 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking what Matters: Effective and Robust Multilingual Realignment for Low-Resource Languages
Nov 09, 2025Realignment is a promising strategy to improve cross-lingual transfer in multilingual language models. However, empirical results are mixed and often unreliable, particularly for typologically distant or low-resource languages (LRLs) compared to English. Moreover, word realignment tools often rely on high-quality parallel data, which can be scarce or noisy for many LRLs. In this work, we conduct an extensive empirical study to investigate whether realignment truly benefits from using all available languages, or if strategically selected subsets can offer comparable or even improved cross-lingual transfer, and study the impact on LRLs. Our controlled experiments show that realignment can be particularly effective for LRLs and that using carefully selected, linguistically diverse subsets can match full multilingual alignment, and even outperform it for unseen LRLs. This indicates that effective realignment does not require exhaustive language coverage and can reduce data collection overhead, while remaining both efficient and robust when guided by informed language selection.
Simple Additions, Substantial Gains: Expanding Scripts, Languages, and Lineage Coverage in URIEL+
Oct 31, 2025



The URIEL+ linguistic knowledge base supports multilingual research by encoding languages through geographic, genetic, and typological vectors. However, data sparsity remains prevalent, in the form of missing feature types, incomplete language entries, and limited genealogical coverage. This limits the usefulness of URIEL+ in cross-lingual transfer, particularly for supporting low-resource languages. To address this sparsity, this paper extends URIEL+ with three contributions: introducing script vectors to represent writing system properties for 7,488 languages, integrating Glottolog to add 18,710 additional languages, and expanding lineage imputation for 26,449 languages by propagating typological and script features across genealogies. These additions reduce feature sparsity by 14% for script vectors, increase language coverage by up to 19,015 languages (1,007%), and improve imputation quality metrics by up to 33%. Our benchmark on cross-lingual transfer tasks (oriented around low-resource languages) shows occasionally divergent performance compared to URIEL+, with performance gains up to 6% in certain setups. Our advances make URIEL+ more complete and inclusive for multilingual research.
\textsc{CantoNLU}: A benchmark for Cantonese natural language understanding
Oct 23, 2025Cantonese, although spoken by millions, remains under-resourced due to policy and diglossia. To address this scarcity of evaluation frameworks for Cantonese, we introduce \textsc{\textbf{CantoNLU}}, a benchmark for Cantonese natural language understanding (NLU). This novel benchmark spans seven tasks covering syntax and semantics, including word sense disambiguation, linguistic acceptability judgment, language detection, natural language inference, sentiment analysis, part-of-speech tagging, and dependency parsing. In addition to the benchmark, we provide model baseline performance across a set of models: a Mandarin model without Cantonese training, two Cantonese-adapted models obtained by continual pre-training a Mandarin model on Cantonese text, and a monolingual Cantonese model trained from scratch. Results show that Cantonese-adapted models perform best overall, while monolingual models perform better on syntactic tasks. Mandarin models remain competitive in certain settings, indicating that direct transfer may be sufficient when Cantonese domain data is scarce. We release all datasets, code, and model weights to facilitate future research in Cantonese NLP.
Modality Matching Matters: Calibrating Language Distances for Cross-Lingual Transfer in URIEL+
Oct 22, 2025Existing linguistic knowledge bases such as URIEL+ provide valuable geographic, genetic and typological distances for cross-lingual transfer but suffer from two key limitations. One, their one-size-fits-all vector representations are ill-suited to the diverse structures of linguistic data, and two, they lack a principled method for aggregating these signals into a single, comprehensive score. In this paper, we address these gaps by introducing a framework for type-matched language distances. We propose novel, structure-aware representations for each distance type: speaker-weighted distributions for geography, hyperbolic embeddings for genealogy, and a latent variables model for typology. We unify these signals into a robust, task-agnostic composite distance. In selecting transfer languages, our representations and composite distances consistently improve performance across a wide range of NLP tasks, providing a more principled and effective toolkit for multilingual research.
Beyond Vanilla Fine-Tuning: Leveraging Multistage, Multilingual, and Domain-Specific Methods for Low-Resource Machine Translation
Mar 28, 2025



Fine-tuning multilingual sequence-to-sequence large language models (msLLMs) has shown promise in developing neural machine translation (NMT) systems for low-resource languages (LRLs). However, conventional single-stage fine-tuning methods struggle in extremely low-resource NMT settings, where training data is very limited. This paper contributes to artificial intelligence by proposing two approaches for adapting msLLMs in these challenging scenarios: (1) continual pre-training (CPT), where the msLLM is further trained with domain-specific monolingual data to compensate for the under-representation of LRLs, and (2) intermediate task transfer learning (ITTL), a method that fine-tunes the msLLM with both in-domain and out-of-domain parallel data to enhance its translation capabilities across various domains and tasks. As an application in engineering, these methods are implemented in NMT systems for Sinhala, Tamil, and English (six language pairs) in domain-specific, extremely low-resource settings (datasets containing fewer than 100,000 samples). Our experiments reveal that these approaches enhance translation performance by an average of +1.47 bilingual evaluation understudy (BLEU) score compared to the standard single-stage fine-tuning baseline across all translation directions. Additionally, a multi-model ensemble further improves performance by an additional BLEU score.
AlignFreeze: Navigating the Impact of Realignment on the Layers of Multilingual Models Across Diverse Languages
Feb 18, 2025Realignment techniques are often employed to enhance cross-lingual transfer in multilingual language models, still, they can sometimes degrade performance in languages that differ significantly from the fine-tuned source language. This paper introduces AlignFreeze, a method that freezes either the layers' lower half or upper half during realignment. Through controlled experiments on 4 tasks, 3 models, and in 35 languages, we find that realignment affects all the layers but can be the most detrimental to the lower ones. Freezing the lower layers can prevent performance degradation. Particularly, AlignFreeze improves Part-of-Speech (PoS) tagging performances in languages where full realignment fails: with XLM-R, it provides improvements of more than one standard deviation in accuracy in seven more languages than full realignment.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
URIEL+: Enhancing Linguistic Inclusion and Usability in a Typological and Multilingual Knowledge Base
Sep 27, 2024



URIEL is a knowledge base offering geographical, phylogenetic, and typological vector representations for 7970 languages. It includes distance measures between these vectors for 4005 languages, which are accessible via the lang2vec tool. Despite being frequently cited, URIEL is limited in terms of linguistic inclusion and overall usability. To tackle these challenges, we introduce URIEL+, an enhanced version of URIEL and lang2vec addressing these limitations. In addition to expanding typological feature coverage for 2898 languages, URIEL+ improves user experience with robust, customizable distance calculations to better suit the needs of the users. These upgrades also offer competitive performance on downstream tasks and provide distances that better align with linguistic distance studies.
ProxyLM: Predicting Language Model Performance on Multilingual Tasks via Proxy Models
Jun 14, 2024



Performance prediction is a method to estimate the performance of Language Models (LMs) on various Natural Language Processing (NLP) tasks, mitigating computational costs associated with model capacity and data for fine-tuning. Our paper introduces ProxyLM, a scalable framework for predicting LM performance using proxy models in multilingual tasks. These proxy models act as surrogates, approximating the performance of the LM of interest. By leveraging proxy models, ProxyLM significantly reduces computational overhead on task evaluations, achieving up to a 37.08x speedup compared to traditional methods, even with our smallest proxy models. Additionally, our methodology showcases adaptability to previously unseen languages in pre-trained LMs, outperforming the state-of-the-art performance by 1.89x as measured by root-mean-square error (RMSE). This framework streamlines model selection, enabling efficient deployment and iterative LM enhancements without extensive computational resources.
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024

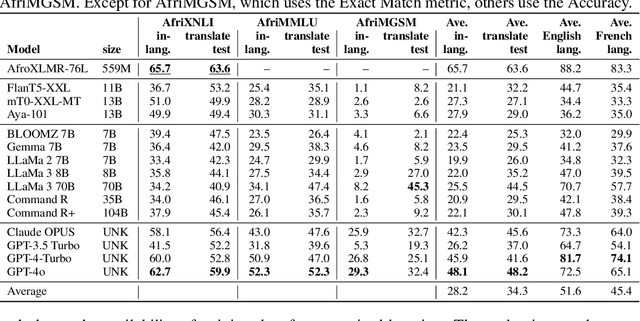
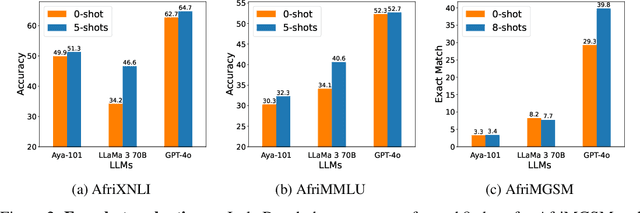
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.