 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorMix: Modular Authorship Style Transfer via Layer-wise Adapter Mixing
Mar 24, 2026The task of authorship style transfer involves rewriting text in the style of a target author while preserving the meaning of the original text. Existing style transfer methods train a single model on large corpora to model all target styles at once: this high-cost approach offers limited flexibility for target-specific adaptation, and often sacrifices meaning preservation for style transfer. In this paper, we propose AuthorMix: a lightweight, modular, and interpretable style transfer framework. We train individual, style-specific LoRA adapters on a small set of high-resource authors, allowing the rapid training of specialized adaptation models for each new target via learned, layer-wise adapter mixing, using only a handful of target style training examples. AuthorMix outperforms existing, SoTA style-transfer baselines -- as well as GPT-5.1 -- for low-resource targets, achieving the highest overall score and substantially improving meaning preservation.
Beyond Vanilla Fine-Tuning: Leveraging Multistage, Multilingual, and Domain-Specific Methods for Low-Resource Machine Translation
Mar 28, 2025



Fine-tuning multilingual sequence-to-sequence large language models (msLLMs) has shown promise in developing neural machine translation (NMT) systems for low-resource languages (LRLs). However, conventional single-stage fine-tuning methods struggle in extremely low-resource NMT settings, where training data is very limited. This paper contributes to artificial intelligence by proposing two approaches for adapting msLLMs in these challenging scenarios: (1) continual pre-training (CPT), where the msLLM is further trained with domain-specific monolingual data to compensate for the under-representation of LRLs, and (2) intermediate task transfer learning (ITTL), a method that fine-tunes the msLLM with both in-domain and out-of-domain parallel data to enhance its translation capabilities across various domains and tasks. As an application in engineering, these methods are implemented in NMT systems for Sinhala, Tamil, and English (six language pairs) in domain-specific, extremely low-resource settings (datasets containing fewer than 100,000 samples). Our experiments reveal that these approaches enhance translation performance by an average of +1.47 bilingual evaluation understudy (BLEU) score compared to the standard single-stage fine-tuning baseline across all translation directions. Additionally, a multi-model ensemble further improves performance by an additional BLEU score.
Fine-grained Controllable Text Generation through In-context Learning with Feedback
Jun 17, 2024We present a method for rewriting an input sentence to match specific values of nontrivial linguistic features, such as dependency depth. In contrast to earlier work, our method uses in-context learning rather than finetuning, making it applicable in use cases where data is sparse. We show that our model performs accurate rewrites and matches the state of the art on rewriting sentences to a specified school grade level.
Unlocking Parameter-Efficient Fine-Tuning for Low-Resource Language Translation
Apr 05, 2024


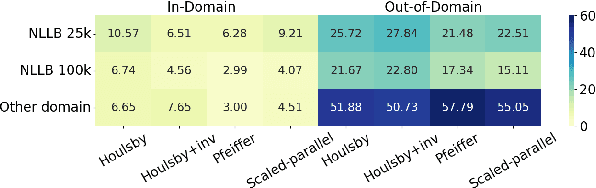
Parameter-efficient fine-tuning (PEFT) methods are increasingly vital in adapting large-scale pre-trained language models for diverse tasks, offering a balance between adaptability and computational efficiency. They are important in Low-Resource Language (LRL) Neural Machine Translation (NMT) to enhance translation accuracy with minimal resources. However, their practical effectiveness varies significantly across different languages. We conducted comprehensive empirical experiments with varying LRL domains and sizes to evaluate the performance of 8 PEFT methods with in total of 15 architectures using the SacreBLEU score. We showed that 6 PEFT architectures outperform the baseline for both in-domain and out-domain tests and the Houlsby+Inversion adapter has the best performance overall, proving the effectiveness of PEFT methods.
Leveraging Auxiliary Domain Parallel Data in Intermediate Task Fine-tuning for Low-resource Translation
Jun 02, 2023NMT systems trained on Pre-trained Multilingual Sequence-Sequence (PMSS) models flounder when sufficient amounts of parallel data is not available for fine-tuning. This specifically holds for languages missing/under-represented in these models. The problem gets aggravated when the data comes from different domains. In this paper, we show that intermediate-task fine-tuning (ITFT) of PMSS models is extremely beneficial for domain-specific NMT, especially when target domain data is limited/unavailable and the considered languages are missing or under-represented in the PMSS model. We quantify the domain-specific results variations using a domain-divergence test, and show that ITFT can mitigate the impact of domain divergence to some extent.
Pre-Trained Multilingual Sequence-to-Sequence Models: A Hope for Low-Resource Language Translation?
Apr 09, 2022



What can pre-trained multilingual sequence-to-sequence models like mBART contribute to translating low-resource languages? We conduct a thorough empirical experiment in 10 languages to ascertain this, considering five factors: (1) the amount of fine-tuning data, (2) the noise in the fine-tuning data, (3) the amount of pre-training data in the model, (4) the impact of domain mismatch, and (5) language typology. In addition to yielding several heuristics, the experiments form a framework for evaluating the data sensitivities of machine translation systems. While mBART is robust to domain differences, its translations for unseen and typologically distant languages remain below 3.0 BLEU. In answer to our title's question, mBART is not a low-resource panacea; we therefore encourage shifting the emphasis from new models to new data.