarcity of high-quality data. To address this gap, we introduce the OasisSimp dataset, a multilingual dataset for sentence-level simplification covering five languages: English, Sinhala, Tamil, Pashto, and Thai. Among these, no prior sentence simplification datasets exist for Thai, Pashto, and Tamil, while limited data is available for Sinhala. Each language simplification dataset was created by trained annotators who followed detailed guidelines to simplify sentences while maintaining meaning, fluency, and grammatical correctness. We evaluate eight open-weight multilingual Large Language Models (LLMs) on the OasisSimp dataset and observe substantial performance disparities between high-resource and low-resource languages, highlighting the simplification challenges in multilingual settings. The OasisSimp dataset thus provides both a valuable multilingual resource and a challenging benchmark, revealing the limitations of current LLM-based simplification methods and paving the way for future research in low-resource sentence simplification. The dataset is available at https://OasisSimpDataset.github.io/.
Language Family Matters: Evaluating LLM-Based ASR Across Linguistic Boundaries
Jan 26, 2026Large Language Model (LLM)-powered Automatic Speech Recognition (ASR) systems achieve strong performance with limited resources by linking a frozen speech encoder to a pretrained LLM via a lightweight connector. Prior work trains a separate connector per language, overlooking linguistic relatedness. We propose an efficient and novel connector-sharing strategy based on linguistic family membership, enabling one connector per family, and empirically validate its effectiveness across two multilingual LLMs and two real-world corpora spanning curated and crowd-sourced speech. Our results show that family-based connectors reduce parameter count while improving generalization across domains, offering a practical and scalable strategy for multilingual ASR deployment.
SiTSE: Sinhala Text Simplification Dataset and Evaluation
Dec 02, 2024



Text Simplification is a task that has been minimally explored for low-resource languages. Consequently, there are only a few manually curated datasets. In this paper, we present a human curated sentence-level text simplification dataset for the Sinhala language. Our evaluation dataset contains 1,000 complex sentences and corresponding 3,000 simplified sentences produced by three different human annotators. We model the text simplification task as a zero-shot and zero resource sequence-to-sequence (seq-seq) task on the multilingual language models mT5 and mBART. We exploit auxiliary data from related seq-seq tasks and explore the possibility of using intermediate task transfer learning (ITTL). Our analysis shows that ITTL outperforms the previously proposed zero-resource methods for text simplification. Our findings also highlight the challenges in evaluating text simplification systems, and support the calls for improved metrics for measuring the quality of automated text simplification systems that would suit low-resource languages as well. Our code and data are publicly available: https://github.com/brainsharks-fyp17/Sinhala-Text-Simplification-Dataset-and-Evaluation
CoRAL: a Context-aware Croatian Abusive Language Dataset
Nov 11, 2022



In light of unprecedented increases in the popularity of the internet and social media, comment moderation has never been a more relevant task. Semi-automated comment moderation systems greatly aid human moderators by either automatically classifying the examples or allowing the moderators to prioritize which comments to consider first. However, the concept of inappropriate content is often subjective, and such content can be conveyed in many subtle and indirect ways. In this work, we propose CoRAL -- a language and culturally aware Croatian Abusive dataset covering phenomena of implicitness and reliance on local and global context. We show experimentally that current models degrade when comments are not explicit and further degrade when language skill and context knowledge are required to interpret the comment.
Not All Comments are Equal: Insights into Comment Moderation from a Topic-Aware Model
Sep 21, 2021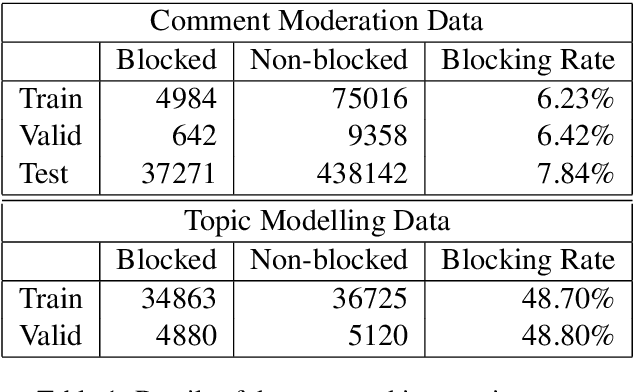
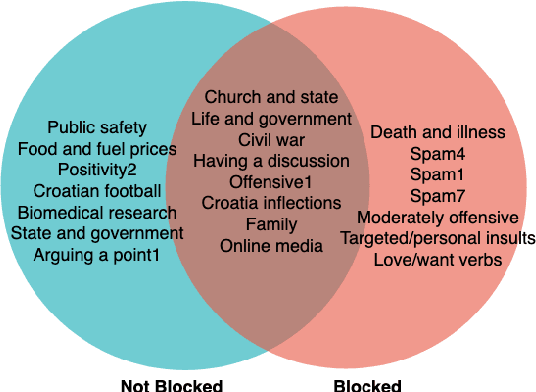
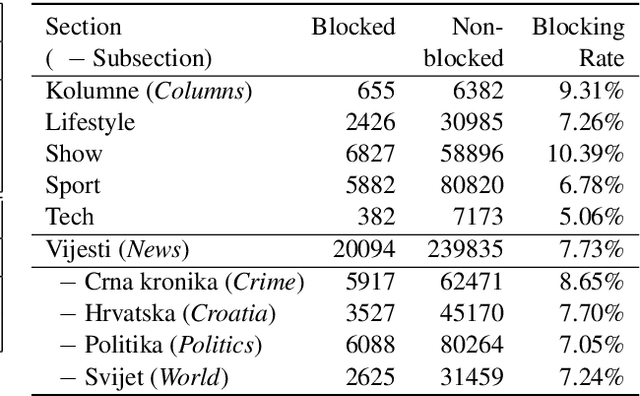
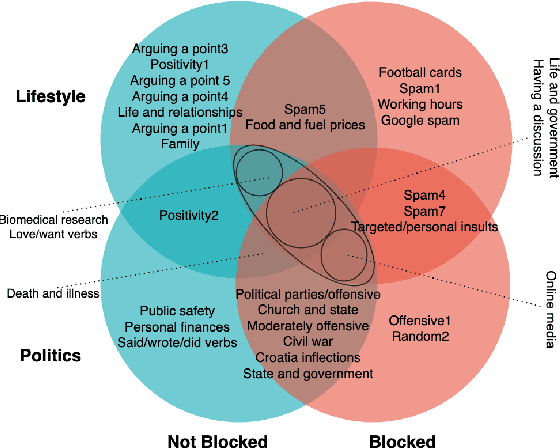
Moderation of reader comments is a significant problem for online news platforms. Here, we experiment with models for automatic moderation, using a dataset of comments from a popular Croatian newspaper. Our analysis shows that while comments that violate the moderation rules mostly share common linguistic and thematic features, their content varies across the different sections of the newspaper. We therefore make our models topic-aware, incorporating semantic features from a topic model into the classification decision. Our results show that topic information improves the performance of the model, increases its confidence in correct outputs, and helps us understand the model's outputs.
Neural Machine Translation for Low-Resource Languages: A Survey
Jun 29, 2021
Neural Machine Translation (NMT) has seen a tremendous spurt of growth in less than ten years, and has already entered a mature phase. While considered as the most widely used solution for Machine Translation, its performance on low-resource language pairs still remains sub-optimal compared to the high-resource counterparts, due to the unavailability of large parallel corpora. Therefore, the implementation of NMT techniques for low-resource language pairs has been receiving the spotlight in the recent NMT research arena, thus leading to a substantial amount of research reported on this topic. This paper presents a detailed survey of research advancements in low-resource language NMT (LRL-NMT), along with a quantitative analysis aimed at identifying the most popular solutions. Based on our findings from reviewing previous work, this survey paper provides a set of guidelines to select the possible NMT technique for a given LRL data setting. It also presents a holistic view of the LRL-NMT research landscape and provides a list of recommendations to further enhance the research efforts on LRL-NMT.
Evaluating the Representational Hub of Language and Vision Models
Apr 12, 2019

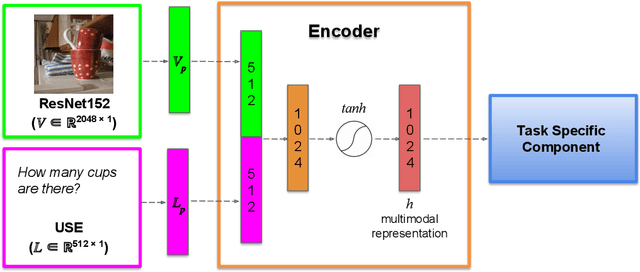
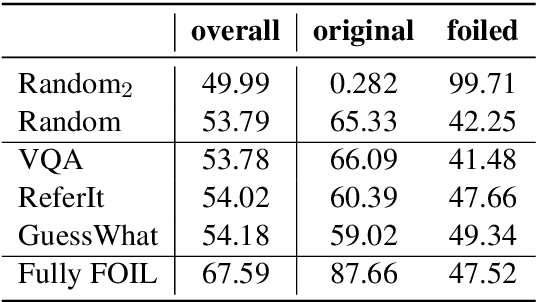
The multimodal models used in the emerging field at the intersection of computational linguistics and computer vision implement the bottom-up processing of the `Hub and Spoke' architecture proposed in cognitive science to represent how the brain processes and combines multi-sensory inputs. In particular, the Hub is implemented as a neural network encoder. We investigate the effect on this encoder of various vision-and-language tasks proposed in the literature: visual question answering, visual reference resolution, and visually grounded dialogue. To measure the quality of the representations learned by the encoder, we use two kinds of analyses. First, we evaluate the encoder pre-trained on the different vision-and-language tasks on an existing diagnostic task designed to assess multimodal semantic understanding. Second, we carry out a battery of analyses aimed at studying how the encoder merges and exploits the two modalities.
Jointly Learning to See, Ask, and GuessWhat
Sep 10, 2018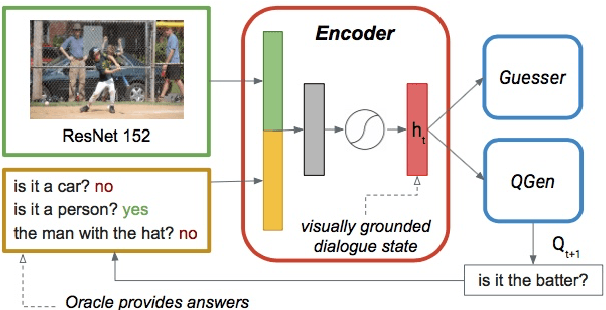
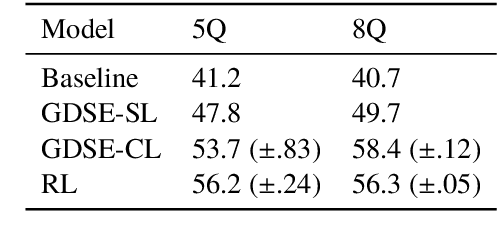
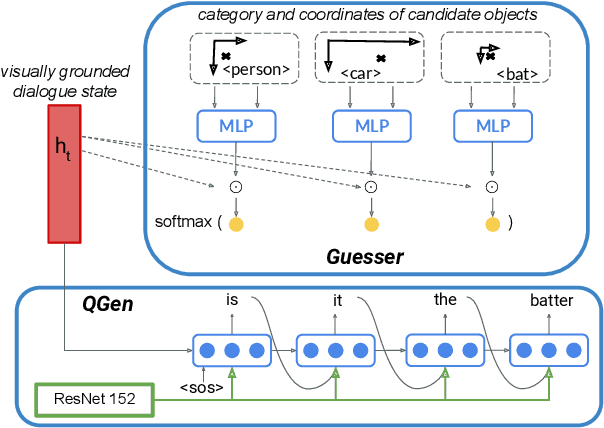
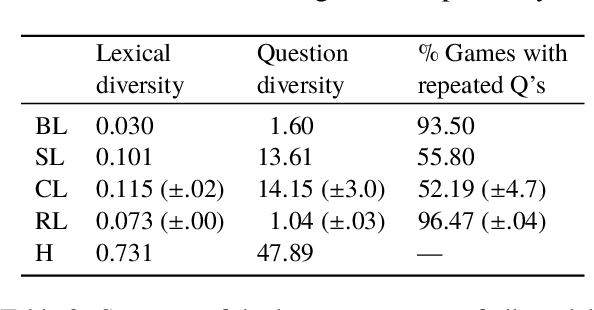
We are interested in understanding how the ability to ground language in vision interacts with other abilities at play in dialogue, such as asking a series of questions to obtain the necessary information to perform a certain task. With this aim, we develop a Questioner agent in the context of the GuessWhat?! game. Our model exploits a neural network architecture to build a continuous representation of the dialogue state that integrates information from the visual and linguistic modalities and conditions future action. To play the GuessWhat?! game, the Questioner agent has to be able to do both, ask questions and guess a target object in the visual environment. In our architecture, these two capabilities are considered jointly as a supervised multi-task learning problem, to which cooperative learning can be further applied. We show that the introduction of our new architecture combined with these learning regimes yields an increase of 19.5% in task success accuracy with respect to a baseline model that treats submodules independently. With this increase, we reach an accuracy comparable to state-of-the-art models that use reinforcement learning, with the advantage that our architecture is entirely differentiable and thus easier to train. This suggests that combining our approach with reinforcement learning could lead to further improvements in the future. Finally, we present a range of analyses that examine the quality of the dialogues and shed light on the internal dynamics of the model.
Ask No More: Deciding when to guess in referential visual dialogue
Jun 12, 2018

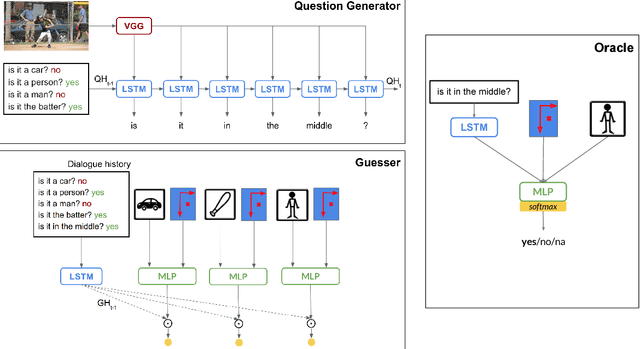

Our goal is to explore how the abilities brought in by a dialogue manager can be included in end-to-end visually grounded conversational agents. We make initial steps towards this general goal by augmenting a task-oriented visual dialogue model with a decision-making component that decides whether to ask a follow-up question to identify a target referent in an image, or to stop the conversation to make a guess. Our analyses show that adding a decision making component produces dialogues that are less repetitive and that include fewer unnecessary questions, thus potentially leading to more efficient and less unnatural interactions.