 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Exploiting Domain-Specific Parallel Data on Multilingual Language Models for Low-resource Language Translation
Dec 27, 2024Neural Machine Translation (NMT) systems built on multilingual sequence-to-sequence Language Models (msLMs) fail to deliver expected results when the amount of parallel data for a language, as well as the language's representation in the model are limited. This restricts the capabilities of domain-specific NMT systems for low-resource languages (LRLs). As a solution, parallel data from auxiliary domains can be used either to fine-tune or to further pre-train the msLM. We present an evaluation of the effectiveness of these two techniques in the context of domain-specific LRL-NMT. We also explore the impact of domain divergence on NMT model performance. We recommend several strategies for utilizing auxiliary parallel data in building domain-specific NMT models for LRLs.
Learning Frequency-Aware Dynamic Transformers for All-In-One Image Restoration
Jun 30, 2024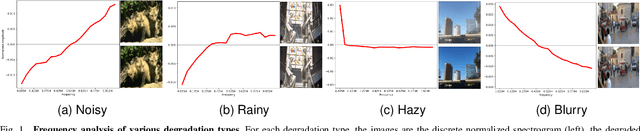
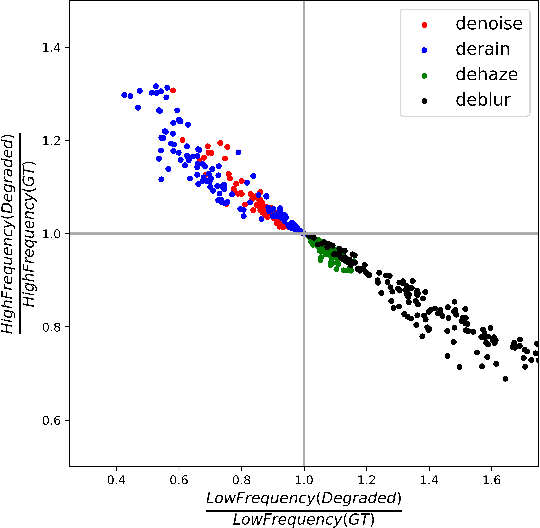
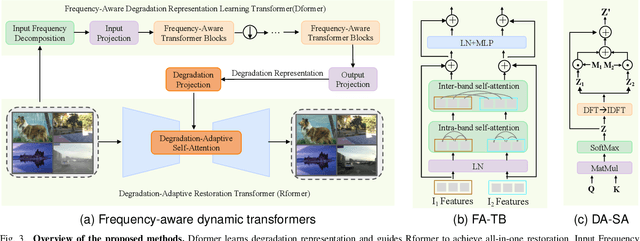

This work aims to tackle the all-in-one image restoration task, which seeks to handle multiple types of degradation with a single model. The primary challenge is to extract degradation representations from the input degraded images and use them to guide the model's adaptation to specific degradation types. Recognizing that various degradations affect image content differently across frequency bands, we propose a new all-in-one image restoration approach from a frequency perspective, leveraging advanced vision transformers. Our method consists of two main components: a frequency-aware Degradation prior learning transformer (Dformer) and a degradation-adaptive Restoration transformer (Rformer). The Dformer captures the essential characteristics of various degradations by decomposing inputs into different frequency components. By understanding how degradations affect these frequency components, the Dformer learns robust priors that effectively guide the restoration process. The Rformer then employs a degradation-adaptive self-attention module to selectively focus on the most affected frequency components, guided by the learned degradation representations. Extensive experimental results demonstrate that our approach outperforms the existing methods on four representative restoration tasks, including denoising, deraining, dehazing and deblurring. Additionally, our method offers benefits for handling spatially variant degradations and unseen degradation levels.
Densely Distilling Cumulative Knowledge for Continual Learning
May 16, 2024



Continual learning, involving sequential training on diverse tasks, often faces catastrophic forgetting. While knowledge distillation-based approaches exhibit notable success in preventing forgetting, we pinpoint a limitation in their ability to distill the cumulative knowledge of all the previous tasks. To remedy this, we propose Dense Knowledge Distillation (DKD). DKD uses a task pool to track the model's capabilities. It partitions the output logits of the model into dense groups, each corresponding to a task in the task pool. It then distills all tasks' knowledge using all groups. However, using all the groups can be computationally expensive, we also suggest random group selection in each optimization step. Moreover, we propose an adaptive weighting scheme, which balances the learning of new classes and the retention of old classes, based on the count and similarity of the classes. Our DKD outperforms recent state-of-the-art baselines across diverse benchmarks and scenarios. Empirical analysis underscores DKD's ability to enhance model stability, promote flatter minima for improved generalization, and remains robust across various memory budgets and task orders. Moreover, it seamlessly integrates with other CL methods to boost performance and proves versatile in offline scenarios like model compression.
Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Apr 05, 2024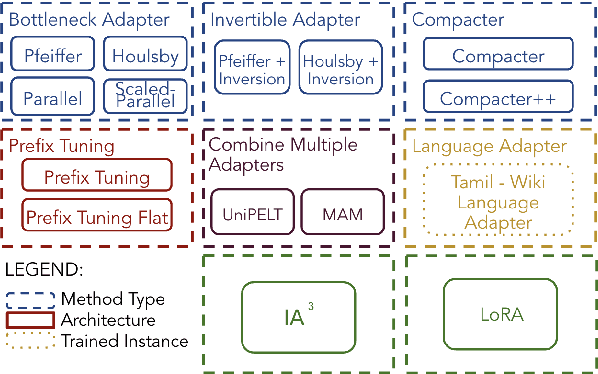


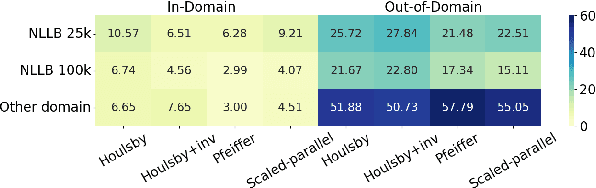
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
ProphNet: Efficient Agent-Centric Motion Forecasting with Anchor-Informed Proposals
Mar 21, 2023Motion forecasting is a key module in an autonomous driving system. Due to the heterogeneous nature of multi-sourced input, multimodality in agent behavior, and low latency required by onboard deployment, this task is notoriously challenging. To cope with these difficulties, this paper proposes a novel agent-centric model with anchor-informed proposals for efficient multimodal motion prediction. We design a modality-agnostic strategy to concisely encode the complex input in a unified manner. We generate diverse proposals, fused with anchors bearing goal-oriented scene context, to induce multimodal prediction that covers a wide range of future trajectories. Our network architecture is highly uniform and succinct, leading to an efficient model amenable for real-world driving deployment. Experiments reveal that our agent-centric network compares favorably with the state-of-the-art methods in prediction accuracy, while achieving scene-centric level inference latency.
QML for Argoverse 2 Motion Forecasting Challenge
Jul 13, 2022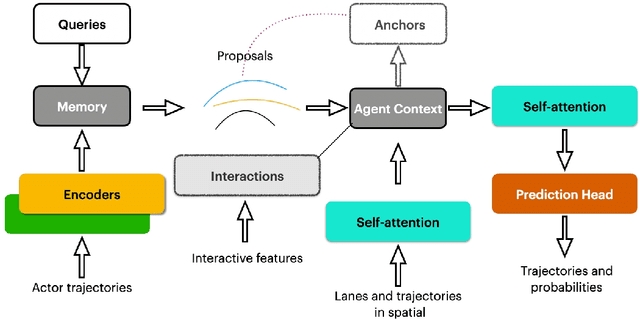

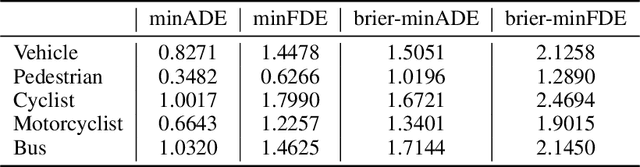

To safely navigate in various complex traffic scenarios, autonomous driving systems are generally equipped with a motion forecasting module to provide vital information for the downstream planning module. For the real-world onboard applications, both accuracy and latency of a motion forecasting model are essential. In this report, we present an effective and efficient solution, which ranks the 3rd place in the Argoverse 2 Motion Forecasting Challenge 2022.
Pedestrian Trajectory Prediction via Spatial Interaction Transformer Network
Dec 13, 2021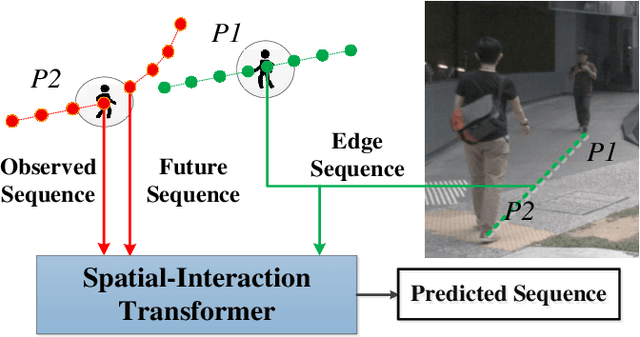
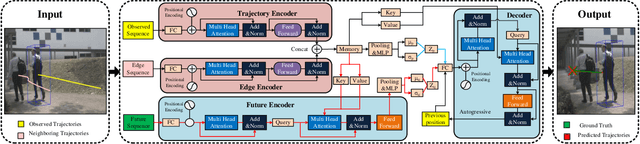
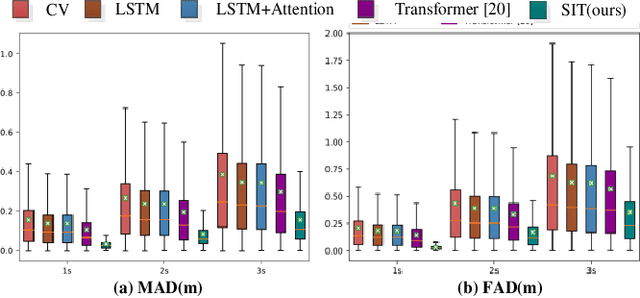
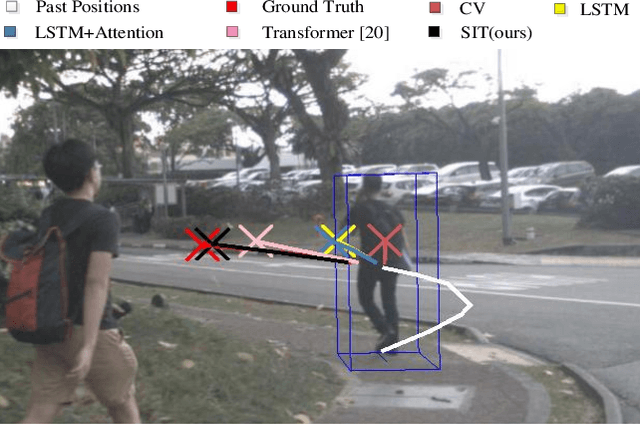
As a core technology of the autonomous driving system, pedestrian trajectory prediction can significantly enhance the function of active vehicle safety and reduce road traffic injuries. In traffic scenes, when encountering with oncoming people, pedestrians may make sudden turns or stop immediately, which often leads to complicated trajectories. To predict such unpredictable trajectories, we can gain insights into the interaction between pedestrians. In this paper, we present a novel generative method named Spatial Interaction Transformer (SIT), which learns the spatio-temporal correlation of pedestrian trajectories through attention mechanisms. Furthermore, we introduce the conditional variational autoencoder (CVAE) framework to model the future latent motion states of pedestrians. In particular, the experiments based on large-scale trafc dataset nuScenes [2] show that SIT has an outstanding performance than state-of-the-art (SOTA) methods. Experimental evaluation on the challenging ETH and UCY datasets conrms the robustness of our proposed model